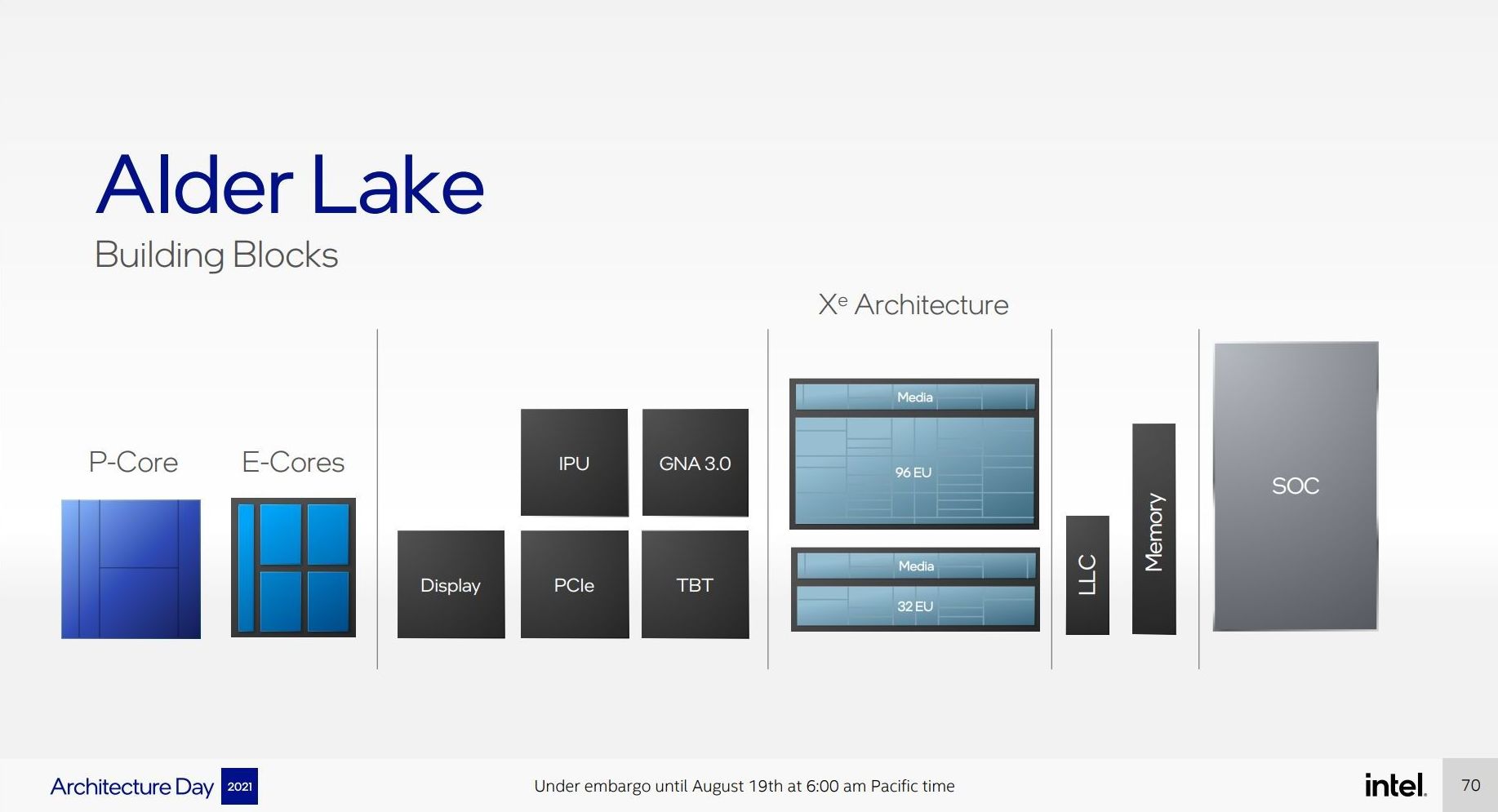
Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM ESTGracemont Microarchitecture (E-Core) Examined
The smaller core as part of Intel’s hybrid Alder Lake design is called an E-core, and is built on the Gracemont microarchitecture. It forms part of Intel’s Atom family of processors, and is a significant microarchitectural jump over the previous Atom core design called Tremont.
