The Sandy Bridge Review: Intel Core i7-2600K, i5-2500K and Core i3-2100 Tested
by Anand Lal Shimpi on January 3, 2011 12:01 AM ESTIntel’s Quick Sync Technology
In recent years video transcoding has become one of the most widespread consumers of CPU power. The popularity of YouTube alone has turned nearly everyone with a webcam into a producer, and every PC into a video editing station. The mobile revolution hasn’t slowed things down either. No smartphone can play full bitrate/resolution 1080p content from a Blu-ray disc, so if you want to carry your best quality movies and TV shows with you, you’ll have to transcode to a more compressed format. The same goes for the new wave of tablets.
At a high level, video transcoding involves taking a compressed video stream and further compressing it to better match the storage and decoding abilities of a target device. The reason this is transcoding and not encoding is because the source format is almost always already encoded in some sort of a compressed format. The most common, these days, being H.264/AVC.
Transcoding is a particularly CPU intensive task because of the three dimensional nature of the compression. Each individual frame within a video can be compressed; however, since sequential frames of video typically have many of the same elements, video compression algorithms look at data that’s repeated temporally as well as spatially.
I remember sitting in a hotel room in Times Square while Godfrey Cheng and Matthew Witheiler of ATI explained to me the challenges of decoding HD-DVD and Blu-ray content. ATI was about to unveil hardware acceleration for some of the stages of the H.264 decoding pipeline. Full hardware decode acceleration wouldn’t come for another year at that point.
The advent of fixed function video decode in modern GPUs is important because it helped enable GPU accelerated transcoding. The first step of the video transcode process is to first decode the source video. Since transcoding involves taking a video already in a compressed format and encoding it in a new format, hardware accelerated video decode is key. How fast a decode engine is has a tremendous impact on how fast a hardware accelerated video encode can run. This is true for two reasons.
First, unlike in a playback scenario where you only need to decode faster than the frame rate of the video, when transcoding the video decode engine can run as fast as possible. The faster frames can be decoded, the faster they can be fed to the transcode engine. The second and less obvious point is that some of the hardware you need to accelerate video encoding is already present in a video decode engine (e.g. iDCT/DCT hardware).
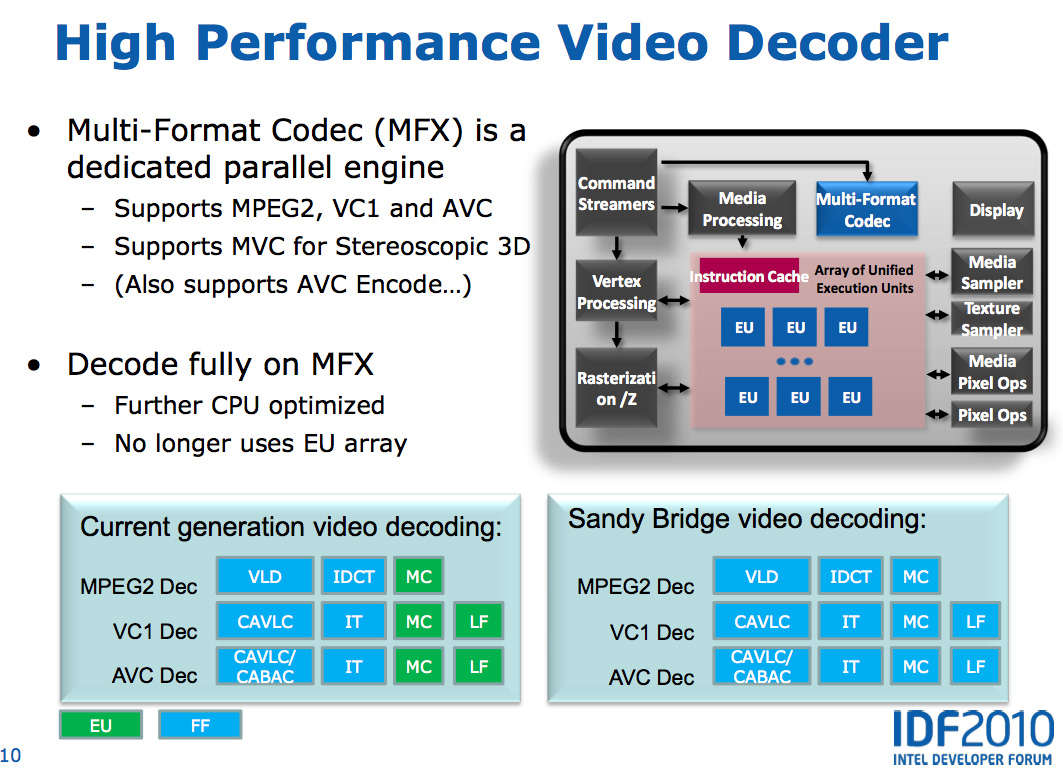
With video transcoding as a feature of Sandy Bridge’s GPU, Intel beefed up the video decode engine from what it had in Clarkdale. In the first generation Core series processors, video decode acceleration was split between fixed function decode hardware and the GPU’s EU array. With Sandy Bridge and the second generation Core CPUs, video decoding is done entirely in fixed function hardware. This is not ideal from a flexibility standpoint (e.g. newer video codecs can’t be fully hardware accelerated on existing hardware), but it is the most efficient method to build a video decoder from a power and performance standpoint. Both AMD and NVIDIA have fixed function video decode hardware in their GPUs now; neither rely on the shader cores to accelerate video decode.
