The ARM Diaries, Part 2: Understanding the Cortex A12
by Anand Lal Shimpi on July 17, 2013 12:30 PM EST- Posted in
- CPUs
- Arm
- SoCs
- Cortex A12
Introduction to Cortex A12 & The Front End
At a high level ARM’s Cortex A12 is a dual-issue, out-of-order microarchitecture with integrated L2 cache and multi-core capable.
The Cortex A12 team all previously worked on Cortex A9. ARM views the resulting design as not being a derivative of Cortex A9, but clearly inspired by it. At a high level, Cortex A12 features a 10 - 12 stage integer pipeline - a lengthening of Cortex A9’s 8 - 11 stage pipeline. The architecture is still 2-wide out-of-order, but unlike Cortex A9 the new tweener is fully out of order including load/store (within reason) and FP/NEON.

Cortex A12 retains feature and ISA compatibility with ARM’s Cortex A7 and A15, making it the new middle child in the updated microprocessor family. All three parts support 40-bit physical addressing, the same 128-bit AXI4 bus interface and the same 32-bit ARM-v7A instruction set (NEON is standard on Cortex A12). The Cortex A12 is so compatible with A7 and A15 that it’ll eventually be offered in a big.LITTLE configuration with a cluster of Cortex A7 cores (initial versions lack the coherent interface required for big.LITTLE).
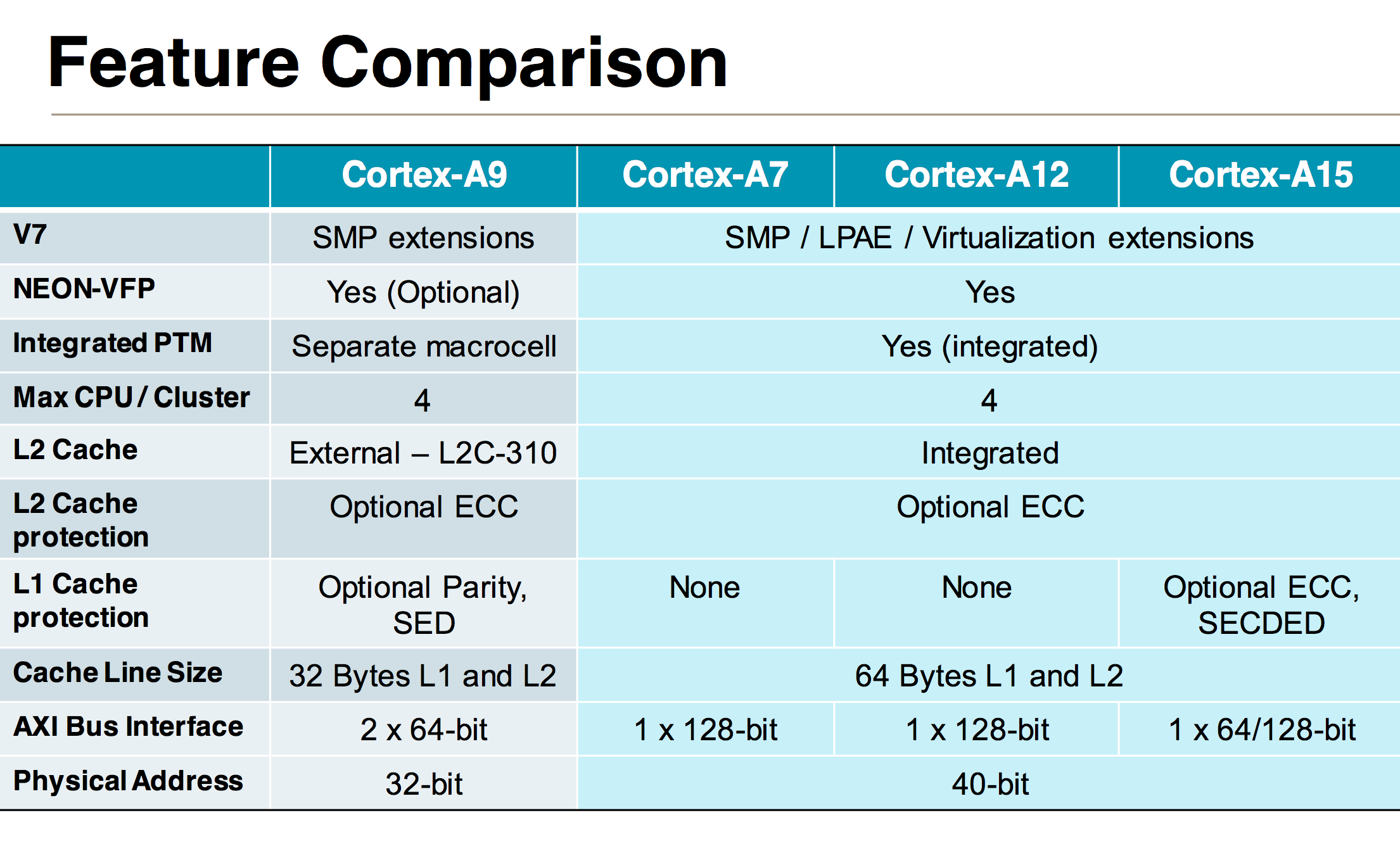
In the Cortex A9, ARM had a decoupled L2 cache that required some OS awareness. The Cortex A12 design moves to a fully integrated L2, similar to the A7/A15. The L2 cache operates on its own voltage and frequency planes, although the latter can be in sync with the CPU cores if desired. The L2 cache is shared among up to four cores. Larger core count configurations are supported through replication of quad-core clusters.
The L1 instruction cache is 4-way set associative and configurable in size (32KB or 64KB). The cache line size in Cortex A12 was increased to 64 bytes (from 32B in Cortex A9) to better align with DDR memory controllers as well as the Cortex A7 and A15 designs. Similar to Cortex A9 there’s a fully associative instruction micro TLB and unified main TLB, although I’m not sure if/how the sizes of those two structures have changed.

