Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Earlier this year I wrote a review of a dual processor Sandy Bridge-EP system from the point of view of the non-CS trained coder in a research group, and whether the limited knowledge of advanced processor commands (beyond basic C++ with OpenMP) was a hindrance to dual processor systems on some simple grid solvers/Brownian motion simulation. As part of the feedback to the review, I was asked by several readers using the older Westmere-EP platform doing similar types of calculations if it was worth pushing their research budget for a move from Westmere-EP to high-end Sandy Bridge-E, and whether the jump in cores/IPC would cost effective in those simulation scenarios. Thankfully Gigabyte was on hand to supply their GA-7TESM DP socket 1366 Xeon board and a pair of X5690s in order to run the comparison.

Comparing Westmere-EP to Sandy Bridge-EP
Johan’s words say it best, from his article on the E5-2600 in March 2012:
Compared to its predecessor, the Xeon X5600, the Xeon E5-2600 offers a number of improvements:
A completely improved core, as described here in Anand's article. For example, the µop cache lowers the pressure on the decoding stages and lowers power consumption, killing two birds with one stone. Other core improvements include an improved branch prediction unit and a more efficient Out-of-Order backend with larger buffers.
A vastly improved Turbo 2.0. The CPU can briefly go beyond the TDP limits, and when returning to the TDP limit, the CPU can sustain higher "steady-state" clockspeed. According to Intel, enabling turbo allows the Xeon E5 to perform 14% better in the SAP S&D 2 tier test. This compares well with the Turbo inside the Xeon 5600 which could only boost performance by 4% in the SAP benchmark.
Support for AVX Instructions combined with doubling the load bandwidth should allow the Xeon to double the peak floating point performance compared to the Xeon "Westmere" 5600.
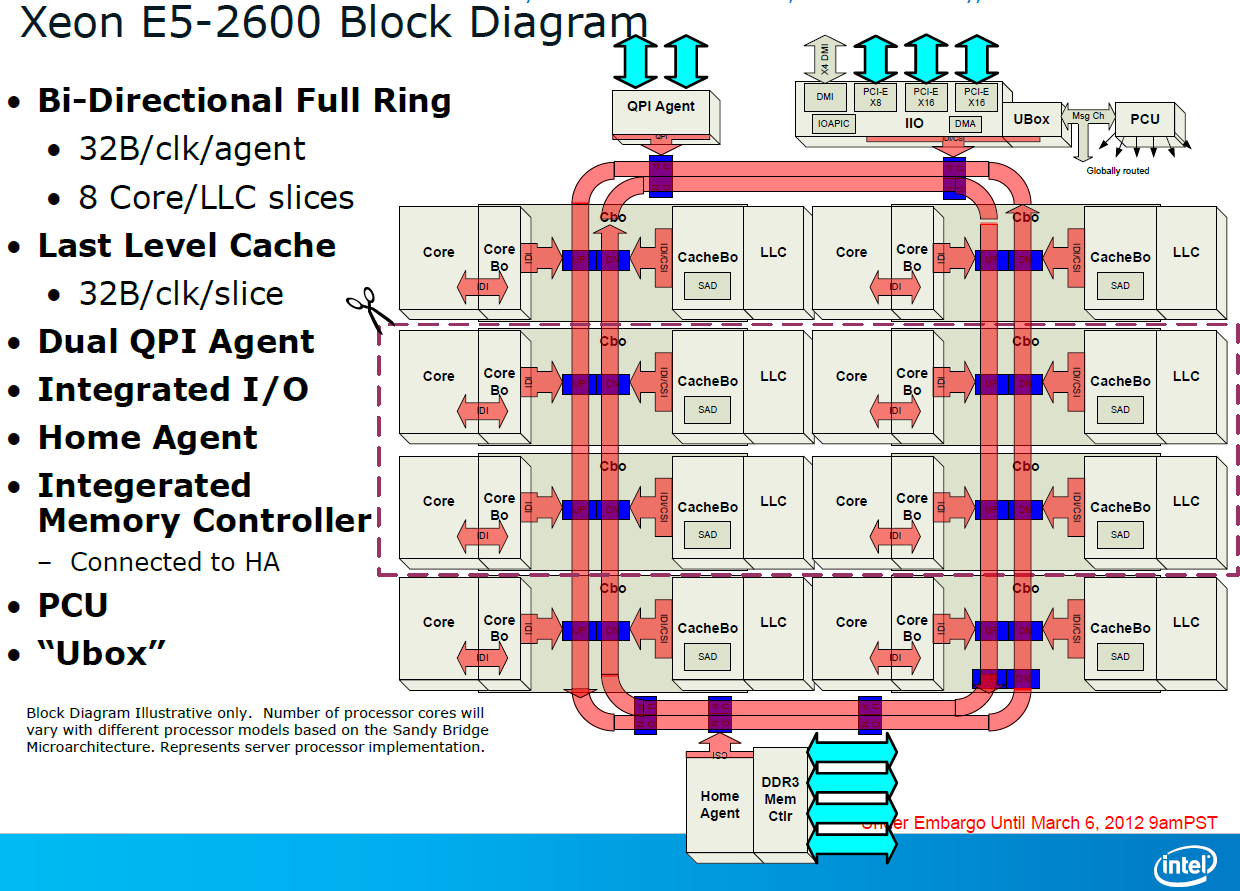
A bi-directional 32 byte ring interconnect that connects the 8 cores, the L3-cache, the QPI agent and the integrated memory controller. The ring replaces the individual wires from each core to the L3-cache. One of the advantages is that the wiring to the L3-cache can be simplified and it is easier to make the bandwidth scale with the number of cores. The disadvantage is that the latency is variable: it depends on how many hops a certain piece of data inside the L3-cache must cross before ends up at the right core.