The resulting hardware is both performance and power efficient. To test the performance of the decode engine I launched multiple instances of a 15Mbps 1080p high profile H.264 video running at 23.976 fps. I kept launching instances of the video until the system could no longer maintain full frame rate in all of the simultaneous streams. The graph below shows the maximum number of streams I could run in parallel:
| Intel Core i5-2500K | NVIDIA GeForce GTX 460 | AMD Radeon HD 6870 | |
| Number of Parallel 1080p HP Streams | 5 streams | 3 streams | 1 stream |
AMD’s Radeon HD 6000 series GPUs can only manage a single high profile, 1080p H.264 stream, which is perfectly sufficient for video playback. NVIDIA’s GeForce GTX 460 does much better; it could handle three simultaneous streams. Sandy Bridge however takes the cake as a single Core i5-2500K can decode five streams in tandem.

The Sandy Bridge decoder is likely helped by the very large (and high bandwidth) L3 cache connected to it. This is the first advantage Intel has in what it calls its Quick Sync technology: a very fast decode engine.
The decode engine is also reused during the actual encode phase. Once frames of the source video are decoded, they are actually fed to the programmable EU array to be split apart and prepared for transcoding. The data in each frame is transformed from the spatial domain (location of each pixel) to the frequency domain (how often pixels of a certain color appear); this is done by the use of a discrete cosine transform. You may remember that inverse discrete cosine transform hardware is necessary to decode video; well, that same hardware is useful in the domain transform needed when transcoding.
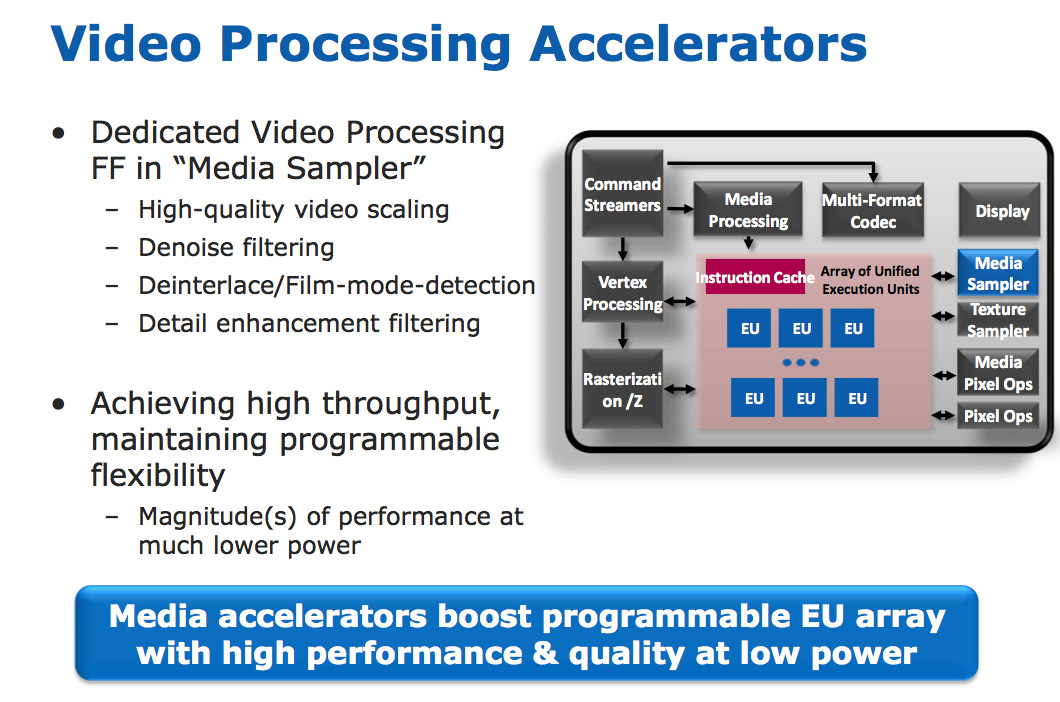
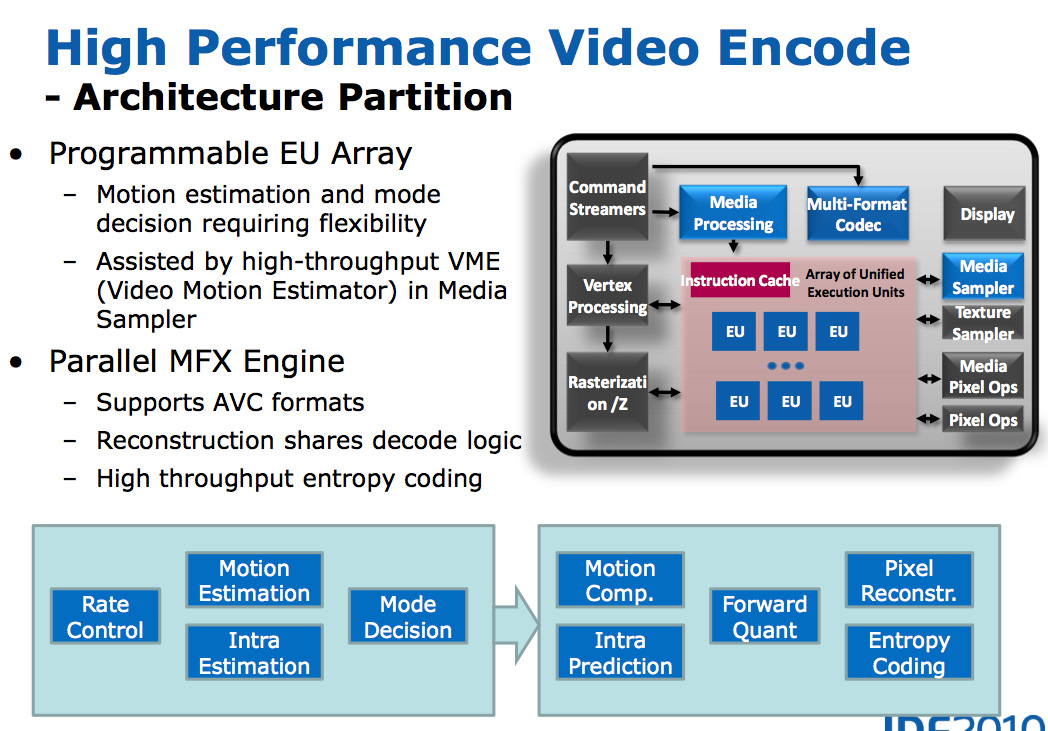
Motion search, the most compute intensive part of the transcode process, is done in the EU array. It's the combination of the fast decoder, the EU array, and fixed function hardware that make up Intel's Quick Sync engine.








283 Comments
View All Comments
-=Hulk=- - Monday, January 3, 2011 - link
That's crazy, are the chipsets PCI-e line still limited to v1 (250MB/s) speed or what????http://images.anandtech.com/reviews/cpu/intel/sand...
mino - Monday, January 3, 2011 - link
No, you read it wrong.There are altogether 8 PCIE 2.0 linex and all can be used independently, aka s as "PCIe x1".
The CPU-Chipset bandwith however is a basic PCIe x4 link, so do not expect wonders is more divices are in heavy use ...
-=Hulk=- - Monday, January 3, 2011 - link
No!Look at the PCI-e x16 from the CPU. Intel indicates a bandwidth of 16GB/s per line. That means 1GB/s per line.
But PCI-e v2 has a bandwidth of 500MB/s per line only. Thats mean that the values that Intel Indicates for the PCI-e lines are the sum of the upload AND download bandwidth of the PCI-e.
