Intel's Haswell - An HTPC Perspective: Media Playback, 4K and QuickSync Evaluated
by Ganesh T S on June 2, 2013 8:15 PM ESTDecoding and Rendering Benchmarks
Our decoding and rendering benchmarks consists of standardized test clips (varying codecs, resolutions and frame rates) being played back through MPC-HC. GPU usage is tracked through GPU-Z logs and power consumption at the wall is also reported. The former provides hints on whether frame drops could occur, while the latter is an indicator of the efficiency of the platform for the most common HTPC task - video playback.
Enhanced Video Renderer (EVR) / Enhanced Video Renderer - Custom Presenter (EVR-CP)
The Enhanced Video Renderer is the default renderer made available by Windows 8. It is a lean renderer in terms of usage of system resources since most of the aspects are offloaded to the GPU drivers directly. EVR is mostly used in conjunction with native DXVA2 decoding. The GPU is not taxed much by the EVR despite hardware decoding also taking place. Deinterlacing and other post processing aspects were left at the default settings in the Intel HD Graphics Control Panel (and these are applicable when EVR is chosen as the renderer). EVR-CP is the default renderer used by MPC-HC. It is usually used in conjunction with MPC-HC's video decoders, some of which are DXVA-enabled. However, for our tests, we used the DXVA2 mode provided by the LAV Video Decoder. In addition to DXVA2 Native, we also used the QuickSync decoder developed by Eric Gur (an Intel applications engineer) and made available to the open source community. It makes use of the specialized decoder blocks available as part of the QuickSync engine in the GPU.
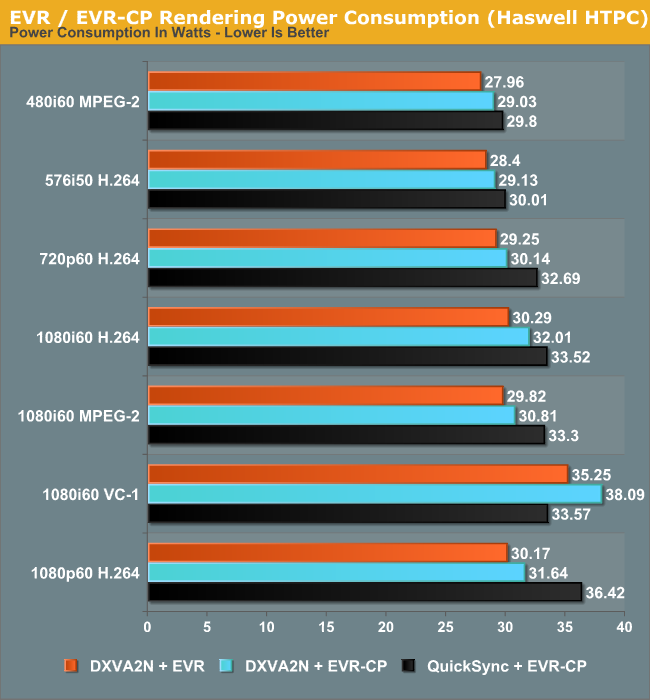
Power consumption shows a tremendous decrease across all streams. Admittedly, the passive Ivy Bridge HTPC uses a 55W TDP Core i3-3225, but, as we will see later, the power consumption at full load for the Haswell build is very close to that of the Core i3-3225 build despite the lower TDP of the Core i7-4765T.
In general, using the QuickSync decoder results in a higher power consumption because the decoded frames are copied back to the DRAM before being sent to the renderer. Using native DXVA decoding, the frames are directly passed to the renderer without the copy-back step. The odd-man out in the power numbers is the interlaced VC-1 clip, where QuickSync decoding is more efficient compared to 'native DXVA2'. This is because there is currently no support in the open source native DXVA2 decoders for interlaced VC-1 on Intel GPUs, and hence, it is done in software. On the other hand, the QuickSync decoder is able to handle it with the VC-1 bitstream decoder in the GPU.
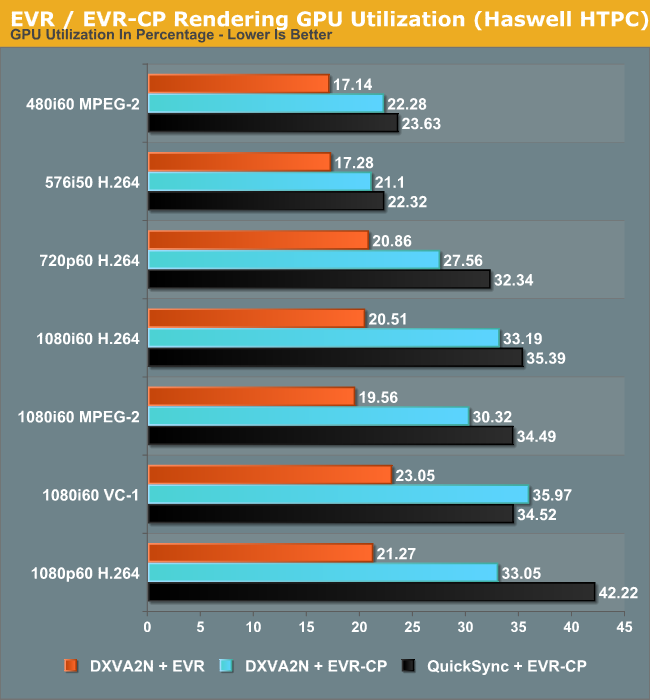
The GPU utilization numbers follow a similar track to the power consumption numbers. EVR is very lean on the GPU, as discussed earlier. The utilization numbers provide proof of the same. QuickSync appears to stress the GPU more, possibly because of the copy-back step for the decoded frames.
