Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM ESTConclusions
Alder Lake is set to come to market for both desktop and mobile, and we’re expecting the desktop hardware to start to appear by the end of the year – perhaps a little later for the rest of the family, but all-in-all we expect Intel is experiencing some serious squeaky bum time regarding how all the pieces will fit in place at that launch. The two main critical factors are operating systems and memory.
Because Alder Lake is Intel’s first full-stack attempt to commercialize a hybrid design, it has had to work closely with Microsoft to enable all the features it needs to make managing a hybrid core design properly beneficial to users. Intel’s new Thread Director Technology couples an integrated microcontroller per P-core and a new API for Windows 11 such that the scheduler in the operating system can take hints about the workflow on the core at a super fine granularity – every 30 microseconds or so. With information about what each thread is doing (from heavy AVX2 down to spin lock idling), the OS can react when a new thread needs performance, and choose which threads need to be relegated down to the E-core or as a hyperthread (which is classified as slower than an E-core).

When I first learned Alder Lake was going to be a hybrid design, I was perhaps one of the most skeptical users about how it was going to work, especially with some of the limits of Windows 10. At this point today however, with the explanations I have from Intel, I’m more confident than not that they’ve done it right. Some side off-the-record conversations I have had have only bolstered the idea that Microsoft has done everything Intel has asked, and users will need Windows 11 to get that benefit. Windows 10 still has some Hardware Guided Scheduling, but it’s akin to only knowing half the story. The only question is whether Windows 11 will be fully ready by the time Alder Lake comes to market.
For memory, as a core design, Alder Lake will have support for DDR4 and DDR5, however only one can be used at any given time. Systems will have to be designed for one or the other – Intel will state that by offering both, OEMs will have the opportunity to use the right memory at the right time for the right cost, however the push to full DDR5 would simplify the platform a lot more. We’re starting to see DDR5 come to the consumer market, but not in any volume that makes any consumer sense – market research firms expect the market to be 10% DDR5 by the end of 2022, which means that consumers might have to be stay with DDR4 for a while, and vendors will have to choose whether to bundle DDR5 with their systems. Either way, there’s no easy answer to the question ‘what memory should I use with Alder Lake’.
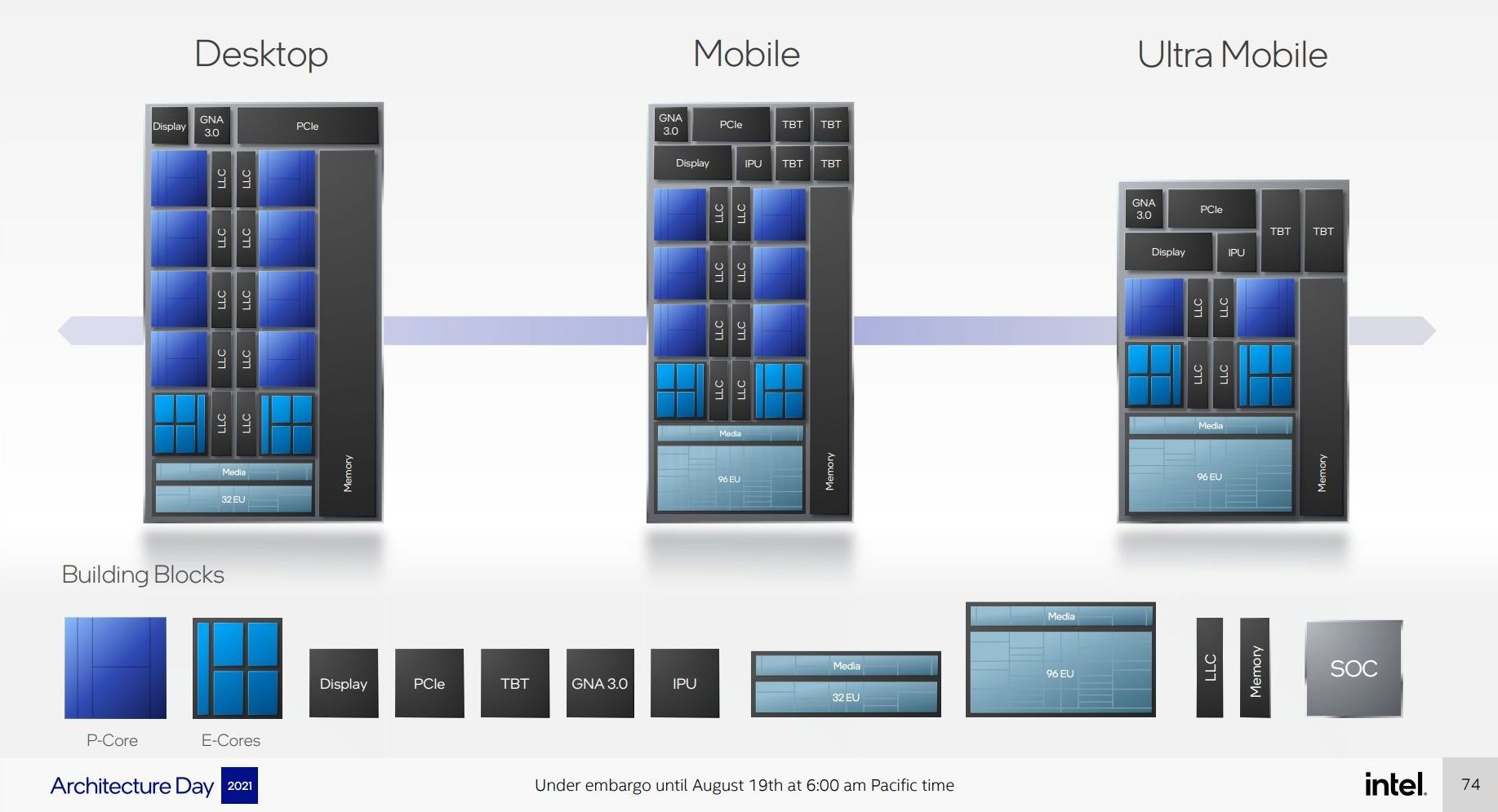
Through The Cores and The Atoms