Thats means that the PCI-e lines of the chipset run at 250MB/s speed! That is the bandwidth of the PCI-e v1, and Intel has done the same bullshit with the P55/H57, he indicates that they are PCI-e v2 but they limits their speed to the values of the PCI-e v1:
P55 chipset (look at the 2.5GT/s !!!) :
"PCI Express* 2.0 interface:
Offers up to 2.5GT/s for fast access to peripheral devices and networking with up to 8 PCI Express* 2.0 x1 ports, configurable as x2 and x4 depending on motherboard designs.
http://www.intel.com/products/desktop/chipsets/p55... "
P55, also 500MB/s per line as for the P67
http://benchmarkreviews.com/images/reviews/motherb...
Even for the ancient ICH7 Intel indicates 500MB/s per line, but at that time PCI-e v didn't even exist... That's because it's le sum of the upload and download speed of the PCI-e v1.
http://img.tomshardware.com/us/2007/01/03/the_sout...
DanNeely - Monday, January 3, 2011 - link
Because 2.0 speed for the southbridge lanes has been reported repeatedly (along with a 2x speed DMI bus to connect them), my guess is an error when making the slides with bidirectional BW listed on the CPU and unidirectional BW on the southbridge.jmunjr - Monday, January 3, 2011 - link
Intel's sell out to big media and putting DRM in Sandy Bridge means I won't be getting one of these puppies. I don't care how fast it is...Exodite - Monday, January 3, 2011 - link
Uh, what exactly are you referencing?If it's TXT it's worth noting that the interesting chips, the 2500K and 2600K, doesn't even support it.
chirpy chirpy - Tuesday, January 11, 2011 - link
I think the OP is referring to Intel Insider, the not-so-secret DRM built into the sandy bridge chips. I can't believe people are overlooking the fact that Intel is attempting to introduce DRM at the CPU level and all everyone has to say is "wow, I can't WAIT to get one of dem shiny new uber fast Sandy Bridges!"I for one applaud and welcome our benevolent DRM overlords.....
http://www.pcmag.com/article2/0,2817,2375215,00.as...
nuudles - Monday, January 3, 2011 - link
I have a q9400, if I compare it to the 2500K in bench and average (straight average) all scores the 2500K is 50% faster. The 2500K has a 24% faster base clock, so all the architecture improvements plus faster RAM, more cache and turbo mode gained only ~20% or so on average, which is decent but not awesome taking into account the c2q is 3+ year old design (or is it 4 years?). I know that the idle power is significantly lower due to power gating so due to hurry up and wait it consumes less power (cant remember c2q 45nm load power, but it was not much higher than this core 2011 chips).So 50%+ faster sounds good (both chips occupy the same price bracket), but after equating clock speeds (yes it would increase load and idle power on the c2q) the improvement is not massive but still noticeable.
I will be holding out for Bulldozer (possibly slightly slower, especially in lightly threaded workloads?) or Ivy Bridge as mine is still fast enough to do what I want, rather spend the money on adding a SSD or better graphics card.
7Enigma - Monday, January 3, 2011 - link
I think the issue with the latest launch is the complete and utter lack of competition for what you are asking. Anand's showed that the OC'ing headroom for these chips are fantastic.....and due to the thermals even possible (though not recommended by me personally) on the stock low-profile heatsink.That tells you that they could have significantly increased the performance of this entire line of chips but why should they when there is no competition in sight for the near future (let's ALL hope AMD really produces a winner in the next release) or we're going to be dealing with a plodding approach with INTEL for a while. In a couple months when the gap shrinks (again hopefully by a lot) they simply release a "new" batch with slightly higher turbo frequencies (no need to up the base clocks as this would only hurt power consumption with little/no upside), and bam they get essentially a "free" release.
It stinks as a consumer, but honestly probably hurts us enthusiasts the least since most of us are going to OC these anyways if purchasing the unlocked chips.
I'm still on a C2D @ 3.85GHz but I'm mainly a gamer. In a year or so I'll probably jump on the respin of SDB with even better thermals/OC potential.
DanNeely - Monday, January 3, 2011 - link
CPUs need to be stable in Joe Sixpack's unairconditioned trailer in Alabama during August after the heatsink is crusted in cigarette tar and dust, in one of the horrible computer desks that stuff the tower into a cupboard with just enough open space in the back for wires to get out; not just in an 70F room where all the dust is blown out regularly and the computer has good airflow. Unless something other than temperature is the limiting factor on OC headroom that means that large amounts of OCing can be done easily by those of us who take care of their systems.Since Joe also wants to get 8 or 10 years out of his computer before replacing it the voltages need to be kept low enough that electromigration doesn't kill the chip after 3 or 4. Again that's something that most of us don't need to worry about much.