- 2008: Bonnell
- 2011: Saltwell
- 2013: Silvermont
- 2015: Airmont
- 2016: Goldmont
- 2017: Goldmont Plus
- 2020: Tremont
- 2021: Gracemont

Based on Intel’s diagrams, the company is pitching that the size of its Golden Cove core means that in the space it would normally fit one of its P-core designs, it can enable a four core cluster of E-cores along with a shared 4MB L2 cache between them.
For performance, Intel has some pretty wild claims. It splits them up into single thread and multi-thread comparisons using SPECrate2017_int.
When comparing 1C1T of Gracemont against 1C1T of Skylake, Intel’s numbers suggest:
- +40% performance at iso-power (using a middling frequency)
- 40% less power* at iso-performance (peak Skylake performance)
*'<40%' is now stood to mean 'below 40 power'
When comparing 4C4T of Gracemont against 2C4T of Skylake, Intel’s numbers suggest:
- +80% performance peak vs peak
- 80% less power at iso performance)peak Skylake performance
We pushed the two Intel slides together to show how they presented this data.
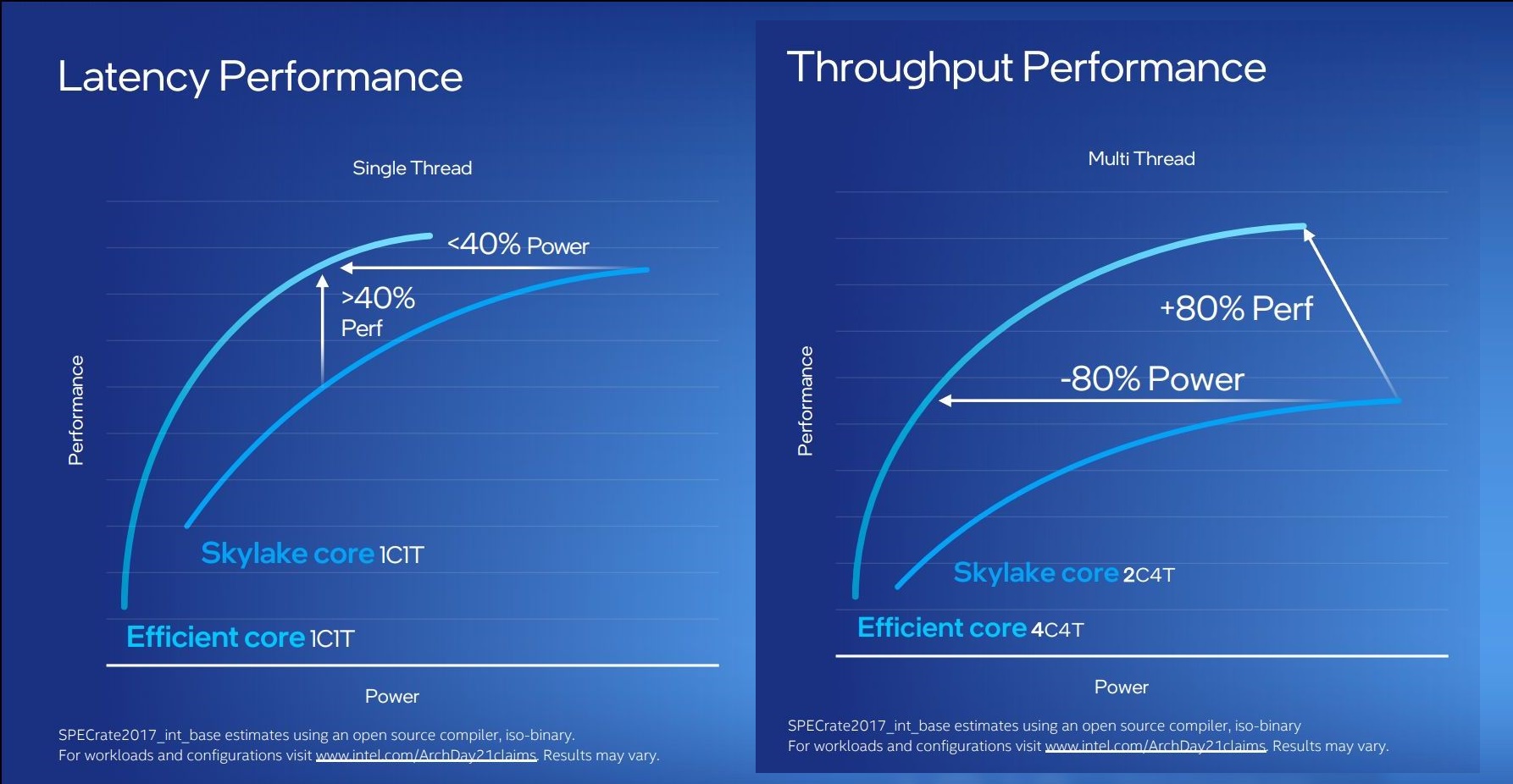
By these graphics it looks like that for peak single thread, we should see around +8% better than Skylake performance while consuming just over half the power – look for Cinebench R20 scores for one Gracemont thread around 478 then (Skylake 6700K scored 443). With +8% for single thread in mind, the +80% in MT comparing 4 cores of Gracemont to two fully loaded Skylake cores seems a little low – we’ve got double the physical cores with Gracemont compared to Skylake here. But there’s likely some additional performance regression with the cache structure on the new Atom core, which we’ll get to later on this page.