A faster QPI: revision 1.1, which delivers up to 8 GT/s instead of 6.4 GT/s (Westmere).
Lower latency to PCI-e devices. Intel integrated a PCIe 3.0 I/O subsystem inside the die which sits on the same bi-directional 32 bit ring as the cores. PCIe 3.0 runs at 8 GT/s (PCIe 2.0: 5 GT/s), but the encoding has less overhead. As a result, PCIe 3.0 can deliver up to 1 GB full duplex per second per lane, which is twice as much as PCIe 2.0.
Removing the I/O lowered PCIe latency by 25% on average according to Intel. If you only access the local memory, Intel measured 32% lower read latency.
The access latency to PCIe I/O devices is not only significantly lower, but Intel's Data Direct I/O Technology allows the PCIe NICs to read and write directly to the L3-cache instead of to the main memory. In extremely bandwidth constrained situations (using 4 Infiniband controllers or similar), this lowers power consumption and reduces latency by another 18%, which is a boon to HPC users with 10G Ethernet or Infiniband NICs.
The new Xeon also supports faster DDR3-1600, up to 2 DIMMs per channel that can run at 1600 MHz.
Ian’s Analysis
In my line of computational chemistry, several E5-2600 characteristics would be very important to throughput:
- The improved core and µop cache should boost IPC through the roof with calculations that can take advantage, especially advanced trigonometric functions.
- The increase in L3 cache would reduce stress on jumps out to main memory for values, although the improved memory bandwidth would also help in this regard.
- More cores are always welcome – Turbo 2.0 would help with pre-release code testing, which often occurs in debug / single thread mode.
- An increase of memory limits would help various simulation scenarios, as well as aid having VMs of different environments.
- The move up to PCIe 3.0 helps any GPGPU simulation that requires lots of memory transfers back and forth across the bus (matrix solving), as long as the GPU supports PCIe 3.0 (K10, K20X, FirePro, not Xeon Phi which uses PCIe 2.0).
We all know the E5-2600 series is faster (one reader in response to the previous review had seen slowdown in parts of his code on E5-2600), but the question is always around “how much?”.
