OCZ Vector (256GB) Review
by Anand Lal Shimpi on November 27, 2012 9:10 PM ESTRandom Read/Write Speed
The four corners of SSD performance are as follows: random read, random write, sequential read and sequential write speed. Random accesses are generally small in size, while sequential accesses tend to be larger and thus we have the four Iometer tests we use in all of our reviews.
Our first test writes 4KB in a completely random pattern over an 8GB space of the drive to simulate the sort of random access that you'd see on an OS drive (even this is more stressful than a normal desktop user would see). I perform three concurrent IOs and run the test for 3 minutes. The results reported are in average MB/s over the entire time. We use both standard pseudo randomly generated data for each write as well as fully random data to show you both the maximum and minimum performance offered by SandForce based drives in these tests. The average performance of SF drives will likely be somewhere in between the two values for each drive you see in the graphs. For an understanding of why this matters, read our original SandForce article.

Low queue depth random read performance sees a significant regression compared to the Vertex 4. OCZ derives the Vector's specs at a queue depth of 32, at which it'll push 373MB/s of 4KB random reads. As Intel has established in the past, low queue depth random read performance of around 40 - 50MB/s is sufficient for most client workloads as we'll soon see in our trace based storage bench suite.
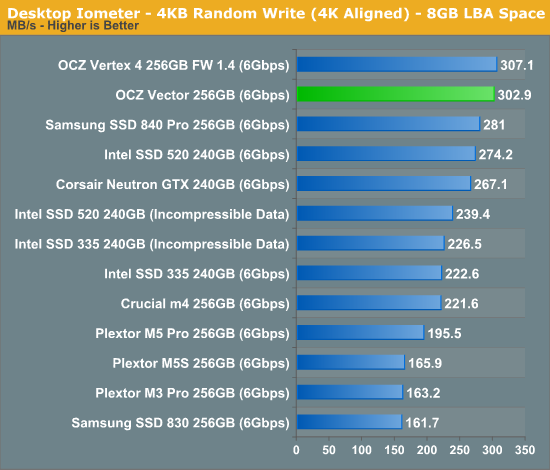
Low queue depth random write performance is a very different story, here the Vector pretty much equals the Vertex 4's already excellent score.
Many of you have asked for random write performance at higher queue depths. What I have below is our 4KB random write test performed at a queue depth of 32 instead of 3. While the vast majority of desktop usage models experience queue depths of 0 - 5, higher depths are possible in heavy I/O (and multi-user) workloads:
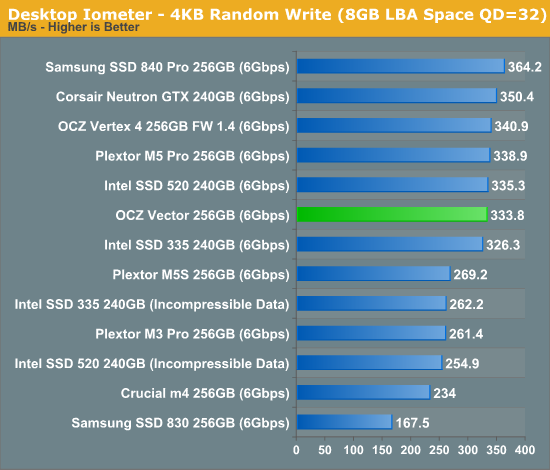
Crank up the queue depth and the Vector does well, but Samsung's SSD 840 Pro manages a nearly 10% performance advantage here.
Steady State 4KB Random Write Performance
OCZ will surely derive enterprise versions of the Vector and its Barefoot 3 controller, but I was curious to see what steady state 4KB random write performance looked like on the drive. I grabbed some of our Enterprise Iometer results from the S3700 review and trimmed out the non-SATA drives. The results are hugely improved compared to the Vertex 4:
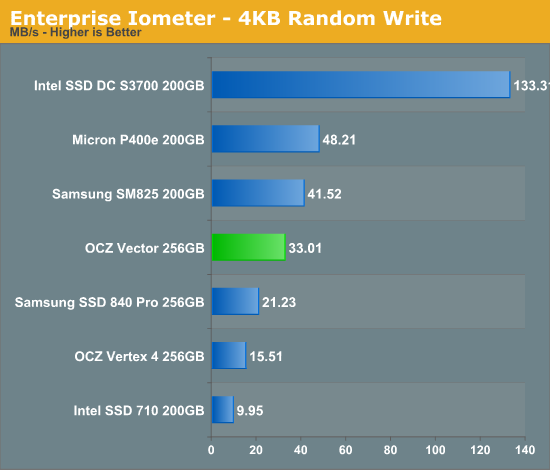
Keep in mind this isn't an enterprise drive, and thus it's not too surprising to see significantly higher numbers here from other enterprise drives but the improvement over the Vertex 4 is substantial. Note that Samsung's SSD 840 Pro lands somewhere in between the Vector and Vertex 4.








151 Comments
View All Comments
melgross - Wednesday, November 28, 2012 - link
What does that mean; usable space? Every OS leaves a different amount after formatting, so whether the drive is rated by GB or GiB, the end result would be different. Normally, SSD's are rated as to the around seen by the OS, not by that plus the around overrated. So it isn't really a problem.Actually, the differences we're talking about isn't all that much, and is more a geeky thing to concern oneself with more than anything else. Drives are big enough, even SSD's, so that a few GB's more or less isn't such a big deal.
