Intel 12th Gen Core Alder Lake for Desktops: Top SKUs Only, Coming November 4th
by Dr. Ian Cutress on October 27, 2021 12:00 PM EST- Posted in
- CPUs
- Intel
- DDR4
- DDR5
- PCIe 5.0
- Alder Lake
- Intel 7
- 12th Gen Core
- Z690
A Hybrid/Heterogeneous Design
Developing a processor with two different types of core is not a new concept – there are billions of smartphones that have exactly that inside them, running Android or iOS, as well as IoT and embedded systems. We’ve also seen it on Windows, cropping up on Qualcomm’s Windows on Snapdragon mobile notebooks, as well as Intel’s previous Lakefield design. Lakefield was the first x86 hybrid design in that context, and Alder Lake is the more mass-market realization of that plan.
A processor with two different types of core disrupts the typical view of how we might assume a computer works. At the basic level, it has been taught that a modern machine is consistent – every CPU has the same performance, processes the same data at the same rate, has the same latency to memory, the same latency to each other, and everything is equal. This is a straightforward homogenous design that’s very easy to write software for.
Once we start considering that not every core has the same latency to memory, moving up to a situation where there are different aspects of a chip that do different things at different speeds and efficiencies, now we move into a heterogeneous design scenario. In this instance, it becomes more complex to understand what resources are available, and how to use them in the best light. Obviously, it makes sense to make it all transparent to the user.

With Intel’s Alder Lake, we have two types of cores: high performance/P-cores, built on the Golden Cove microarchitecture, and high efficiency/E-cores, built on the Gracemont microarchitecture. Each of these cores are designed for different optimization points – P-cores have a super-wide performance window and go for peak performance, while E-cores focus on saving power at half the frequency, or lower, where the P-core might be inefficient.
This means that if there is a background task waiting on data, or something that isn’t latency-sensitive, it can work on the E-cores in the background and save power. When a user needs speed and power, the system can load up the P-cores with work so it can finish the fastest. Alternatively, if a workload is more throughput sensitive than latency-sensitive, it can be split across both P-cores and E-cores for peak throughput.

For performance, Intel lists a single P-core as ~19% better than a core in Rocket Lake 11th Gen, while a single E-core can offer better performance than a Comet Lake 10th Gen core. Efficiency is similarly aimed to be competitive, with Intel saying a Core i9-12900K with all 16C/24T running at a fixed 65 W will equal its previous generation Core i9-11900K 8C/16T flagship at 250 W. A lot of that will be that having more cores at a lower frequency is more efficient than a few cores at peak frequency (as we see in GPUs), however an effective 4x performance per watt improvement requires deeper investigation in our review.
As a result, the P-cores and E-cores look very different. A deeper explanation can be found in our Alder Lake microarchitecture deep dive, but the E-cores end up being much smaller, such that four of them are roughly in the same area as a single P-core. This creates an interesting dynamic, as Intel highlighted back at its Architecture Day: A single P-core provides the best latency-sensitive performance, but a group of E-cores would beat a P-core in performance per watt, arguably at the same performance level.
However, one big question in all of this is how these workloads end up on the right cores in the first place? Enter Thread Director (more on the next page).
A Word on L1, L2, and L3 Cache
Users with an astute eye will notice that Intel’s diagrams relating to core counts and cache amounts are representations, and some of the numbers on a deeper inspection need some explanation.
For the cores, the processor design is physically split into 10 segments.