On paper, Johan’s article showed us the specifications side by side (along with Opteron counterparts):
|
Xeon E5-2600 Sandy Bridge-EP |
Opteron 6200 Interlagos |
Opteron 6100 Magny-Cours |
Xeon 5600 Westmere |
|
|
Cores/Threads Modules/Threads |
8/16 | 12/12 | 6/12 | |
| 8/16 | ||||
| L1 Instruction |
8x 32KB 4-way |
8x 64KB 2-way |
12x 64KB 2-way |
6x 32KB 4-way |
| L1 Data |
8x 32KB 8-way |
16x 16KB 4-way |
12x 64KB 2-way |
6x 32KB 8-way |
| L2 Cache | 8x 256 KB | 4x 2MB | 12x 512KB | 6x 256KB |
| L3 Cache | 20 MB | 2x 8MB | 2x 6MB | 12 MB |
|
Mem Bandwidth (Per Socket) |
51.2 GB/s | 51.2 GB/s | 42.6 GB/s | 32 GB/s |
| IMC Clock Speed | On Die | 2 GHz | 1.8 GHz | 2 GHz |
| Interconnect |
2x QPI 2.0 8 GT/s |
4x HT 3.1 6.4 GT/s |
4x HT 3.1 6.4 GT/s |
2x QPI 4.8-6.4 GT/s |
| Transistors | 2.26 B | 2x 1.2 B | 2x 0.9 B | 1.17 B |
| Die Size mm2 | 416 | 2x 315 | 2x 346 | 248 |
As well as the subsequent pricing difference:
| Intel vs. Intel 2-socket SKU Comparison | |||||||||
|
Xeon 5600 |
Cores/ Threads |
TDP |
Clock (GHz) |
Price |
Xeon E-5 |
Cores/ Threads |
TDP |
Clock (GHz) |
Price |
| High Performance | High Performance | ||||||||
| 2690 | 8/16 | 135W | 2.9/3.3/3.8 | $2057 | |||||
| X5690 | 6/12 | 130W | 3.46/3.6/3.73 | $1663 | 2680 | 8/16 | 130W | 2.7/3.1/3.5 | $1723 |
| 2670 | 8/16 | 115W | 2.6/3/3.3 | $1552 | |||||
| 2665 | 8/16 | 115W | 2.4/2.8/3.1 | $1440 | |||||
| X5675 | 6/12 | 95W | 3.06/3.33/3.46 | $1440 | |||||
| X5660 | 6/12 | 95W | 2.8/3.06/3.2 | $1219 | 2660 | 8/16 | 95W | 2.2/2.6/3.0 | $1329 |
| X5650 | 6/12 | 95W | 2.66/2.93/3.06 | $996 | 2650 | 8/16 | 95W | 2/2.4/2.8 | $1107 |
| Midrange | Midrange | ||||||||
| E5649 | 6/12 | 80W | 2.53/2.66/2.8 | $774 | 2640 | 6/12 | 95W | 2.5/2.5/3 | $885 |
| 2630 | 6/12 | 95W | 2.3/2.3/2.8 | $612 | |||||
| E5645 | 6/12 | 80W | 2.4/2.53/2.66 | $551 | |||||
| 2620 | 6/12 | 95W | 2/2/2.5 | $406 | |||||
| E5620 | 4/8 | 80W | 2.4/2.53/2.66 | $387 | |||||
| High clock / budget | High clock / budget | ||||||||
| X5647 | 4/8 | 130W | 2.93/3.06/3.2 | $774 | 2643 | 4/8 | 130W | 3.3/3.3/3.5 | $885 |
| E5630 | 4/8 | 80W | 2.53/2.66/2.8 | $551 | |||||
| E5607 | 4/4 | 80W | 2.26 | $276 | 2609 | 4/4 | 80W | 2.4 | $294 |
| Power Optimized | Power Optimized | ||||||||
| L5640 | 6/12 | 60W | 2.26/2.4/2.66 | $996 | 2650L | 8/16 | 70W | 1.8/2/2.3 | $1107 |
| 5630 | 4/8 | 40W | 2.13/2.26/2.4 | $551 | 2630L | 8/16 | 60W | 2/2/2.5 | $662 |
In my experience, workstations for research are often prebuilt, so if the system builder makes a 10% markup, this would extrapolate the prices even more. For the processors we are focusing on today, the boxed version of the X5690 sits at $1666 each and the E5-2690 is $2061 – about a 25% price difference moving up to the E5-2690. However as a system the price difference may be slightly more, when we include memory and power supplies into the mix – even more if you want to expand the functionality for new interfaces. When dealing with a personal machine, a user can often recoup the cost by selling on the old hardware, making the cost more palatable – the research group cannot do the same, and more often than not the old hardware gets passed down to experimentalists, or sits in the corner when extra CPU power is needed. That makes the price an absolute cost, rather than an upgrade difference.
