Intel's Medfield & Atom Z2460 Arrive for Smartphones: It's Finally Here
by Anand Lal Shimpi on January 10, 2012 8:00 PM ESTThe CPU
Medfield is the platform, Penwell is the SoC and the CPU inside Penwell is codenamed Saltwell. It's honestly not much different than the Bonnell core used in the original Atom, although it does have some tweaks for both power and performance.
Almost five years ago I wrote a piece on the architecture of Intel's Atom. Luckily (for me, not Intel), Atom's architecture hasn't really changed over the years so you can still look back at that article and have a good idea of what is at the core of Medfield/Penwell. Atom is still a dual-issue, in-order architecture with Hyper Threading support. The integer pipeline is sixteen stages long, significantly deeper than the Cortex A9's. The longer pipeline was introduced to help reduce Atom's power consumption by lengthening some of the decode stages and increasing cache latency to avoid burning through the core's power budget. Atom's architects, similar to those who worked on Nehalem, had the same 2:1 mandate: every new feature added to the processor's design had to deliver at least a 2% increase in performance for every 1% increase in power consumption.
Atom is a very narrow core as the diagram below will show:
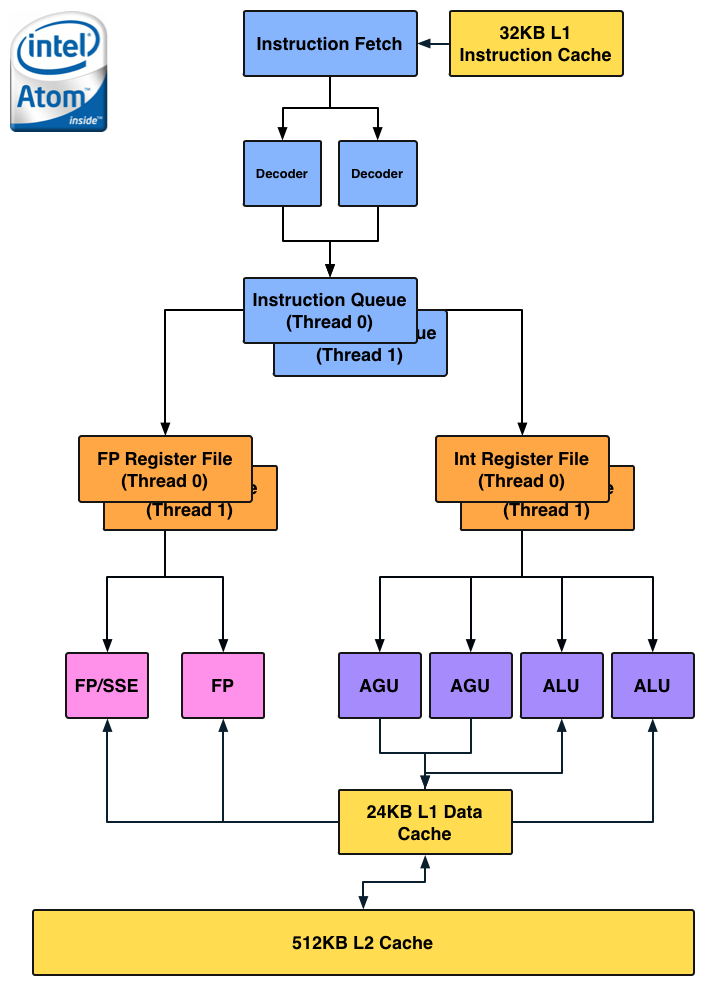
There are no dedicated integer multiply or divide units, that's all shared with the FP hardware. Intel duplicated some resources (e.g. register files, queues) to enable Hyper Threading support, but stopped short of increasing execution hardware to drive up efficiency. The tradeoff seems to have worked because Intel is able to deliver performance better than a dual-core Cortex A9 from a single HT enabled core. Intel also lucks out because while Android is very well threaded, not all tasks will continually peg both cores in a dual-core A9 machine. At higher clock speeds (1.5GHz+) and with heavy multi-threaded workloads, it's possible that a dual-core Cortex A9 could outperform (or at least equal) Medfield but I don't believe that's a realistic scenario.
