Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Test Setup
Alongside the X5690 CPUs we are using for this review, the Gigabyte server team was at hand to offer one of their dual processor 1366 server motherboards – the GA-7TESM. The 7TESM was released back in September 2011, featuring support for 55xx/56xx Xeons and up to 18 DIMMs of registered or unbuffered DDR3 memory – for up to 288GB at 1333 MHz with Netlist Hypercloud modules. Alongside four Intel GbE network ports (82576EB + 2x 82574L) and a management port, we get six SATA 3 Gbps ports from the chipset and 8 SAS 6 Gbps ports from an LSI SAS2008 chip (via SFF-8087), both supporting RAID 0/1/5/10. Onboard video comes from a Matrox 200e, and the system provides a PCIe 2.0 x16, an x8, an x4, and a PCI slot. Many thanks to Gigabyte for making the review possible!

Many thanks also to...
We must thank the following companies for kindly providing hardware for our test bed:
Thank you to OCZ for providing us with the 1250W Gold Power Supply and SATA SSD.
Thank you to Kingston for providing us with the ECC Memory.
| Test Setup | |
| Processor |
2x Intel Xeon X5690 6 Cores, 12 Threads 3.47 GHz (3.73 GHz Turbo) each |
| Motherboards | Gigabyte GA-7TESM |
| Cooling | Intel Thermal Solution STS100C |
| Power Supply | OCZ 1250W Gold ZX Series |
| Memory | Kingston 1600 C11 ECC 8x4GB Kit |
| Memory Settings | 1333 C9 |
| Hard Drive | Kingston 120GB HyperX |
| Optical Drive | LG GH22NS50 |
| Case | Open Test Bed |
| Operating System | Windows 7 64-bit |
As per the last test with E5 2600 CPUs, we are using Windows 7 64 bit. The reason behind this is simple – in the research environment I was in, we never updated operating systems beyond security updates. IT staff wanted everyone in the building to use an approved OS image, of which there was only Windows XP, if anyone wanted network access. For this review I got in contact with a colleague to see if this is still the case, and it is – Windows XP 32-bit across the whole department at the university.
Power Consumption
Power consumption was tested on the system as a whole with a wall meter connected to the OCZ 1250W power supply, while in a single 7970 GPU configuration. This power supply is Gold rated, and as I am in the UK on a 230-240 V supply, leads to ~75% efficiency > 50W, and 90%+ efficiency at 250W, which is suitable for both idle and multi-GPU loading. This method of power reading allows us to compare the power management of the UEFI and the board to supply components with power under load, and includes typical PSU losses due to efficiency. These are the real world values that consumers may expect from a typical system (minus the monitor) using this motherboard.
While this method for power measurement may not be ideal, and you feel these numbers are not representative due to the high wattage power supply being used (we use the same PSU to remain consistent over a series of reviews, and the fact that some boards on our test bed get tested with three or four high powered GPUs), the important point to take away is the relationship between the numbers. These boards are all under the same conditions, and thus the differences between them should be easy to spot.
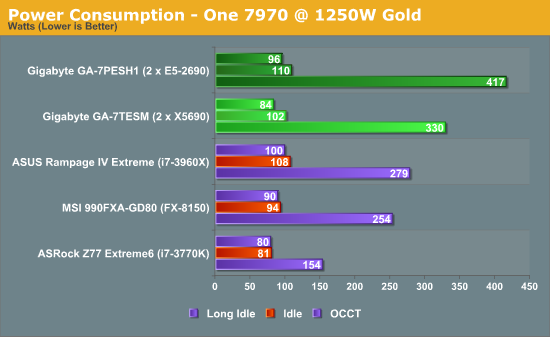
For the workstation theorist in a research group, power consumption is often the last thing on their minds – as long as the system computes in a decent time, everything is golden. In a commercial situation where the code works and throughput is everything, then power does matter. The Sandy Bridge-EP system used 26.3% more power during CPU load than our Westmere-EP system did, in line with the pricing of the CPU itself.
DPC Latency
Deferred Procedure Call latency is a way in which Windows handles interrupt servicing. In order to wait for a processor to acknowledge the request, the system will queue all interrupt requests by priority. Critical interrupts will be handled as soon as possible, whereas lesser priority requests, such as audio, will be further down the line. So if the audio device requires data, it will have to wait until the request is processed before the buffer is filled. If the device drivers of higher priority components in a system are poorly implemented, this can cause delays in request scheduling and process time, resulting in an empty audio buffer – this leads to characteristic audible pauses, pops and clicks. Having a bigger buffer and correctly implemented system drivers obviously helps in this regard. The DPC latency checker measures how much time is processing DPCs from driver invocation – the lower the value will result in better audio transfer at smaller buffer sizes. Results are measured in microseconds and taken as the peak latency while cycling through a series of short HD videos - under 500 microseconds usually gets the green light, but the lower the better.

For whatever reason the DPC Latency on the X5690 system is bad. This is more indicative of the motherboard than the CPU performance, which should easily handle DPC requests. It is highly doubtful that time sensitive work would be carried out on a system like this, but any non-Xeon product would be able to outperform our setup.