The branch predictor was significantly improved over Cortex A9. Apparently in the design of the Cortex A12, ARM underestimated its overall performance and ended up speccing it out with too weak of a branch predictor. About three months ago ARM realized its mistake and was left with the difficult situation of either shipping a less efficient design, or quickly finding a suitable branch predictor. The Cortex A12 team went through the company looking for a designed predictor it could use, eventually finding one in the Cortex A53. The A53’s predictor got pulled into the Cortex A12 and with some minor modifications will be what the design ships with. Improved branch prediction obviously improves power efficiency as well as performance.









65 Comments
View All Comments
Krysto - Saturday, July 20, 2013 - link
The difference is those ARM chips do take full advantage of the maximum core speed. Saying you start a web page - any web page. It WILL activate the maximum clock speed - whereas the Turbo-Boost in Atom doesn't activate all the time.If we're talking about receiving notifications and such, then obviously the ARM processors won't go to 2 Ghz either, but that's not really what we're talking about here, is it? We're talking about what happens when you're doing normal heavy stuff (web browsing, apps, games).
jeffkibuule - Monday, July 22, 2013 - link
That's the problem I have with performance benchmarks on cell phones. At some point thermal throttling kicks in because you're draining the battery a ton running your CPUs at full tilt. IPC improvements will be felt far more than clock speed ramping. If you ever look at CPU-Z on Android, you'll notice that a Snapdragon 600 with 4 cores clocked at 1.7Ghz tries its hardest to downclock to 1 core at 384Mhz. Even just scrolling up and down the monitoring screen pumps up the CPU speed to 1134Mhz and turns on a second core as well. Peak performance is nice, but ideally should rarely be utilized.Krysto - Saturday, July 20, 2013 - link
No, I meant it's a problem because Atom chips look like they are "competitive" in benchmarks, when in reality they have HALF the performance. That's what I was saying. It's a problem for US, not Intel. Intel wins by being misleading.felixyang - Thursday, July 18, 2013 - link
intel didn't mislead you. In SLM's review, they have very clear description about turbo. Copied here.Previous Atom based mobile SoCs had a very crude version of Intel’s Turbo Boost. The CPU would expose all of its available P-states to the OS and as it became thermally limited, Intel would clamp the max P-state it would expose to the OS. Everything was OS-driven and previous designs weren’t able to capitalize on unused thermal budget elsewhere in the SoC to drive up frequency in active parts of chip. ........ this is also how a lot of the present day ARM architectures work as well. At best, they vary what operating states they expose to the OS and clamp max frequency depending on thermals.
opwernby - Thursday, July 18, 2013 - link
That's not cheating: it's what compilers are supposed to do. For example, if you write, "for (i=0; i<1000; i++);" a good optimizing compiler will analyze the loop, realize that it does nothing, resolve it to "i=1000;" and compile that. I believe the first use of this type of aggressive compiler technology was seen in Sun's C compiler for whatever version of Solaris it was that ran on the Sparc chips back in the '80s. The fact that the ARM compilers didn't do this speaks more about the expected performance of the chipset than anything else: you can build hardware to be as fast as you like, but if the compilers can't keep up, you might as well be running your code on a Commodore Pet.opwernby - Thursday, July 18, 2013 - link
Speaking of the Sun thing: I distinctly remember that the then-current version of the Sun "pizza-box"-style workstation appeared in benchmarks to be 100 times faster than the IBM PC-RT (another RISC architecture competing with Sun's platform) even though, on paper, the PC-RT was running on faster hardware: analysis of the benchmarks' compiled code revealed that Sun's compiler had effectively edited out the loops as I described above. Result: the PC-RT died off very quickly.FunBunny2 - Friday, July 19, 2013 - link
The PC-RT didn't last long, but the processor (in its children) lives on as the RS-6000/PPC/iSeries/ZWilco1 - Thursday, July 18, 2013 - link
It's certainly cheating, if you followed the whole thing it was not just about ICC optimizing much of the benchmark away. The particular optimization was added recently to ICC - it was a lot more complex than an empty loop, it only optimized a very specific loop by a huge factor (so specific that if you compiled all open source code it would likely only apply to the benchmark and nothing else). For some odd reason AnTuTu then secretly switched to that ICC version despite ICC not being a standard Android compiler. Finally it turned out the settings for ARM were non-optimal, using an older GCC version with pretty much all loop optimizations disabled. Intel and ABI research then started making false claims on how fast Atom was compared to Galaxy S4 based on the parts of AnTuTu that were broken (without actually mentioning AnTuTu).Giving one side such a huge unfair advantage is called cheating. As a result AnTuTu will now stop using ICC.
jwcalla - Thursday, July 18, 2013 - link
This is why benchmarks have to be taken with a healthy dose of skepticism.First, if the benchmark program isn't open source, right off the bat it's worthless. If you can't see the code, you can't trust it.
Second, if the program isn't compiled with the same compiler and the same compiler options, the results are crap. You're not getting a valid comparison of the hardware itself.
It's kind of ridiculous seeing many of the journalists out there who took this sensational headline and ran with it without even questioning its legitimacy.
Wilco1 - Wednesday, July 17, 2013 - link
The IPC comparison for integer code goes like:Silverthorne < A7 < A9 < A9R4 < Silvermont < A12 < Bobcat < A15 < Jaguar
This is based on fair comparisons using Geekbench and so doesn't reflect what some marketing departments claim or what cheated benchmarks (ie. AnTuTu) appear to show.