Architecturally the Cortex A9 doesn't look very different from Atom:
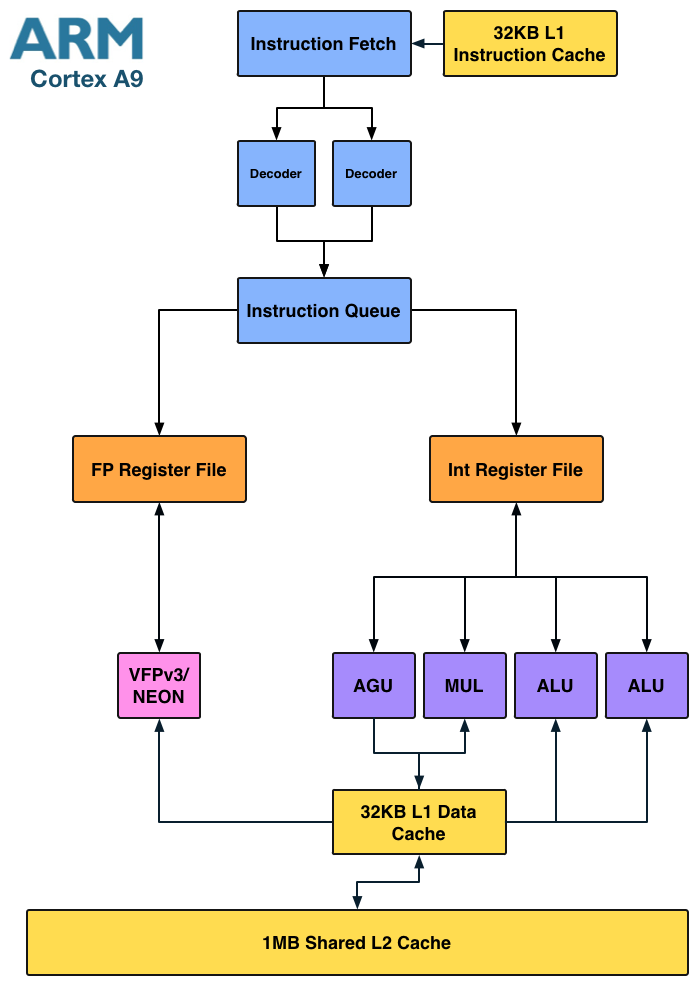
Here we see a dedicated integer multiply unit (shared with one of the ALU ports) but only a single port for FP/NEON. It's clear that the difference between Atom and the Cortex A9 isn't as obvious at the high level. Instead it's the lower level architectural decisions that gives Intel a performance advantage.
Where Intel is in trouble is if you look at the Cortex A15:
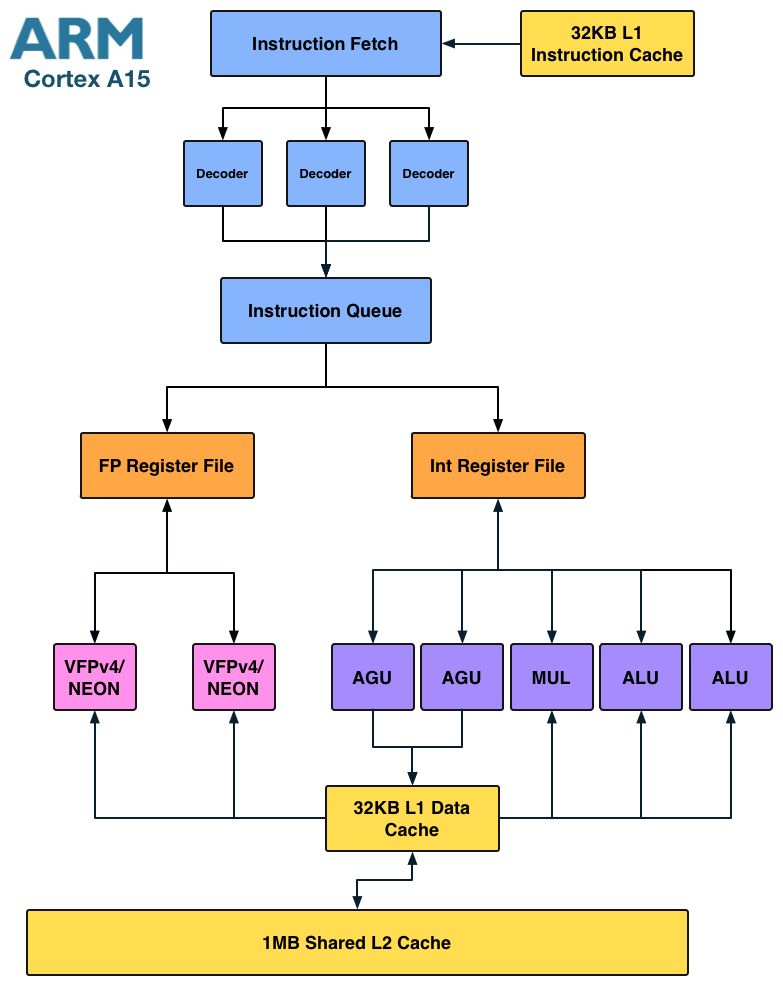
The A15 is a far more modern design, also out of order but much wider than A9. I fully expect that something A15-class can outperform Medfield, especially if the former is in a dual-core configuration. Krait falls under the A15-class umbrella so I believe Medfield has the potential to lose its CPU performance advantage within a couple of quarters.
Enhancements in Saltwell
Although the CPU core is mated to a 512KB L2 cache, there's a separate 256KB low power SRAM that runs on its own voltage plane. This ULP SRAM holds CPU state and data from the L2 cache when the CPU is power gated in the deepest sleep state. The reasoning for the separate voltage plane is simple. Intel's architects found that the minimum voltage for the core was limited by Vmin for the ULP SRAM. By putting the two on separate voltage planes it allowed Intel to bring the CPU core down to a lower minimum power state as Vmin for the L2 is higher than it is for the CPU core itself. The downside to multiple power islands is an increase in die area. Since Medfield is built on Intel's 32nm LP process while the company transitions to 22nm, spending a little more on die area to build more power efficient SoCs isn't such a big deal. Furthermore, Intel is used to building much larger chips, making Medfield's size a relative nonissue for the company.