These claims are substantial. Intel hasn’t compared the new Atom core generation on generation, because it felt that having AVX2 support would put the new Atom at a significant advantage. But what Intel is saying with these graphs is that we should expect better-than Skylake performance at much less power. We saw Skylake processors up to 28 cores in HEDT – it makes me wonder if Intel might not enable its new Atom core for that market. If that’s the case, where is our 64-core Atom version for HEDT? I’ll take one.
Front End
The big item about the Tremont front end of the core was the move to dual three-wide decode paths, enabling two concurrent streams of decode that could support 3 per cycle. That still remains in Gracemont, but is backed by a double-size 64 KB L1 Instruction cache. This ties into the branch predictor which enables prefetchers at all cache levels, along with a 5000-entry branch target cache which Intel says in improved over the previous generation.

Back on the decoder, Intel supports on-demand decode which stores a history of previous decodes in the instruction cache and if recent misses are recalled at the decode stage, the on-demand stream will pull directly from the instruction cache instead, saving time – if the prefetch/decode works, the content in the instruction cache is updated, however if it is doing poorly then the scope is ‘re-enabled for general fetches’ to get a better understanding of the instruction flow. This almost sounds like a micro-op cache without having a physical cache, but is more to do about instruction streaming. Either way, the decoders can push up to six uops into the second half of the front end.
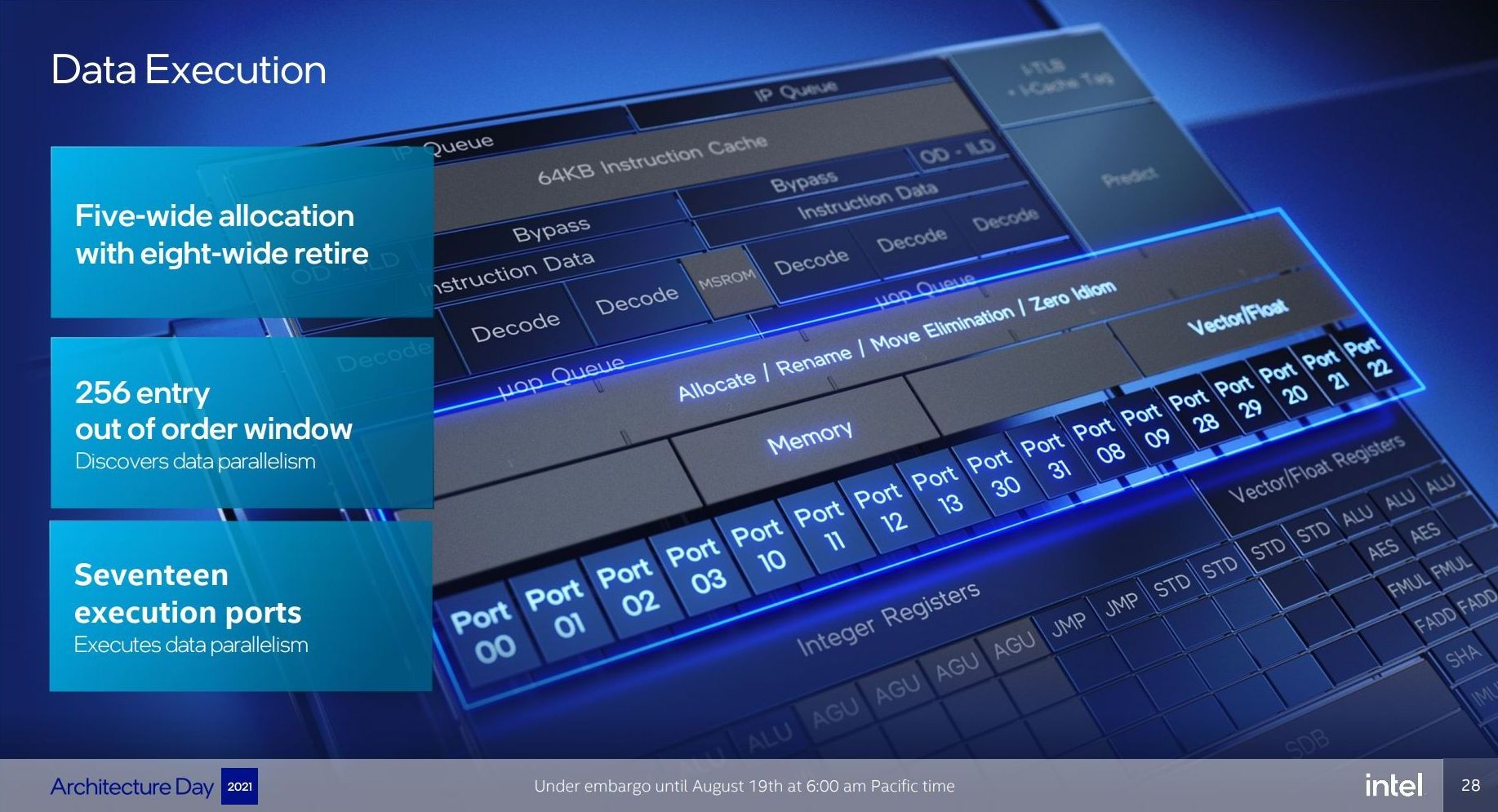
For Gracemont, the reorder buffer size has increased from 208 in Tremont to 256, which is important aspect given that Gracemont now has a total of 17 (!) execution ports, compared to eight in Tremont. This is also significantly wider than the execution capabilities of Golden Cove's 12 ports, related to the disaggregated integer and FP/vector pipeline design. However, despite that width, the allocation stage feeding into the reservation stations can only process five instructions per cycle. On the return path, each core can retire eight instructions per cycle.
Back End
So it’s a bit insane to have 17 execution ports here. There are a lot of repeated units as well, which means that Gracemont is expecting to see repeated instruction use and requires the parallelism to do more per cycle and then perhaps sit idle waiting for the next instructions to come down the pipe. Overall we have
- 4 Integer ALUs (ALU/Shift), two of which can do MUL/DIV
- 4 Address Generator Units, 2 Load + 2 Store
- 2 Branch Ports
- 2 Extra Integer Store ports
- 2 Floating Point/Vector store ports
- 3 Floating Point/Vector ALUs: 3x ALUs, 2x AES/FMUL/FADD, 1x SHA/IMUL/FDIV
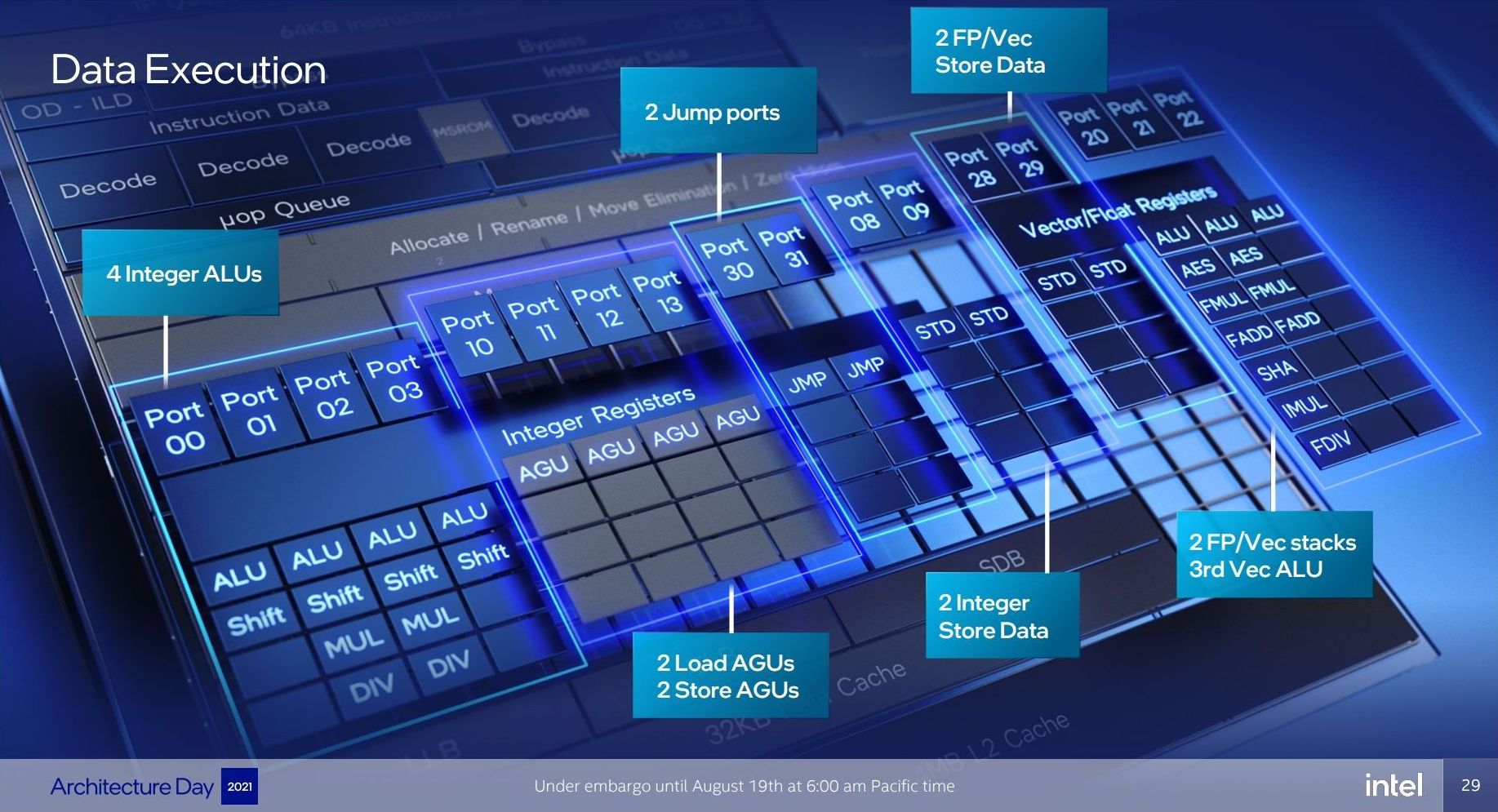
It will be interesting to see exactly how many of these can be accessed simultaneously. In previous core designs a lot of this functionality would be enabled though the same port – even Alder Lake’s P-core only has 12 execution ports, with some ports doing double duty on Vector and Integer workloads. In the P-core there is a single scheduler for both types of workloads, whereas in the E-core there are two separate schedulers, which is more akin to what we see on non-x86 core designs. It’s a tradeoff in complexity and ease-of-use.

The back-end is support by a 32 KiB L1-Data cache, which supports a 3-cycle pointer chasing latency and 64 outstanding cache misses. There are two load and two store ports, which means 2x16 byte loads and 2 x 16 byte stores to the L1-D.
There is also has a shared 4 MB L2 cache across all four E-cores in a cluster with 17-cycle latency. The shared L2 cache can support 64 bytes per cycle read/write per core, which Intel states is sufficient for all four cores. The new L2 supports up to 64 outstanding misses to the deeper memory subsystem – which seems fair, but has to be shared amongst the 4 cores.
Intel states that it has a Resource Director that will arbitrate cache accesses between the four cores in a cluster to ensure fairness, confirming that Intel are building these E-cores in for multi-threaded performance rather than latency sensitive scenarios where one thread might have priority.