From a design perspective, both the P-core and E-core are showcasing substantial improvements to their designs compared to previous generations.
The new Golden Cove core has upgraded the front-end decoder, which has been a sticking point for analysis of previous Cove and Lake cores. The exact details of how they operate are still being kept under wraps, but having a 6-wide variable length decoder is going to be an interesting talking point against 8-wide fixed-length decoders in the market and which one is better. The Golden Cove core also has very solid IPC figure gains, Intel saying 19%, although the fact there are some regressions is interesting. Intel did compare Golden Cove to Cypress Cove, the backported desktop core, rather than Willow Cove, the Tiger Lake core, which would have been a more apt comparison given that our testing shows Willow Cove slightly ahead. But still, around 19% is a good figure. Andrei highlights in his analysis that the move from a 10-wide to a 12-wide disaggregated execution back-end should be a good part of that performance, and that most core designs that go down this route end up being good.
However, for Gracemont, Intel has taken that concept to the extreme. Having 17 execution ports allows Intel to clock-gate each port when not in use, and even when you couple that with a smaller 5-wide allocation dispatch and 8-wide retire, it means that without specific code to keep all 17 ports fed, a good number are likely to be disabled, saving power. The performance numbers Intel provided were somewhat insane for Gracemont, suggesting +8% performance over Skylake at peak power, or a variety of 40% ST perf/power or 80% MT perf/power against Skylake. If Gracemont is truly a Skylake-beating architecture, then where have you been! I’m advocating for a 64-core HEDT chip tomorrow.
One harsh criticism Intel is going to get back is dropping AVX-512 for this generation. For the talk we had about ‘no transistor left behind’, Alder Lake dropped it hard. That’s nothing to say if the functionality will come back later, but if rumors are believed and Zen 4 has some AVX-512 support, we might be in a situation where the only latest consumer hardware on the market supporting AVX-512 is from AMD. That would be a turn-up. But AMD’s support is just a rumor, and really if Intel wants to push AVX-512 again, it will have a Sisyphean task to convince everyone it’s what the industry needs.
Where We Go From Here
There are still some unanswered questions as to the Alder Lake design, and stuff that we will test when we get the hardware in hand. Intel has an event planned for the end of October called the Intel InnovatiON event (part of the ON series), which would be the right time to introduce Alder Lake as a product to the world. Exactly when it comes to retail will be a different question, but as long as Intel executes this year on the technology, it should make for an interesting competition with the rest of the market.