The die size is actually very telling as it's a larger SoC than a Tegra 2 with two Cortex A9s despite only featuring a single core. Granted the rest of the blocks around the core are different, but it goes to show you that the CPU core itself (or number of cores) isn't the only determination of the die size of an SoC.
The performance tweaks come from the usual learnings that take place over the course of any architecture's lifespan. Some instruction scheduling restrictions have been lifted, memory copy performance is up, branch predictor size increased and some microcode flows run faster on Saltwell now.
Clock Speeds & Turbo
Medfield's CPU core supports several different operating frequencies and power modes. At the lowest level is its C6 state. Here the core and L2 cache are both power gated with their state is saved off in a lower power on-die SRAM. Total power consumption in C6 of the processor island is effectively zero. This isn't anything new, Intel has implemented similar technologies in desktops since 2008 (Nehalem) and notebooks since 2010 (Arrandale).
When the CPU is actually awake and doing something however it has a range of available frequencies: 100MHz all the way up to 1.6GHz in 100MHz increments.
The 1.6GHz state is a burst state and shouldn't be sustained for long periods of time, similar to how Turbo Boost works on Sandy Bridge desktop/notebook CPUs. The default maximum clock speed is 1.3GHz, although just as is the case with Turbo enabled desktop chips, you can expect to see frequencies greater than 1.3GHz on a fairly regular basis.
Power consumption along the curve is all very reasonable:
| Medfield CPU Frequency vs. Power | ||||||
| 100MHz | 600MHz | 1.3GHz | 1.6GHz | |||
| SoC Power Consumption | ~50mW | ~175mW | ~500mW | ~750mW | ||
Since most ARM based SoCs draw somewhere below 1W under full load, these numbers seem to put Medfield in line with its ARM competitors - at least on the CPU side.
