Intel 12th Gen Core Alder Lake for Desktops: Top SKUs Only, Coming November 4th
by Dr. Ian Cutress on October 27, 2021 12:00 PM EST- Posted in
- CPUs
- Intel
- DDR4
- DDR5
- PCIe 5.0
- Alder Lake
- Intel 7
- 12th Gen Core
- Z690
Package Improvements
As we move to smaller process nodes, the thermal density of high-performance silicon becomes more of an issue, and so all the processor companies put resources into their mechanical design teams to come up with a solution for the best thermal performance but also comes in line with costs. For example, we’ve seen Intel over the years transition from a soldered down heatspreader, to liquid metal, to basic thermal paste (because saving 0.1 cents means a lot across 70m CPUs), and then all the way back again when customers started demanding it.
However, in that time, we’ve pretty much kept the same socket design for mainstream processors. There hasn’t been much emphasis on changing the design itself for thermomechanical improvements in order to retain reuse and compatibility. There have been some minor changes here and there, such as substrate thinning, but nothing that substantial. The move to a new socket for Alder Lake now gives Intel that opportunity.

For Alder Lake, Intel is using an optimized packaging process to reduce the amount of soldered thermal material used in the processors. Combining that with a thinner die, and Intel is having to increase the thickness of the heatspreader to maintain the required z-height for the platform. The idea here is that the limiting factor in the cooling solution is any time we have a thermal interface, from one material to another – in this case, die to solder, and solder to heatspreader. Solder is the weak point here, so if the heatspreader gets thicker to meet the die, then less solder is needed.
Ultimately direct-die liquid cooling would be the boon here, but Intel has to come up with a solution that fits millions of processors. We have seen Intel offer different packaging solutions based on the SKU itself, so it will be interesting if the mid-range still get the Thin Die + Thin STIM treatment, or if they’ll go back to the cheap thermal paste.
Overclocking: We Have Headroom
It wouldn’t be too much of a leap to say that for most users, the only useful overclocking they might want to look at is enabling XMP on their memory. Modern processors these days are so close to their actual voltage and thermal limits out of the box these days that even if there was 200-300 MHz to gain, especially for the top Core i9 parts, it wouldn’t be worth the +100W it produces. I’m also getting to an age now where I prefer a good stable system, rather than eking out every frame, but having lived in the competitive OC scene for a while, I understand the drive that a lot of those users have to go above and beyond. To that end, Intel is introducing a few new features, and reviving some old ones, for Alder Lake.
