AMD Zen 4 Ryzen 9 7950X and Ryzen 5 7600X Review: Retaking The High-End
by Ryan Smith & Gavin Bonshor on September 26, 2022 9:00 AM ESTCore-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
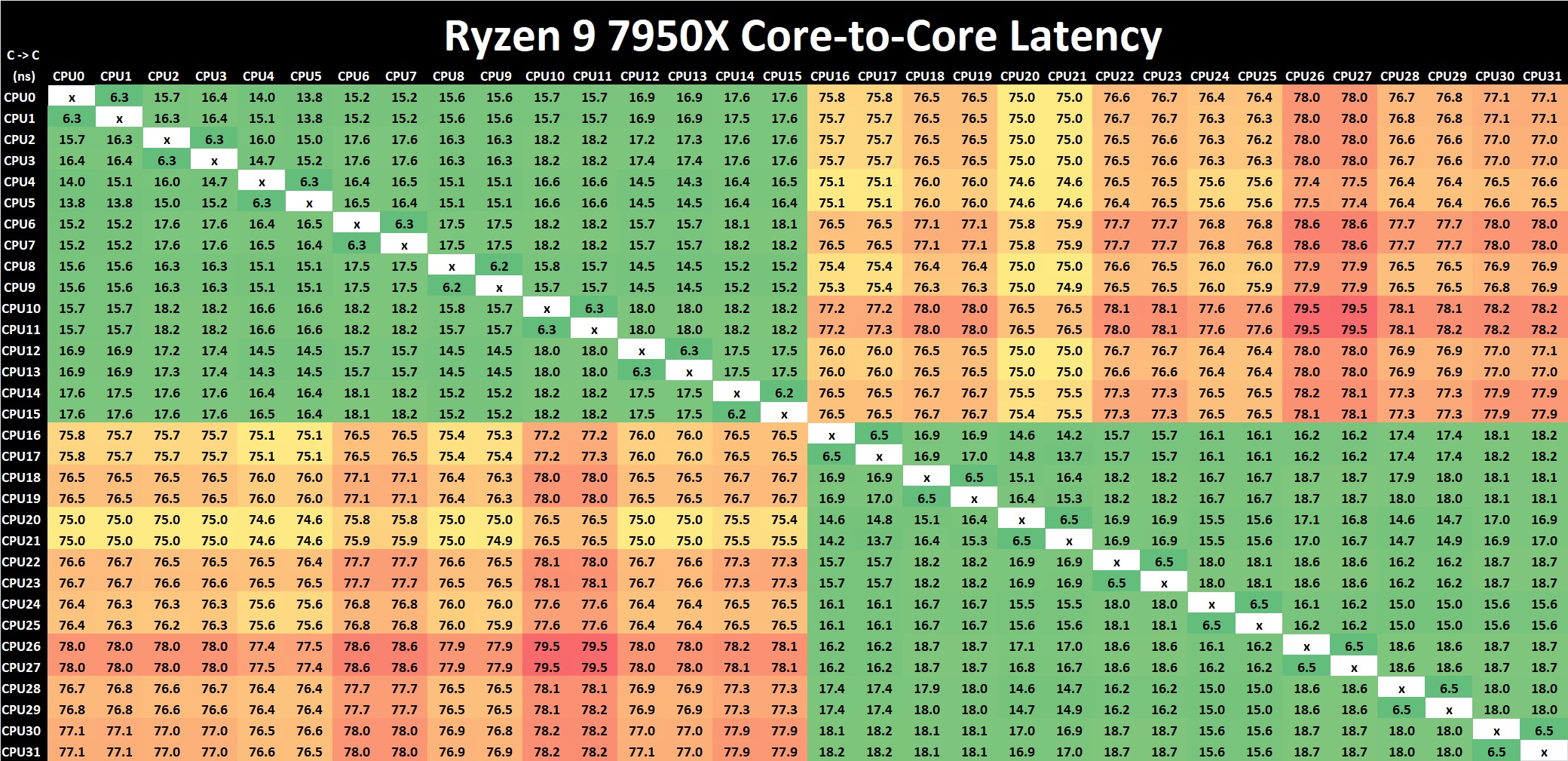
Click to enlarge (lots of cores and threads = lots of core pairings)
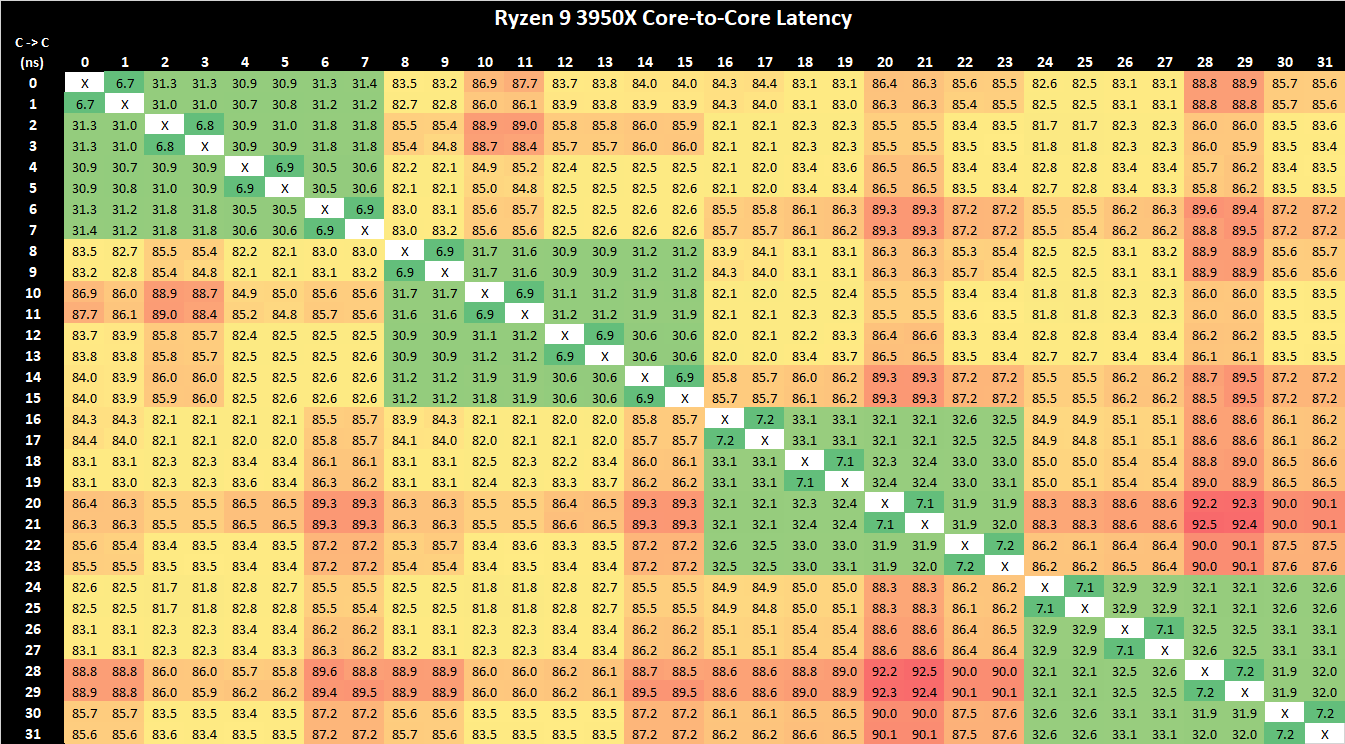
Comparing core to core latencies from Zen 4 (7950X) and Zen 3 (5950X), both are using a two CCX 8-core chiplet design, which is a marked improvement over the four CCX 16-core design featured on the Zen 2 microarchitecture, the Ryzen 9 3950X. The inter-core latencies within the L3 cache range from between 15 ns and 19 ns. The inter-core latencies between different cores within different parts of the CCD show a larger latency penalty of up to 79.5 ns, which is something AMD should work on going forward, but it's an overall improvement in cross CCX latencies compared to Zen 3. Any gain is still a gain.
Even though AMD has opted for a newer and more 'efficient' IOD which is based on TSMC's 6 nm node. It is around the same size physically as the previous AMD IOD on Zen 3 manufactured on GlobalFoundries 12 nm node, but with a much larger transistor count. Within the IOD is the newly integrated RDNA 2 graphics, although this isn't typical iGPU in the sense that an APU is. A lot of the room on the IOD is made up of the DDR5 memory controller or IMC, as well as the chips PCIe 5.0 lanes, and of course, connects to the logic through its primary interconnect named Infinity Fabric. All of these variables play a part on power, latency, and operation.