It's important to pay attention to the fact that we're dealing with similar clock frequencies to what other Cortex A9 vendors are currently shipping. Any performance advantages will either be due to Medfield boosting up to 1.6GHz for short periods of time, inherently higher IPC and/or a superior cache/memory interface.








164 Comments
View All Comments
french toast - Wednesday, January 18, 2012 - link
I agree with what you are saying, Intel is not competitive in the smartphone space...yet.. but they sure as hell will be within 18 months, this was just about getting a foot in the door..which lets be honest they tried before with moorestown..they even said similar things too, manufacturer tie ups?..remember LG!?But i get the feeling that had this been released mid last year it would have been competitive, but when released this year it will be old news.
I wouldn't take these Intel marketed benchmarks provided by anand too literally, they aren't better than current designs, but with silvermont followed by that steam train like 'tic tock' strategy they will have something to put the wind up ARM shareholders...
Hector2 - Wednesday, January 11, 2012 - link
I think everyone expected Medfield to perform well but the low power is surprising. But not you, eh ? One of those "glass is half empty" kind of guys are you ? Next up for Intel is the next gen 22nm that not only is faster & smaller than 32nm Medfield but has even lower active power and a 10X-20X standby power improvement due to having FinFET transistors. 22nm hits shelves in 2nd quarter for PCs but doesn't get into SoCs until 2013.Exophase - Tuesday, January 10, 2012 - link
Look at the data for the two tests you ran (that aligns perfectly with the only two tests Intel wants to report on, I might add!) - you see that the Galaxy Nexus does drastically better than the Galaxy SII despite having a very similar CPU arrangement. That should be a massive red flag that this test is right now more about software maturity than uarch, yet you use it to draw sweeping conclusions about uarch.These tests are about javascript. Javascript performance, while important, hardly dominates software usage on mobile platforms, nor is it representative of other programs. For one thing, it's JITed code and browser developers have spent a lot more time optimizing for x86 than ARM, while other platforms (GCC, Dalvik) are less slanted. For another thing, Javascript is double-precision float oriented, which isn't even remotely a standard nor useful programming paradigm for everything else that runs on phones.
All I can say is that you need to do some real benchmarks before you make the conclusions you have, and not just parrot the highly skewed selection Intel has given. That is, if you don't want to come off as Intel sponsored.
chuckula - Tuesday, January 10, 2012 - link
Uh... Android (which is what Intel is running) has been optimized for ARM all the way back to version 1.0. To come out now and complain that x86 is getting "unfair" software optimization advantages in its very first release before there has been much opportunity at all to do *any* real optimizations is really stretching things.If ARM wants more optimizations, it can contribute source code updates to GCC (it's open source after all).
Exophase - Tuesday, January 10, 2012 - link
Maybe you don't understand my post. These tests are JAVASCRIPT BENCHMARKS. Android optimization barely plays into it: what we're going to be looking at is Chrome optimization. You know what also doesn't play into it? GCC. The Javascript VM in the browser performs its own compilation, and JITs especially have really long development paths. I guess you missed what I said about the comparison of two different Android platforms, which shows that this is clearly an area where ARM performance is highly in flux and therefore immature and not representative.Regardless of whether or not you understand why this isn't a good test, you should at least understand that running only two benchmarks - two benchmarks that fall under the same category, no less - is a really pitiful way to draw conclusions about uarch. If anyone tried to pull this with an Intel or AMD desktop CPU they'd be immolated.
chuckula - Tuesday, January 10, 2012 - link
You want a wide range of benchmarks between a dual-core Cortex A9 and (older than Medfield) single core Atoms? Go here: http://www.phoronix.com/scan.php?page=article&...The brand-new Omap chip manages to win one real benchmark (C-ray) by 10%, a couple of synthetic cache benchmarks, and loses everything else to single-core Atoms that are actually slower than Medfield.