Alder Lake also complicates things a bit with the P-core and E-core design.
To start, all the cores on the K/KF parts can be overclocked. The P-cores can be overclocked individually, whereas the E-cores are in groups of four. All the E-cores can be disabled, but at least one P-core needs to be enabled for the system to work (this has interesting consequences for Intel’s design). All cores can have additional AVX offsets, per-core ratio and voltage controls, and the ring/uncore ratios can also be adjusted. Memory also has the bells and whistles mentioned on a previous page. Those with integrated graphics can also be adjusted.
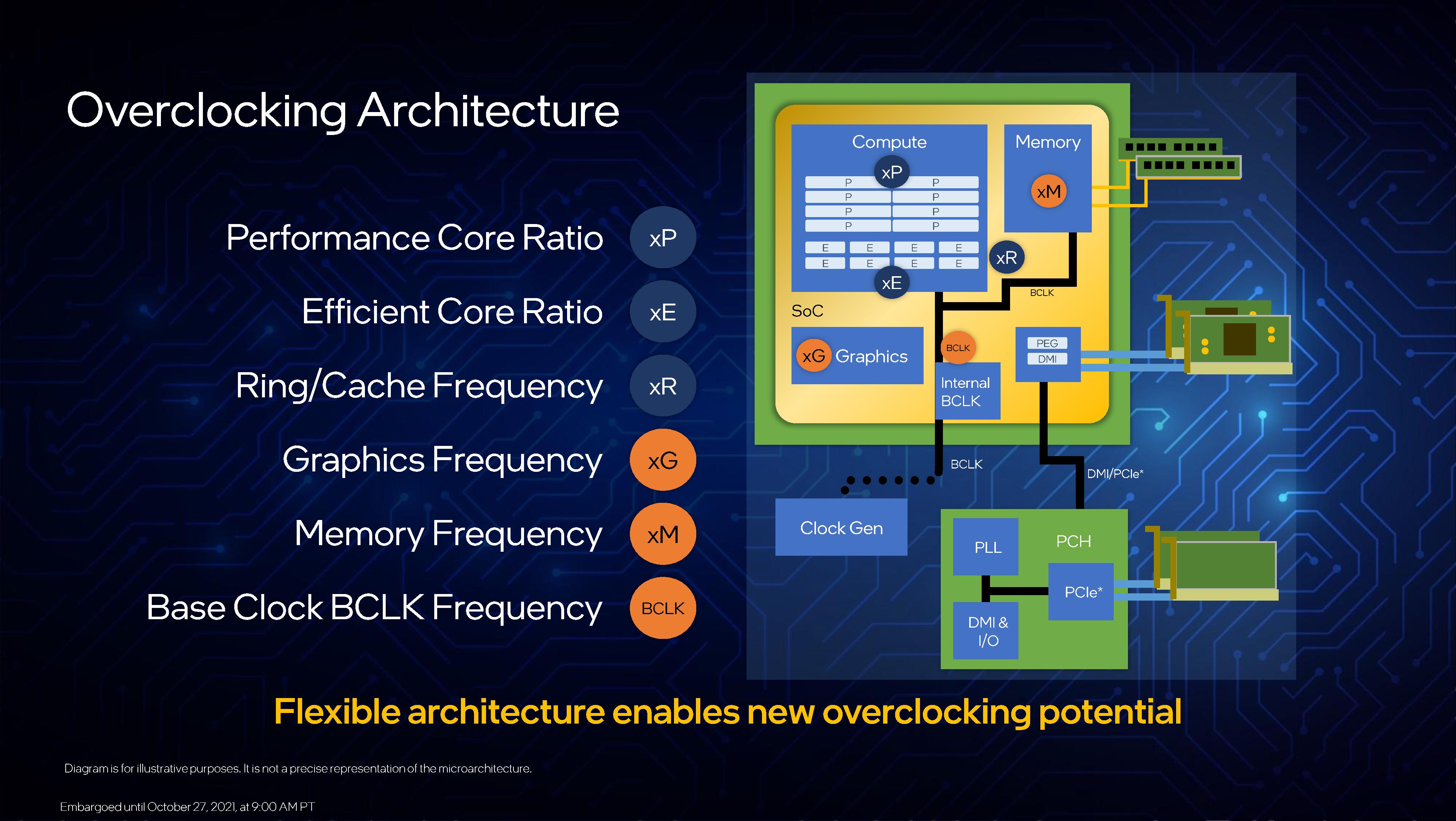
What Alder Lake brings back to the table is BCLK overclocking. For the last decade or so, most overclocking is done with the CPU multiplier, and before that it was BCLK or FSB. Intel is now saying that BCLK overclocking has returned, and this is partly due to motherboard customizations in the clock generator. Every Alder Lake CPU has an internal BCLK/clock generator it can use, however motherboard vendors can also apply an external clock generator. Intel expects only the lowest-end motherboards will not have an external generator.
The use of two generators allows the user to overclock the PCIe bus using the external generator, while maintaining a regular BCLK on other parts of the system with the internal clock. The system can also apply voltage in an adaptive way based on the overclock, with additional PLL overrides.
On top of this, Intel is integrating more user-accessible telemetry for its cores, particularly the E-cores, and real-time frequency analysis. On top of this, users can adjust the memory frequency in the operating system, rather than having to reboot – this is an extension of the memory turbo functionality previously mentioned.
For regular users, Intel is also offering a one-click immediate overclock feature. On launch, the Core i9 will be supported and overclock the P-cores +100 MHz and the E-cores +300 MHz immediately. It sounds like Intel is confident that all CPUs will be able to do this, but they want it to be user selectable. Beyond that, I confirmed the tool does still void the warranty. Intel’s VP dismissed it as an issue, citing that the recent overclocker warranty program they canned had such a low pickup, it wasn’t worth continuing. I’d say that the two things are mutually exclusive, but that’s up to Intel.