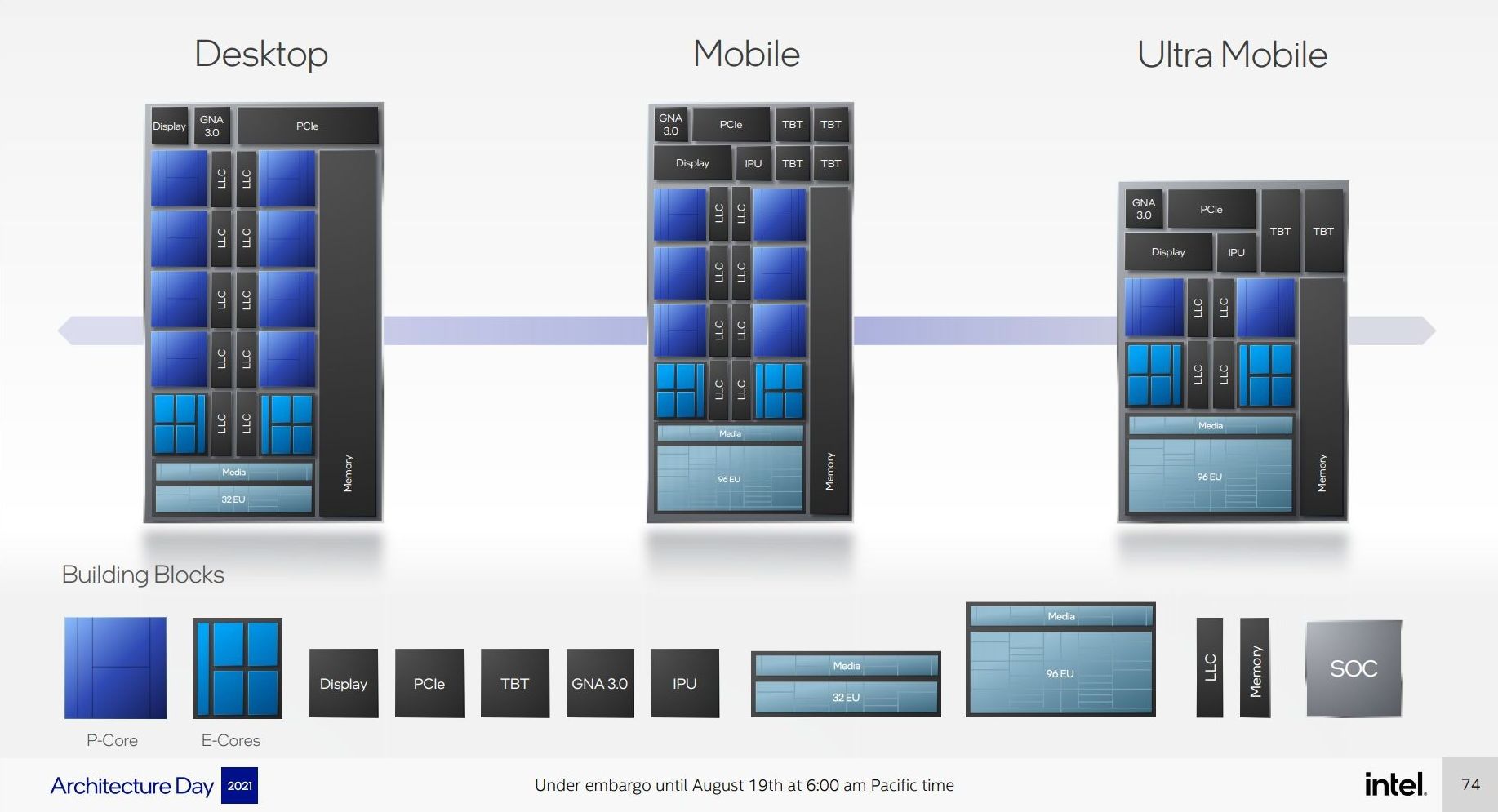
A segment contains either a P-core or a set of four E-cores, due to their relative size and functionality. Each P-core has 1.25 MiB of private L2 cache, which a group of four E-cores has 2 MiB of shared L2 cache.
This is backed by a large shared L3 cache, totaling 30 MiB. Intel’s diagram shows that there are 10 LLC segments which should mean 3.0 MiB each, right? However, moving from Core i9 to Core i7, we only lose one segment (one group of four E-cores), so how come 5.0 MiB is lost from the total L3? Looking at the processor tables makes less sense.
Please note that the following is conjecture; we're awaiting confirmation from Intel that this is indeed the case.
It’s because there are more than 10 LLC slices – there’s actually 12 of them, and they’re each 2.5 MiB. It’s likely that either each group of E-cores has two slices each, or there are extra ring stops for more cache.
Each of the P-cores has a 2.5 MiB slice of L3 cache, with eight cores making 20 MiB of the total. This leaves 10 MiB between two groups of four E-cores, suggesting that either each group has 5.0 MiB of L3 cache split into two 2.5 MiB slices, or there are two extra LLC slices on Intel’s interconnect.
| Alder Lake Cache | |||||||
| AnandTech | Cores P+E/T |
L2 Cache |
L3 Cache |
IGP | Base W |
Turbo W |
Price $1ku |
| i9-12900K | 8+8/24 | 8x1.25 2x2.00 |
30 | 770 | 125 | 241 | $589 |
| i9-12900KF | 8+8/24 | 8x1.25 2x2.00 |
30 | - | 125 | 241 | $564 |
| i7-12700K | 8+4/20 | 8x1.25 1x2.00 |
25 | 770 | 125 | 190 | $409 |
| i7-12700KF | 8+4/20 | 8x1.25 1x2.00 |
25 | - | 125 | 190 | $384 |
| i5-12600K | 6+4/20 | 6x1.25 1x2.00 |
20 | 770 | 125 | 150 | $289 |
| i5-12600KF | 6+4/20 | 6.125 1x200 |
20 | - | 125 | 150 | $264 |
This is important because moving from Core i9 to Core i7, we lose 4xE-cores, but also lose 5.0 MiB of L3 cache, making 25 MiB as listed in the table. Then from Core i7 to Core i5, two P-cores are lost, totaling another 5.0 MiB of L3 cache, going down to 20 MiB. So while Intel’s diagram shows 10 distinct core/LLC segments, there are actually 12. I suspect that if both sets of E-cores are disabled, so we end up with a processor with eight P-cores, 20 MiB of L3 cache will be shown.








