The Opteron 6276: a closer look
by Johan De Gelas on February 9, 2012 6:00 AM EST- Posted in
- IT Computing
- CPUs
- Bulldozer
- AMD
- Opteron
- Cloud Computing
- Interlagos
SAP S&D Benchmark
The SAP SD (sales and distribution, 2-tier internet configuration) benchmark is an interesting benchmark as it is a real world client-server application contrary to many server benchmark (such as SpecJBB, SpecIntRate, etc.). We looked at SAP's benchmark database for these results. The results below all run on Windows 2008 and MS SQL Server 2008 database (both 64-bit).
Every 2-tier Sales & Distribution benchmark was performed with SAP's latest ERP 6 enhancement package 4. These results are NOT comparable with any benchmark performed before 2009. We analyzed the SAP Benchmark in-depth in one of our earlier articles. So far, our profile of the benchmark shows:
- Very parallel resulting in excellent scaling
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
- Low IPC
- Branch memory intensive code
We managed to get even better profiling of the benchmark. IPC is as low as 0.5 (!) on the most modern Intel CPU architectures. About 48% of the instructions are loads and stores and 18% are branches. One percent of those branches is mispredicted, so the branch misprediction ratio is slightly higher than 5% on modern Intel cores.
Especially the instruction cache is hit hard, and the hit rate is typically a lot lower than in other applications (probably 10% misses and lower). Even the large L3 caches are not capable of satisfying all requests. The SAP SD benchmarks needs between 10-30GB/s, depending on how aggressive the prefetchers are.
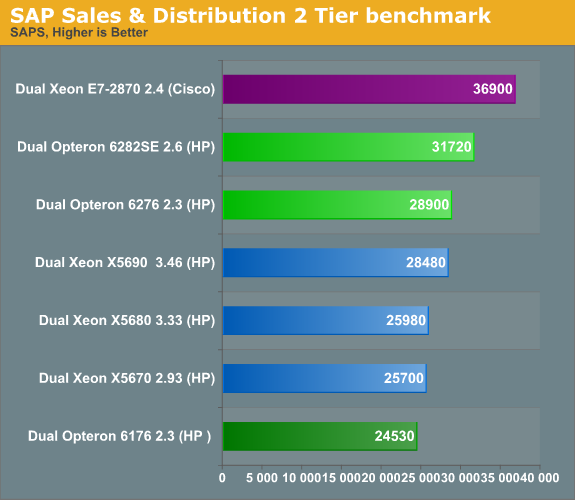
SAP is one of the benchmarks that scale very well and it is shows: the server CPUs with the highest thread count are on top. We remember from older benchmarks that enabling Hyper-Threading (on Nehalem and later) boosts SAP's performance by 35%. As the IPC of a single SAP thread is relatively low (0.5 and lower), the decoding front end of the Bulldozer core should be able to handle this easily. Therefore, the extra integer cluster on the Opteron can really do its magic.
We don't have any Xeon X5650 benchmarks, but a quick calculation tells us that the new Opteron 6276 should be about 20% faster than the X5650. It is also about 18% faster, clock for clock, than the older Opteron 6176. The new Opteron does well here.








46 Comments
View All Comments
Scali - Friday, February 10, 2012 - link
No, because if you read the ENTIRE benchmark configuration page, you'd see that all the AMD systems had 2 CPUs as well.Scali - Saturday, February 11, 2012 - link
Oh, and while we're at it... the Intel system had only 48 GB of 1333 memory, where the AMDs had 64 GB of 1600 memory.(Yes, Bulldozer is THAT bad)
PixyMisa - Saturday, February 11, 2012 - link
Or rather, MySQL scales that poorly.What we can tell from this article is that if you want to run a single instance of MySQL as fast as possible and don't want to get involved with subtle performance tuning options, the Opteron 6276 is not the way to go.
For other workloads, the result can be very different.
JohanAnandtech - Saturday, February 11, 2012 - link
Feel free to send me a suggestion on how to setup another workload. We know how to tune MySQL. So far none of these settings helped. The issue discussed (spinlocks) can not be easily solved.Scali - Saturday, February 11, 2012 - link
I'm not sure if you bothered to read the entire article, because MySQL was not the only database that was tested.There were also various tests with MS SQL, and again, Interlagos failed to impress compared to both Magny Cours-based Opterons and the Xeon system.
JohanAnandtech - Saturday, February 11, 2012 - link
The clockspeed of the RAM has a small impact here. 64 vs 48 GB does not matter.Scali - Saturday, February 11, 2012 - link
Not saying it does... Just pointing out that the AMD system had more impressive specs on paper, yet failed to deliver the performance.JohanAnandtech - Saturday, February 11, 2012 - link
Again, it is not CMT that makes AMD's transistor count explode but the combination of 2x L3 caches and 4x 2M L2-caches. You can argue that AMD made poor choices concerning caches, but again it is not CMT that made the transistor count grow.I am not arguing that AMD's performance/billion transistors is great.
Scali - Saturday, February 11, 2012 - link
I think you are looking at it from the wrong direction.You are trying to compare SMT and CMT, but contrary to what AMD wants to make everyone believe, they are not very similar technologies.
You see, SMT enables two threads to run on one physical core, without adding any kind of execution units, cache or anything. It is little more than some extra logic so that the OoOE buffers can handle two thread contexts at the same time, rather than one.
So the thing with SMT is that it REDUCES the transistorcount required for running two threads. By nearly 100%.
CMT on the other hand does not reduce the transistorcount nearly as much. So if you are merely looking at an 'exposion of transistor count', you are missing the point of what SMT really does.
Other than that, your argument is still flawed. Even an 8-thread Bulldozer has a higher transistor count than the 12-thread Xeon here. It's not just cache. CMT just doesn't pack as many threads per transistor as SMT does... and to make matters worse, CMT also has a negative impact on single-threaded performance (which again, if you are looking at it from the wrong direction, may look like better scaling in threadcount... but effectively, both with low and high threadcounts, the Xeon is the better option... and this is just a midrange Xeon compared to a high-end Interlagos. The Xeon can scale to higher clockspeeds, improving both single-threaded and multithreaded performance for the same transistorcount).
So what your article says is basically this:
CMT, which is nearly the same as having full cores, especially in integer-only tasks such as databases, since you have two actual integer cores, has nearly the same scaling in threadcount as conventional multicore CPUs.
Which has a very high 'duh'-factor, since it pretty much *is* conventional multicore.
It does not reduce transistorcount, nor does it improve performance, so what's the point?
JohanAnandtech - Friday, February 10, 2012 - link
Semantics :-). I can call it a core with CMT, or a module with 2 cores. Both are valid.