395 Comments
View All Comments
yeeeeman - Friday, October 29, 2021 - link
You comparisons at various price points are a good idea, but wrong, because 12600K will fight with 5800X performance wise, hence its efficiency will be judged compared to the 5800X, not with the 5600X, which obviously more efficient than the 5800X.Spunjji - Friday, October 29, 2021 - link
This remains to be seen - Intel rarely go low on price and high on performance. I'll be happy if they've changed that pattern!Carmen00 - Friday, October 29, 2021 - link
Surprised that nobody's talking about the inherent scheduling problems with efficiency+performance cores and desktop workloads. This is NOT a solved problem and is, in fact, very far away from good general-purpose solutions. Your phone/tablet shows you one app at a time, which goes some way towards masking the issues. On a general-purpose desktop, the efficiency+performance split has never been successfully solved, as far as I am aware. You read it right - NEVER! (I welcome links to any peer-reviewed theoretical CS research that shows the opposite.)In the interim, it seems to me that Intel has hitched its wagon to a problem that is theoretically unsolvable and generally unapproachable at the chip level. Scheduling with homogenous cores is unsolvable too, but an easier problem to attack. Heterogenous cores add another layer of difficulty and if Intel's approach is really just breaking things into priority classes ... oh, my. Good luck to them on real-world performance. They'll need it.
I can see why they've done it. They have the tech and they're trying to make the most of their existing tech investment. That doesn't mean it's a good idea. It is relatively easy to make schedulers behave pathologically (e.g. flipping between E/P constantly, or burning power for nothing) during normal app execution and we see this on phones already. Bringing that mess to desktops ... yeah. Not a great idea.
kwohlt - Friday, October 29, 2021 - link
"I welcome links to any peer-reviewed theoretical CS research that shows the opposite"That's not how this works. YOU are making the claim that heterogenous scheduling has never been solved on a general-purpose desktop - the onus would be on your to provide proof of this.
"Scheduling with homogenous cores is unsolvable too"
So if scheduling with heterogenous and homogenous cores is both unsolvable, then what point are you trying to make?
Has apple not demonstrated functional scheduling across a heterogenous architecture with M1?
And what does "solved" look like? Because if your definition of solved is "no inefficiencies or loss", then that's not a realistic expectation. Heterogenous architecture simply needs to provide more benefit than not - a goal of zero overheard of inefficiency is unrealistic.
As long as efficiency and performance gain outpaces the inefficiencies, it's a success. Consider a scenario of 4 efficiency cores occupying the same physical die space, thermal constrains, and power consumption of 4 performant cores - Surely an 8 + 8 design would offer better performance than a 10 + 0 design, when the e cores can offer performance greater than 50% of the P core.
Consider this: a 12600 will be 6 + 0. A 12600K will be 6+4. If we downclock 12600K to match P core frequency of 12600, we can directly measure the benefit of the 4 e cores.
If we disable 4 e cores in the 12700K so it is only 8P cores, and compare that to the 6+4 of the 12600K, if the 12600K is more performant, we can directly show that 6+4 was better than 7+0 in this scenario.
Carmen00 - Wednesday, November 3, 2021 - link
Sure, take a look at this for a good recent overview: https://dl.acm.org/doi/pdf/10.1145/3387110 . (honestly, though, I think you could have found that one for yourself... the research is not hidden!)Again, best of luck to Intel on it; deep learning models or no, they have a risk appetite that I don't share. Apple's success is due, in no small part, to the fact that it controls the entirety of the hardware and software stack. Intel has no such ability. My prediction is that you will have users whose computers sometimes simply start burning power for "no reason", and this can't be replicated in a lab environment; and you will have users whose computers are sometimes just slow, and again, this can't be replicated easily. The result will likely be an intermittently poor user experience. I wouldn't risk buying such a machine myself, and I certainly wouldn't get it for grandma or the kids.
mode_13h - Saturday, October 30, 2021 - link
Good scheduling requires an element of prediction. In the article, they mention Intel took many measurements of many different workloads, in order to train a deep learning model to recognize and classify different usage patterns.PedroCBC - Saturday, October 30, 2021 - link
In the WAN show yesterday Linus said that some DRMs will not work with Alder Lake, most of then old ones but Denuvo also said that it will have some problemsiranterres - Friday, October 29, 2021 - link
Having "efficiency" cores in modern desktop CPU are irrelevant. For laptops is another story.iranterres - Friday, October 29, 2021 - link
*is irrelevantnandnandnand - Friday, October 29, 2021 - link
False. It boosts multicore performance per die area.Intel could have given you 10 big cores instead of 8 big, 8 small. And that would have been a worse chip.