395 Comments
View All Comments
yeeeeman - Friday, October 29, 2021 - link
You comparisons at various price points are a good idea, but wrong, because 12600K will fight with 5800X performance wise, hence its efficiency will be judged compared to the 5800X, not with the 5600X, which obviously more efficient than the 5800X.Spunjji - Friday, October 29, 2021 - link
This remains to be seen - Intel rarely go low on price and high on performance. I'll be happy if they've changed that pattern!Carmen00 - Friday, October 29, 2021 - link
Surprised that nobody's talking about the inherent scheduling problems with efficiency+performance cores and desktop workloads. This is NOT a solved problem and is, in fact, very far away from good general-purpose solutions. Your phone/tablet shows you one app at a time, which goes some way towards masking the issues. On a general-purpose desktop, the efficiency+performance split has never been successfully solved, as far as I am aware. You read it right - NEVER! (I welcome links to any peer-reviewed theoretical CS research that shows the opposite.)In the interim, it seems to me that Intel has hitched its wagon to a problem that is theoretically unsolvable and generally unapproachable at the chip level. Scheduling with homogenous cores is unsolvable too, but an easier problem to attack. Heterogenous cores add another layer of difficulty and if Intel's approach is really just breaking things into priority classes ... oh, my. Good luck to them on real-world performance. They'll need it.
I can see why they've done it. They have the tech and they're trying to make the most of their existing tech investment. That doesn't mean it's a good idea. It is relatively easy to make schedulers behave pathologically (e.g. flipping between E/P constantly, or burning power for nothing) during normal app execution and we see this on phones already. Bringing that mess to desktops ... yeah. Not a great idea.
kwohlt - Friday, October 29, 2021 - link
"I welcome links to any peer-reviewed theoretical CS research that shows the opposite"That's not how this works. YOU are making the claim that heterogenous scheduling has never been solved on a general-purpose desktop - the onus would be on your to provide proof of this.
"Scheduling with homogenous cores is unsolvable too"
So if scheduling with heterogenous and homogenous cores is both unsolvable, then what point are you trying to make?
Has apple not demonstrated functional scheduling across a heterogenous architecture with M1?
And what does "solved" look like? Because if your definition of solved is "no inefficiencies or loss", then that's not a realistic expectation. Heterogenous architecture simply needs to provide more benefit than not - a goal of zero overheard of inefficiency is unrealistic.
As long as efficiency and performance gain outpaces the inefficiencies, it's a success. Consider a scenario of 4 efficiency cores occupying the same physical die space, thermal constrains, and power consumption of 4 performant cores - Surely an 8 + 8 design would offer better performance than a 10 + 0 design, when the e cores can offer performance greater than 50% of the P core.
Consider this: a 12600 will be 6 + 0. A 12600K will be 6+4. If we downclock 12600K to match P core frequency of 12600, we can directly measure the benefit of the 4 e cores.
If we disable 4 e cores in the 12700K so it is only 8P cores, and compare that to the 6+4 of the 12600K, if the 12600K is more performant, we can directly show that 6+4 was better than 7+0 in this scenario.
Carmen00 - Wednesday, November 3, 2021 - link
Sure, take a look at this for a good recent overview: https://dl.acm.org/doi/pdf/10.1145/3387110 . (honestly, though, I think you could have found that one for yourself... the research is not hidden!)Again, best of luck to Intel on it; deep learning models or no, they have a risk appetite that I don't share. Apple's success is due, in no small part, to the fact that it controls the entirety of the hardware and software stack. Intel has no such ability. My prediction is that you will have users whose computers sometimes simply start burning power for "no reason", and this can't be replicated in a lab environment; and you will have users whose computers are sometimes just slow, and again, this can't be replicated easily. The result will likely be an intermittently poor user experience. I wouldn't risk buying such a machine myself, and I certainly wouldn't get it for grandma or the kids.
mode_13h - Saturday, October 30, 2021 - link
Good scheduling requires an element of prediction. In the article, they mention Intel took many measurements of many different workloads, in order to train a deep learning model to recognize and classify different usage patterns.PedroCBC - Saturday, October 30, 2021 - link
In the WAN show yesterday Linus said that some DRMs will not work with Alder Lake, most of then old ones but Denuvo also said that it will have some problemsiranterres - Friday, October 29, 2021 - link
Having "efficiency" cores in modern desktop CPU are irrelevant. For laptops is another story.iranterres - Friday, October 29, 2021 - link
*is irrelevantnandnandnand - Friday, October 29, 2021 - link
False. It boosts multicore performance per die area.Intel could have given you 10 big cores instead of 8 big, 8 small. And that would have been a worse chip.