Other Highlights
As the first Atom core to have AVX2 enabled, there are two vector ports that support FMUL and FADD (port 20 and port 21), which means that we should expect peak performance compared to previous Atoms to be substantial. The addition of VNNI-INT8 over the AVX unit means that Intel wants these E-cores to enable situations where high inference throughput is needed, such as perhaps video analysis.
Intel was keen to point out that Gracemont has all of its latest security features including Control Flow Enhancement Technology (CET), and virtualization redirects under its VT-rp feature.
Overall, Intel stated that the E-cores are tuned for voltage more than anything else (such as performance, area). This means that the E-cores are set to use a lot less power, which may help in mobile scenarios. But as mentioned before on the first page, it will depend on how much power the ring has to consume in that environment - it should be worth noting that each four core Atom cluster only has a single stop on the full ring in Alder Lake, which Intel says should not cause congestion but it is a possibility – if each core is fully loaded, there is only 512 KB of L2 cache per core before making the jump to main memory, which indicates that in a fully loaded scenario, that might be a bottleneck.








223 Comments
View All Comments
zamroni - Friday, August 20, 2021 - link
That low power cores for desktop is waste of transistors.They are better to be used for more caches or more performance cores
mode_13h - Friday, August 20, 2021 - link
This is what I thought, until I realized that they have better perf/area than the big cores. Not to mention perf/W.So, in highly-threaded workloads, their 8+8 core configuration should out-perform 10 cores of Golden Cove. And, when thermally-limited, the little cores will also more than pull their weight.
It's an interesting experiment they're trying. I'm interested in seeing how it plays out, in the real world.
nevcairiel - Friday, August 20, 2021 - link
> Designed as its third generation of vector instructions (AVX is 128-bit, AVX2 is 256-bit, AVX512 is 512-bit)SSE is 128-bit. AVX is 256-bit FP, AVX2 is 256-bit INT.
And MMX was 64-bit before that. So doesn't this make it the 4th generation, assuming you don't count all the SSE versions separately? (The big ones were SSE1 with 128-bit FP, and SSE2 with 128-bit INT, SSE3/SSSE3/SSE4.1 are only minor extensions)
mode_13h - Saturday, August 21, 2021 - link
Yeah, I came to the same conclusion. It's the 4th major family of vector instructions. Or, another way to clearly demarcate it would be the 4th vector width.abufrejoval - Friday, August 20, 2021 - link
I wonder how many side channel attacks the power director will enable.Also wonder if the lack of details is due to Intel stepping awfully close to some of Apple's patents.
The battles between the Big little and AVX-512 teams inside Intel must have been epic: I imagine frothing red faces all around...
mode_13h - Saturday, August 21, 2021 - link
> The battles between the Big little and AVX-512 teams inside Intel must have been epic: )
Although, the AVX-512 folks have some egg on their faces from a problematic implementation in Skylake-SP and its derivatives.
abufrejoval - Friday, August 20, 2021 - link
Does Big-little make any sense on a "desktop"?And then: Are there actually still any desktops around?
All around my corporate workplaces, notebooks have become the de-facto desktop for many depreciation cycles, mostly because personal offices got replaced by open space and home-office days became a regular thing far before the pandemic. Since then even 'workstations' just became bigger notebooks.
Anywhere else I look it's becoming hard to detect desktops, even for big-screen & multi-monitor setups, it's mostly NUCs or in-screen devices these days.
Those latter machines rarely seem to get turned off any more and I guess many corporate laptops will remain 'turned on' (= stay in some sort of slumber) most of the time, too, so there Big-little overall power consumption might drop vs. Big-only, when both no longer sleep deeply.
Supposedly that makes all these voice commands possible, but try as I might, I can see no IT admin turning that on in an office, nor would I want that in my living room.
The only place I still see 'desktops' are really gamer machines and for those it's hard to see how those small cores might have any significant energy budget impact, even while they are used for ordinary 2D stuff.
For micro-servers Big-little seems much more useful, but Intel typically has gone a long way to ensure that 'desktop' CPUs were not used for that.