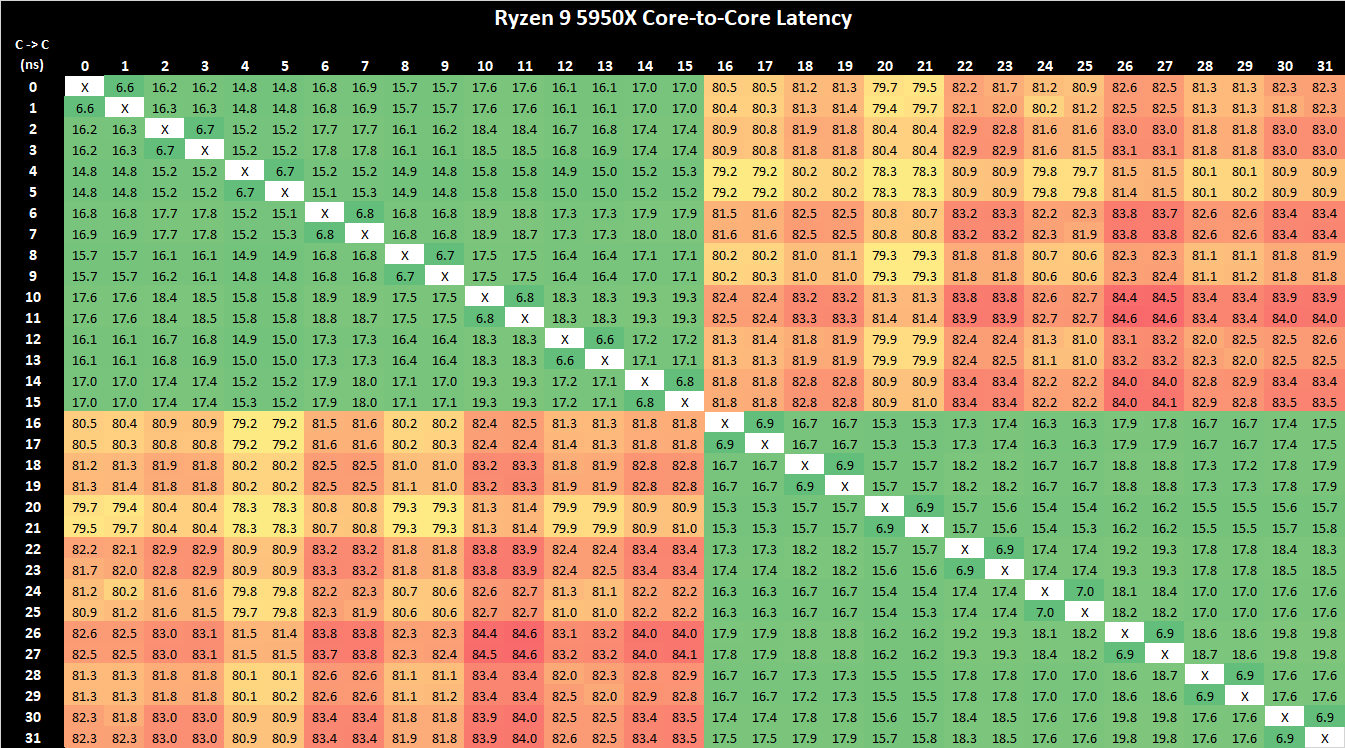
AMD Ryzen 9 5950X Core-to-Core Latency results
It's actually astounding how similar the latency performance of the Ryzen 9 7950X (Zen 4) is when compared directly to the Ryzen 9 5950X (Zen 3), despite being on the new 5 nm TSMC manufacturing process. Even with a change of IOD, but with the same interconnect, the inter-core latencies within the Ryzen 9 7950X are great in terms of cores within the same core complex; latency does degrade when pairing up with a core in another chiplet, but this works and AMD's Ryzen 5000 series proved that the overall penalty performance is negatable.








{kind=link}
205 Comments
View All Comments
spaceship9876 - Monday, September 26, 2022 - link
1. I was hoping you would use a new build of 7-zip as you are using an old version.2. I was hoping you were going to test the idle power consumption when using eco mode so we could compare. Reply
boozed - Monday, September 26, 2022 - link
Sweet Baby Jesus. ReplyArbie - Monday, September 26, 2022 - link
I would really have liked to see Cinebench R23 multi with the 7950X in "105W" mode, for a more direct comparison to the 5950X. But thanks for all the work you did do here, of course. Replynandnandnand - Monday, September 26, 2022 - link
22% better at 65W, 49.7% better at 170W. I'll guess 35-40%. ReplyRezurecta - Monday, September 26, 2022 - link
Absolutely great review!! I love the architectural focus of these articles rather than the '0-60 like' benchmarks of every other site! Would love a memory scaling post as well! Replyaparangement - Monday, September 26, 2022 - link
Would it be better if using 32GB*2 memory instead of 16*2?I remember that Anandtech did a benchmark showing that 32*2 has performance advantage (maybe just using the same kit as in 12900K review? https://www.anandtech.com/show/17047/the-intel-12t... Reply
Jboy1450 - Monday, September 26, 2022 - link
Seems like you handicapped the Zen4 on purpose.Why would you not test at the AMD recommended memory settings? That's what the average user is actually going to use as AMD made it so easy to do. Also, what's with tested with a 2080 ti? Very disappointed and surprised that a well regarded site like yours would make such incomprehensible decisions. Biased maybe? Seems that way. Replyboozed - Monday, September 26, 2022 - link
Not everything has to be a conspiracy ReplyJboy1450 - Tuesday, September 27, 2022 - link
I agree, but coming to a conclusion on a platform where performance is deliberately left on the table (aside from overclocking or using PBO) seems disingenuous. By the same token, why not test AL with DDR4 since most users tend to be budget conscious and will probably choose it over the more expensive DDR5?I mean, I'm simply using their logic. Reply
Oxford Guy - Tuesday, September 27, 2022 - link
‘Most users’ has never been a logical basis for an enthusiast site. It never will be. Reply