madVR
Videophiles often prefer madVR as their renderer because of the choice of scaling algorithms available as well as myriad other features. In our recent Ivy Bridge HTPC review, we found that with DDR3-1600 DRAM, it was straightforward to get madVR working with the default scaling algorithms for all materials 1080p60 or lesser. In the meanwhile, Mathias Rauen (developer of madVR) has developed more features. In order to alleviate the ringing artifacts introduced by the Lanczos algorithm, an option to enable an anti-ringing filter was introduced. A more intensive scaling algorithm (Jinc) was also added. Unfortunately, enabling either the anti-ringing filter with Lanczos or choosing any variant of Jinc resulted in a lot of dropped frames. Haswell's HD4600 is simply not powerful enough for these madVR features.
It is not possible to use native DXVA2 decoding with madVR because the decoded frames are not made available to an external renderer directly. (Update: It is possible to use DXVA2 Native with madVR since v0.85. Future HTPC articles will carry updated benchmarks) To work around this issue, LAV Video Decoder offers three options. The first option involves using software decoding. The second option is to use either QuickSync or DXVA2 Copy-Back. In either case, the decoded frames are brought back to the system memory for madVR to take over. One of the interesting features to be integrated into the recent madVR releases is the option to perform DXVA scaling. This is particularly interesting for HTPCs running Intel GPUs because the Intel HD Graphics engine uses dedicated hardware to implement support for the DXVA scaling API calls. AMD and NVIDIA apparently implement those calls using pixel shaders. In order to obtain a frame of reference, we repeated our benchmark process using DXVA2 scaling for both luma and chroma instead of the default settings.
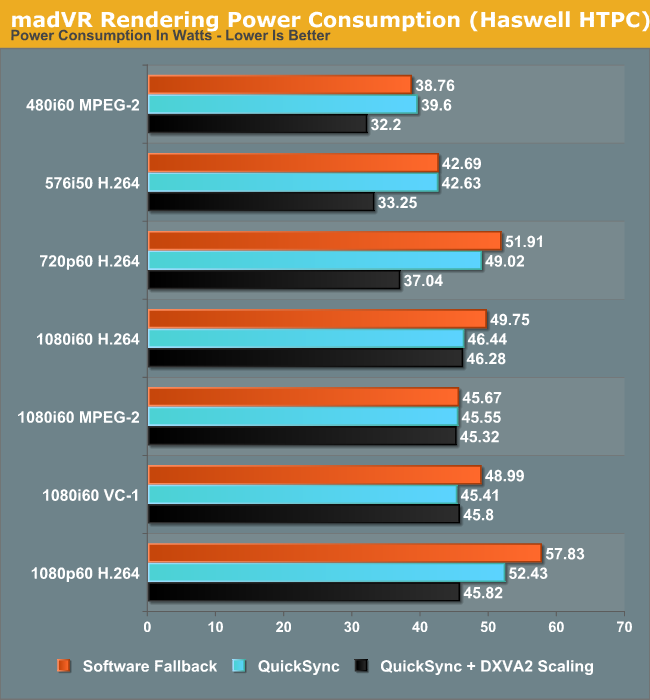
One of the interesting aspects to note here is the fact that the power consumption numbers show a much larger shift towards the lower end when using DXVA2 scaling. This points to more power efficient updates in the GPU video post processing logic.