Kristian Vättö - Wednesday, November 28, 2012 - link
An SSD can't operate without any over-provisioning. If you filled the whole drive, you would end up in a situation where the controller couldn't do garbage collection or any other internal tasks because every block would be full.Drive manufacturers are not the issue here, Microsoft is (in my opinion). They are using GB while they should be using GiB, which causes this whole confusion. Or just make GB what it really is, a billion bytes.
Holly - Thursday, November 29, 2012 - link
Sorry to say so, but I am afraid you look on this from wrong perspective. Unless you are IT specialist you go buy a drive that says 256GB and expect it to have 256GB capacity. You don't care how much additional space is there for replacement of bad blocks or how much is there for internal drive usage... so you will get pretty annoyed by fact that your 256GB drive would have let's say 180GB of usable capacity.And now this GB vs GiB nonsense. From one point of view it's obvious that k,M,G,T prefixes are by default *10^3,10^6,10^9,10^12... But in computers capacity units they used to be based on 2^10, 2^20 etc. to allow some reasonable recalculation between capacity, sectors and clusters of the drive. No matter what way you prefer, the fact is that Windows as well as many IDE/SATA/SAS/SCSI controllers count GB equal to 2^30 Bytes.
Random controllers screenshots from the internet:
http://www.cisco.com/en/US/i/100001-200000/190001-...
http://www.cdrinfo.com/Sections/Reviews/Specific.a...
http://i.imgur.com/XzVTg.jpg
Also, if you say Windows measurement is wrong, why is RAM capacity shown in 'GB' but your 16GB shown in EVERY BIOS in the world is in fact 16384MiB?
Tbh there is big mess in these units and pointing out one thing to be the blame is very hasty decision.
Also, up to some point the HDD drive capacity used to be in 2^k prefixes long time ago as well... still got old 40MB Seagate that is actually 40MiB and 205MB WD that is actually 205MiB. CD-Rs claiming 650/700MB are in fact 650/700MiB usable capacity. But then something changed and your 4.7GB DVD-R is in fact 4.37GiB usable capacity. And same with hard discs...
Try to explain angry customers in your computer shop that the 1TB drive you sold them is 931GB unformatted shown both by controller and Windows.
Imho nobody would care slightest bit that k,M,G in computers are base 2 as long as some marketing twat didn't figure out that his drive could be a bit "bigger" than competition by sneaking in different meaning for the prefixes.
jwilliams4200 - Thursday, November 29, 2012 - link
It is absurd to claim that "some marketing twat didn't figure out that his drive could be a bit "bigger" than competition by sneaking in different meaning for the prefixes".The S.I. system of units prefixes for K, M, G, etc. has been in use since before computers were invented. They have always been powers of 10. In fact, those same prefixes were used as powers of ten for about 200 years, starting with the introduction of the metric system.
So those "marketing twats" you refer to are actually using the correct meaning of the units, with a 200 year historical precedent behind them.
It is the johnny-come-latelys that began misusing the K, M, G, ... unit prefixes.
Fortunately, careful people have come up with a solution for the people incorrectly using the metric prefixes -- it is the Ki, Mi, Gi prefixes.
Unfortunately, Microsoft persists in misusing the metric prefixes, rather than correctly using the Ki, Mi, Gi prefixes. That is clearly a bug in Microsoft Windows. Kristian is absolutely correct about that.
Holly - Friday, November 30, 2012 - link
How much RAM does your bios report you have?Was the BIOS of your motherboard made by Microsoft?
jwilliams4200 - Friday, November 30, 2012 - link
Would you make that argument in front of a judge?"But judge, lots of other guys stole cars also, it is not just me, so surely you can let me off the hook on these grand-theft-auto charges!"
Touche - Saturday, December 1, 2012 - link
No, he is right. Everything was fine until HDD guys decided they could start screwing customers for bigger profits. Microsoft and everyone else uses GB as they should with computers. It was HDD manufacturers that caused this whole GB/GiB confusion regarding capacity.jwilliams4200 - Saturday, December 1, 2012 - link
I see that you are a person who never lets the facts get in the way of a conspiracy theory.Touche - Monday, December 3, 2012 - link
http://betanews.com/2006/06/28/western-digital-set...Holly - Monday, December 3, 2012 - link
Well, 2^10k prefixes marked with 'i' were made in a IEC in 1998, in IEEE in 2005, alas the history is showing up frequent usage of both 10^3k and 2^10k meanings. Even with IEEE passed in 2005 it took another 4 years for Apple (who were the first with OS running with 2^10k) to turn to 'i' units and year later for Ubuntu with 10.10 version.For me it will always make more sense to use 2^10k since I can easily tell size in kiB, MiB, GiB etc. just by bitmasking (size & 11111111110000000000[2]) >> 10 (for kiB). And I am way too used to k,M,G with byte being counted for 2^10k.
Some good history reading about Byte prefixes can be found at http://en.wikipedia.org/wiki/Timeline_of_binary_pr... ...
Ofc, trying to reason with people who read several paragraph post and start jumping around for one sentence they feel offended with is useless.
But honestly even if kB was counted for 3^7 bytes it wouldn't matter... as long as everyone uses the same transform ratio.