44 Comments
View All Comments
SatishJ - Monday, March 4, 2013 - link
It would be only fair to compare X5690 with E5-2667. I suspect in this case the performance difference would not be earth-shattering. No doubt E5-2690 excels but then it has advantage of more cores / threads.wiyosaya - Monday, March 4, 2013 - link
There is a possible path forward for those dealing with "old" FORTRAN code. CUDA FORTRAN - http://www.pgroup.com/resources/cudafortran.htmI would expect that there would be some conversion issues, however, I would also expect that they would be lesser than converting to C++ or some other CUDA/openCL compliant language.
As much as some of us might like it to be, FORTRAN is not dead, yet!
mayankleoboy1 - Monday, March 4, 2013 - link
1. Why not use 7Zip for the compression benchmark ? Most HPC people would like to use a FREE, Highly threaded software for their work.2.Using 3770K @ 5.4 Ghz as a comparison point is foolish. Any Ivy bride processor above ~4.6 on air is unrealistic. And for HPC, no body will use a overclocked system.
Senti - Monday, March 4, 2013 - link
WinRar is interesting because it's very sensitive to memory subsystem (7zip is less so), but 3.93 is absolutely useless as it utilizes about half of my cpu time and the end result it turns into powersaving impact benchmark before anything else. AT promised to upgrade sometime this year, but before it we'll continue to have one less useful benchmark.Not overclocking your cpu when you have good cooling is plain waste of resources. Of course I mean not extreme overclocks, but permanent maximum "turbo" frequency should be your minimum goal.
SetiroN - Monday, March 4, 2013 - link
Sorry but...-So what?
Being "sensitive to memory" doesn't make a worse benchmark better, or free;
-So what?
Nobody will ever have good enough cooling to be able to compute daily at 5.4, which is FAR above max turbo anyway. Overclocked results are welcome, provided that I don't need an additional $500 phase change cooler and $100+ in monthly bills.
tynopik - Monday, March 4, 2013 - link
> Being "sensitive to memory" doesn't make a worse benchmark better, or free;It makes it better if your software is also sensitive to memory speed
different benchmarks that measure different aspects of performance are a GOOD thing
Death666Angel - Monday, March 4, 2013 - link
The OC CPU I see as a data point for his statement that some workloads don't require multi socket CPU systems but rather a single high IPC CPU. It may or may not be unrealistic for the target demographic, but it does add a data point for or against such a thing.IanCutress - Tuesday, March 5, 2013 - link
1. WinZip 3.93 has been part of my benchmark suite for the past 18 months (so lots of comparison numbers can be scrutinized), and is the one I personally use :) We should be updating to 4.2 for Haswell, though going back and testing the last few years of chipsets and various processors takes some time.2. My inhouse retail CPU does 4.9 GHz on air, easy :) But most of the OC numbers are courtesy of several HWBot overclockers at Overclock.net who volunteered to help as part of the testing. For them the bigger score the better, hence the overclocks on something other than ambient.
Ian
mayankleoboy1 - Monday, March 4, 2013 - link
How many real world workloads are using hand-coded AVX software ?How many use compiler optimized AVX software ?
What is the perf difference between them?
Not directly related to this article, but how many softwares have the AMD Bulldozer/piledriver optimised FMA and BMI extensions ?
Kevin G - Monday, March 4, 2013 - link
What is going on with the Explicit Finite Difference tests? The thing that stood out to me are the two results for the i7 3770K at 4.5 Ghz with memory speed being the differentiating factor. Going from 2000 Mhz to 2600 Mhz effective speed on the memory increased performance by ~13% in the 2D tests and ~6% in the 3D tests. Another thing worth pointing out is that the divider in Ivy Bridge has higher throughput than Sandy Bridge. This would account for some of the exceedingly high performance of the desktop Ivy Bridge systems if the algorithms make heavy use of division. The dual socket systems likely need some tuning with regards to their memory systems. The results of the dual socket systems are embarrassing in comparison to their 'lesser' single socket brethen.The implicit 2D test is similarly odd. The odd ball result is the Core i7 3820@4.2 Ghz against the Ivy bridge based Core i7 3770k@stock (3.5 Ghz). Despite the higher clock speed and extra memory channel, the consumer Sandy Bridge-E system loses! This is with the same number of cores and threads running. Just how much division are these algorithms using? That is the only thing that I can fathom to explain these differences. Multi-socket configurations are similarly nerfed with the implicit 2D test as they are with the explicit 2D test.
Did the Browian Motion simulations take advantage of Ivy Bridge's hardware random number generator? Looking at the results, signs are pointing toward 'no'.
I'm a bit nitpicky about the usage of the word 'element' describing the n-Body simulation with regards to gravity. The usage of element and particle are not technically incorrect but lead the reader to think that these simulations are done with data regarding the microscopic scales, not stellar.
The Xilisoft Video Converter test results seem to be erroneous. More than doubling the speed by enabling Hyperthreading? How is that even possible? Best case for Hypthereading is that half of the CPU execution resources are free so that another thread can utilize them and get double the throughput. HT rarely gets near twice as fast but these results imply five times faster which is outside the realm of possibility with everything else being equal. Scaling between the Core i7-3960k and the dual E5-2690 HT Off result looks off given how the results between other platforms look too.