223 Comments
View All Comments
TristanSDX - Thursday, August 19, 2021 - link
"decreasing the manufacturing cost for Alder Lake, by using all the defect chips and reserving the good ones for Sapphire Rapids."Alder Lake and Shapire Rapids are two totally diffrerent chips
mode_13h - Thursday, August 19, 2021 - link
> Designed as its third generation of vector instructionsDepends on how you're counting. First is definitely MMX. That was extended in a few subsequent CPUs, but they didn't call those extensions MMX2 or anything. MMX was strictly integer, however, and total vector width was 64 bits. MMX had the annoying feature of reusing the FPU registers, which complicated mixing it with x87 code and basically requiring a state reset, when going from MMX -> x87 code.
Then, SSE came along and added single-precision floating-point. It also added a distinct set of vector registers, which were 128 bits. Finally, it included scalar single-precision arithmetic operations, beginning the era of x87's obsolescence.
SSE2 followed with double-precision and integer operations, making MMX obsolete and further replacing x87 functionality.
SSE3, the wondefully-named SSSE3, and a couple rounds of SSE4 came along, but all were basically just rounds of various additions to flesh out what SSE/SSE2 introduced.
Then, AVX was introduced as something of a replacement for SSE. AVX registers are 256 bits. Like SSE, AVX was initially just including single-precision floating-point support. And like SSE2, AVX2 added double-precision and integer operations.
Then, Xeon Phi (2nd gen) and Skylake-SP introduced the first variations on AVX-512 support. You can see what a mess AVX-512 is, here:
https://en.wikipedia.org/wiki/AVX-512#CPUs_with_AV...
Anyway, AVX-512 should be considered Intel's FOURTH family of vector computing instructions, in x86. I think the first time they dabbled with vector instructions was in the venerable i860 - a very cool, but also fairly problematic step in the history of computing.
> (AVX is 128-bit, AVX2 is 256-bit, AVX512 is 512-bit),
No, not at all. The register width for AVX and AVX2 is 256 bits, as I explained above.
However, even that is a slight simplification. AVX introduced some refinements in vector programming, such as a more compiler-friendly 3-operand format. Therefore, it was meant to subsume SSE usage, and included support for 128-bit operations. Similarly, AVX-512 introduced further refinements and the capability to use it on 128-bit and 256-bit operands.
For more, see: https://en.wikipedia.org/wiki/AVX-512#Encoding_and...
mode_13h - Thursday, August 19, 2021 - link
One more correction:> Some workloads can be vectorised – multiple bits of consecutive data all require
> the same operation, so you can pack them into a single register and perform it
> all at once with a single instruction.
Intel's vector instruction extensions aren't strictly SIMD. They include horizontal operations that you don't see in classical SIMD processors or most GPUs.
mode_13h - Thursday, August 19, 2021 - link
> One could argue that if the AVX-512 unit was removed from the desktop> cores that they would be a lot smaller
That's what I thought, but the area overhead it added to a Skylake-SP core was estimated at a mere 11%.
https://www.realworldtech.com/forum/?threadid=1932...
Of course, we can't yet know how much of Golden Cove it occupies, but still probably somewhere in that ballpark.
mode_13h - Thursday, August 19, 2021 - link
> Intel isn’t even supporting AVX-512 with a dual-issuePerhaps because AVX-512 doubled the number and size of vector registers. So, just the vector register file alone would grow 4x in size.
Schmide - Thursday, August 19, 2021 - link
64bit packed doubles are in avx as are some 64bit ints. AVX2 filled in a lot of gaps such as full vector operands and reorders. So as much as AVX2 finished off the 32 and 64bit ints (epi) functions. There was already a fair amount in avx.Schmide - Thursday, August 19, 2021 - link
not to be misleading. There were really no usable int functions in avx other than load and store.maroon1 - Thursday, August 19, 2021 - link
Gracemont beats skylake ???? Really ? I'm reading the article correctlySo these small cores are actually very powerful !!
vegemeister - Thursday, August 19, 2021 - link
The hypothetical 8% increase in peak performance seems like wishful thinking to me. The chart looks like "graphic design" marketing wank, not plotted data. I would only go by the printed numbers. That is, at an operating point that matches Skylake peak performance, Gracemont cores use less than 60% of Skylake's power, and if you ran Skylake at that same power, it would have less than 60% of Gracemont's performance.mode_13h - Thursday, August 19, 2021 - link
> I would only go by the printed numbers.Okay, so are those numbers you used hypothetical, or where did you see 60%?
Also, there's no fundamental reason why the ISO-power and ISO-performance deltas should match.