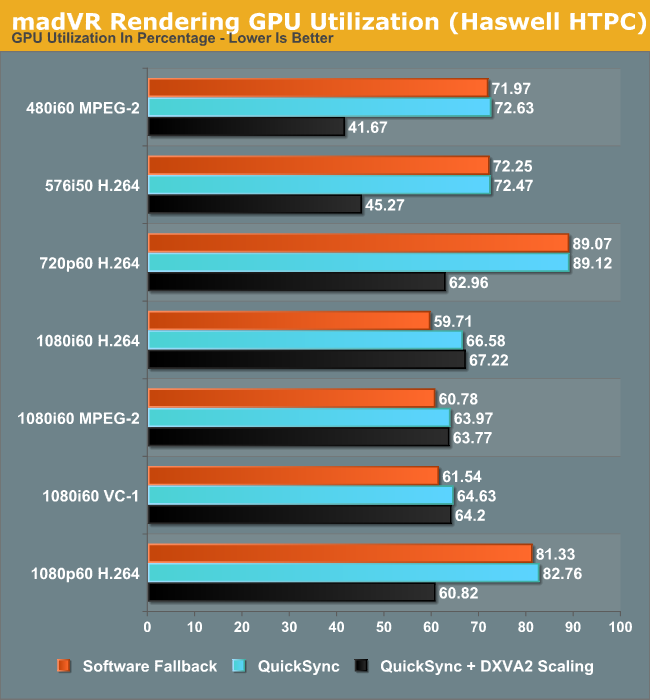
DXVA scaling results in much lower GPU usage for SD material in particular with a corresponding decrease in average power consumption too. Users with Intel GPUs can continue to enjoy other madVR features while giving up on the choice of a wide variety of scaling algorithms.








95 Comments
View All Comments
StardogChampion - Monday, June 3, 2013 - link
I am wondering about this comment as well. Everything I've read seemed to indicate it would be available in mini-ITX form for building AIOs (so likely thin mini-ITX). Haswell will be a big disappointment without availability of the BGA packages in mini-ITX form.Sivar - Monday, June 3, 2013 - link
Thank you for the article.Note that x264 is a specific software encoder, not a type of video or a thing that can be accelerated ("While full x264 acceleration using QuickSync...")
H.264 is the video standard.
Also note that x264, the CPU-based encoding software, does not need to run in 2-pass mode to get great quality. 2-pass mode is ONLY if you want a specific file size regardless of quality. If you want a specific quality, you use quality mode. --CRF23, for example, returns small (though variable depending on content) file size and good quality.
ganeshts - Monday, June 3, 2013 - link
Sivar,I did specifically want to mention full x264 acceleration using QuickSync -- That is because x264 is the H.264 encoder of choice for many users. The most beneficial addition to the CPU would be the ability to get hardware acceleration when using x264 with ANY set of options. That is simply not going to be possible with QuickSync (or, for that matter, any hardware-based encoder).
Yes, agreed about the mistaken mention of 2-pass for improved quality. I will update it shortly.
Spawne32 - Monday, June 3, 2013 - link
People always fail to realize what key element in every one of these releases, how big the enthusiast market truly is. All of us posting here on this comment section regarding this review are a small fraction of the overall market intel targets, this is part of the reason AMD suffers so tragically with their current lineup. Power consumption and price are the two biggest factors in a regular consumers mind when purchasing a PC, be it laptop or desktop. Performance numbers rarely play a factor. I don't know what AMD is doing over there but I long for a day when AMD can actually challenge intel and drive prices down even further, because these 230-400 dollar starting prices for "mainstream" intel processors proves once again why I refuse to invest in them regardless of performance. The marginal increase in speed in my day to day activities does not warrant the price being paid for something that is obsolete in 1-2 years. AMD's highest priced processor right now is 179.99, its comparable intel counterpart in haswell....349.99, you do the math.bji - Monday, June 3, 2013 - link
Either the increases in speed with each successive generation are great enough to render previous generations obsolete, or the increases in speed with each successive generation are small enough that the previous generation is not rendered obsolete. You can't have it both ways just to try to make Intel look bad, sorry.I don't know what margin Intel is making on these parts - do you? Remember that they are sinking large R & D and transistor budgets into these minor speed increases, and at the same time sinking lots of money into developing the next generation of process technology. If $300 is not worth it to you, don't buy the part; Intel won't be able to sustain their R & D budgets if nobody buys the results.
Deuge - Monday, June 3, 2013 - link
If one of the GT3 or GT3e parts comes out in a refreshed NUC, id love to see a review of it from an HTPC perspective. Very interested to hear if it can handle Lanzcos + AR or Jinc.dbcoopernz - Monday, June 3, 2013 - link
Is the inability to use LAV with DXVA-native for madVR an Intel limitation? The devs of both the LAV filters and madVR have told me (on the doom9 forum) that DXVA-native is fine for madVR on AMD GPU's.BMNify - Monday, June 3, 2013 - link
DXVA native DOES work with AMD using LAV filters and MadVR... I'm using it as I type (watching MotoGP)ganeshts - Monday, June 3, 2013 - link
It also works with the Haswell piece. I will update the article ASAP.BMNify - Monday, June 3, 2013 - link
APU is the go to for HTPC builders. And stop with the power this and thermals that... undervolt it, toss in a Pico PSU, suspend to memory when not in use and enjoy. Take the hundreds saved and buy a Kabini or two as clients.If we're talking balls to the wall processing might, absolutely, lets talk Intel but not for a simple HTPC.