The benchmarks that Anandtech posted are *extremely* representative of what most people are doing on their phones most of the time. If you want performance numbers for "pure" applications, look at the Phoronix article.
The Dalvik JVM from Google has been optimized to run on ARM from day one. When I mentioned GCC, I was talking about the compiler used to COMPILE the Dalvik JVM (you do know the JVM isn't written in Java, right?). Dalvik is NOT the same JVM that you get from Sun/Oracle that (might) be more optimized for x86 than for ARM. In fact, Dalvik is a register-based VM while J2SE is a stack based VM, and Oracle has sued Google over it since Google lifted the Java interfaces but ditched the rest of the VM. Dalvik was only at beta-level operability with x86 during Honeycomb, and ICS is the first version to really work 100% with x86, but there's no rule saying that there couldn't be more optimizations for x86 based systems.
ARM has had *plenty* of time to work with GCC, Google, and anyone else who is needed to get optimizations introduced into Android. If it takes Intel entering the market to finally spur ARM into action, then I say it's about time this market got some real competition.
mczak - Tuesday, January 10, 2012 - link
I'm not convinced actually those older atoms shown in the phoronix article are really slower than Medfield. I don't think IPC of Medfield is really any higher, and even if it is (slightly) Medfield can only turbo up to 1.6Ghz (so might not run all the time at that frequency potentially) whereas those other atoms all run at 1.6Ghz. Memory bandwidth could also be potentially higher there. Not that it would change things much.Exophase - Tuesday, January 10, 2012 - link
It might have more memory bandwidth than an N270 IF paired with faster than 533MHz DDR2/3.. which I doubt you'll see in a phone. So I expect it to be pretty similar to the Z530's, all told.Clock for clock Medfield's CPU core sounds like it's a little faster due to some tweaks, but it all looks very minor. I'd be surprised if it improved anything by more than a few percent at most.
Exophase - Tuesday, January 10, 2012 - link
Right, now compare those numbers with this:http://openbenchmarking.org/result/1201051-AR-1112...
And this:
http://www.phoronix.com/scan.php?page=article&...
And the only sane conclusion is that Pandaboard ES is or the testing performed on it is critically broken. Now rethink your post.
Try your post again with those things in mind. And don't make me repeat myself any further, Javascript doesn't run on Dalvik, it runs on a Javascript VM. Do you seriously not understand this simple concept? Do you not understand how a purely web based language is not representative of - oh I don't know - apps that are running Java or C/C++ code?
french toast - Wednesday, January 11, 2012 - link
I have to say i am shocked to see those numbers, so much so i do wander about the validity of them as exophase has pointed out, especially since that 'fake' DX11 ivy bridge demo.Regarding the benchmarks, they are single thread right? so in actual fact you are comparing a 1.2ghz cortexa9 v 1.66ghz atom on different software and different process? i suspect that all things being equal the number would be very similar.
I take from the pandaboard tests exactly the same thing, that all clock speeds being equal that clock for clock atom is on par with cortex a9.
BUT that doesnt tell the whole story does it?..multi threaded apps including multiple tabbed web browsing..how would the atom fair against a duel core a9 clocked at 1.66ghz?
Its the power consumtion estimates that are the real suprise here..really? im under the impression that multicore SOCs spread the load across multiple cores to reduce power, and that arm had the power consumption 'in the bag' due to the complexity of x86 cisc v ARM risk.
The die area is also rather shocking, i thought it would be substantially bigger than that.
Whilst these numbers will give ARM vendors food for thought, lets not get ahead of our selfs just yet, Medfield is comparable to tegra 2 class designs(all things equal)
Krait, Cortex A-15 designs will be apon us by the time this launches..again on 28nm and 32nm designs...that should completely smoke this into oblivion.
The real worrying thing is not about this year its next year, if they can match a exynos 4210 when many thought they didnt have a chance..then silvermont on 22nm FINfet will be scary for arm, since they have already convinced Motorolla to sign a multi year deal and they have billions and billions to chuck around..i would be worried if i was an investor with ARM.