Intel's desire for market differentiation seems the major factor behind this and many other features since MMX, but given an equal price choice, I cannot imagine preferring the use of AVX-512 for dark silicon and two P-core tiles for eight E-cores over a fully enabled ten P-core chip.
And I'd belive that most 'desktop' users would prefer the same.
mode_13h - Saturday, August 21, 2021 - link
> The only place I still see 'desktops' are really gamer machinesWe still use traditional desktops for software development and VMs for testing. Our software takes long enough to build and the test environment needs to boot a full image. So, a proper desktop isn't hard to justify.
abufrejoval - Saturday, August 21, 2021 - link
Our developers are encouraged to use build servers and the automatic testing pipelines behind them. Those run on machines with hundreds of GB of RAM and dozens of CPU cores, where loads get distribued via the framework. The QA tests will use containers or VMs as required, which are built and torn down to match by the pipeline. With thousands of developers in the company, that tends to give both better performance to any developer and much better economy to the company, while (home-)offices stay cool and quiet. We still give them laptops with what used to be "desktop" specs (32GB RAM, i7 quads), because, well they're cheap enough, and it allows them to play with VMs locally, even offline, should they want to e.g. for education/self-study.These days when you're running a build farm on your "desktop", that may really more of a workstation. It may be the "economy" model, which means from a price point it's what used to be a desktop, in my home-lab case a Ryzen 7 5800X 8-core with an RTX 2080ti and 128GB ECC RAM that runs whisper quiet even at full load. It would have been a 16-Core 5950X today, but when I built it, those were impossible to get. It's still an easy upgrade and would get you 16 "P-cores" on the cheap. It's also pretty much a gamer's rig, which is why I also use it after hours.
My other home-lab workstation is what used to be a "real workstation" some years ago, an 18-core Haswell E5-2696 v3, which has exactly the same performance as the Ryzen 7 5800X on threaded jobs, even uses the same 110 Watts of power, but much lower clocks (2.7 vs. 4.4 GHz all-cores). Also 128GB of ECC RAM and thankfully just as quiet. It's not so great at gaming, because it only clocks to 4 GHz for single/dual core loads with Haswell IPC and I've yet to find a game that's capable of using 18-cores for profit to balance that out.
Today you would use a Threadripper in that ballpark, with an easy 64 "P-Cores" and matching RAM, pretty much the same computing capacity as a mid-range server, but much quieter and typically tolerable in a desktop/office setup.
If threaded software builds were all you do, you'd want to use 64 E-Cores on the "economy" variant and 256 E-Cores on the "premium", much like Ian hinted, because as long as you can fully load those 256 cores for your builds, they would be faster overall. But the chances for that happening are vastly bigger on a shared server than on a dedicated desktop, which is why we see all these ARM servers going for extra cores at the price of max single threaded performance.
As a thought experiment imagine a machine where tiles can be switched dynamically between being a single P-core or four E-cores. For embarrassingly parallel workloads, the E-Cores would give you both better Watt economy (if you can maintain full load or your idle power consumption is perfect) and faster finish times. But as soon as your workload doesn't go beyond the number of P-cores you can configure, finishing times will be better on P-cores, while power effiency very much gets lost in idle power demands.
The only way to get that re-configurability is to use shared servers, cloud or DC, while a fixed allocation of P vs E cores on a desktop has a much harder time to match your workload.
I can tell you that I much prefer working on the 5800X workstation these days, even if it's no faster for the builds. Beause it's twice as fast on all those scalar workloads. And no matter how much most stuff tries to go wide and thready, Amdahl's law still holds true and that where P-Cores help.
mode_13h - Sunday, August 22, 2021 - link
> Our developers are encouraged to use build serversWe use VM servers, but they're old and the VMs are spec'd worse than desktops. So, there's no real incentive to use them for building. And if you're building on a desktop in your home, then testing on a server-based VM means copying the image over the VPN. So, almost nobody does that, either.
VM servers are a nice idea, but companies often balk at the price tag. New desktops every 4-5 years is an easier pill to swallow, especially because upgrades are staggered.
> I much prefer working on the 5800X workstation these days,
> even if it's no faster for the builds. Beause it's twice as fast on all those scalar workloads.
Exactly. Most incremental compilation involves relatively few files. I do plenty of other sequential tasks, as well.