Whenever I get told that a component is too expensive (a lot of users are currently berating the price of NVIDIA’s GTX Titan, for example), my response is often this:
- Look at what you are currently using, and the performance increase that the better part would give
- If time is money, calculate how much time you would save using the newer component. Convert that into a cost benefit analysis (i.e. completing a contract in 6 months rather than 7 months) as more computation can be processed.
- If the cost can be recouped over 12 months, the purchase is probably justified (depending on who finances what) and will allow you to consider another upgrade in 12 months.
It is quite rare to be in a situation where the computational time is the limiting factor in a project, although I do acknowledge that when dealing with long simulations or calculations it can be. But if you can finish analyzing results in 4 hours rather than 6, if there is an error, it can be fixed and re-run in a shorter time. Essentially the more you require computational throughput for a project, the better the cost analysis usually is.
With all this said, the proof is always going to be in the numbers – I would suggest that for each situation our readers face, to weigh up the computational aspects of their work. In research, I spent more time organizing mathematics and coding than simulating, though when simulating some of them would take a week on a GTX 480 GPU, and I would run several batches at once. If Titan was around then and could save 40% of that time, I would have plugged my research supervisor for one in an instant. Similar arguments would have been made on the non-GPU side of the research, as often we would use each other’s 16 thread machines to get stuff done (and then repeat it if there was a coding error).








44 Comments
View All Comments
Kevin G - Monday, March 4, 2013 - link
Ivy Bridge-E is a drop in replacement so that investment into RAM, storage, motherboard, chassis would be identical to today. The transition between Sandy Bridge-E and Ivy Bridge-E will mirror the transition between Nehalem and Westmere: socket compatible drop-in replacements in most cases.colonelpepper - Monday, March 4, 2013 - link
yeah, what i was thinking might be a decent route to take is to build out a workstation with 2 of the lower end more moderately priced Xeon 2600's... save the big $$ for the new chips.Shadowmage - Monday, March 4, 2013 - link
Your current suite of benchmarks is extremely limited for you to be able to call this a review for "scientists". For example, I'm interested in how these processors perform in Xilinx XST/MAP/PAR and simulation (e.g. Gem5) benchmarks.IanCutress - Tuesday, March 5, 2013 - link
Of course - any review aimed at scientists is going to be extremely limited. Forgive me when I can only represent where I have come from - I haven't done research in every field.Ian
Simen1 - Tuesday, March 5, 2013 - link
Wouldnt it be fair to compare the Dual Xeon systems to a similar priced dual Opteron system?Simen1 - Tuesday, March 5, 2013 - link
And the mentioning of the 3 year old Opteron 6100 and 1,5 year old 6100 on the first page is irellevant now in 2013. Todays models are in the 6300 series.IanCutress - Thursday, March 7, 2013 - link
If we get a dual Opteron 6300 system in, we will compare.plext0r - Tuesday, March 5, 2013 - link
Would have been nice to throw in some bigadv work units from the Folding@Home project to see how the systems compare.Michael REMY - Wednesday, March 6, 2013 - link
hi !i really thought it is unfair and un-objectif to not include one of the E3-1290V2 or xeon E5-1620 in your test. Why (the hell) the i7-3770 do in you "profesional server" comparaison test ?
E3-1290V2 and E5-1620 are the higher clock and newer xeon ! you should put them in the race !
best regard
IanCutress - Thursday, March 7, 2013 - link
It's all about the equipment we have to hand. We don't have every CPU ever created. Plus, putting in consumer CPUs lets everyone know the playing field.Ian