AMD EPYC Milan Review Part 2: Testing 8 to 64 Cores in a Production Platform
by Andrei Frumusanu on June 25, 2021 9:30 AM ESTSPECjbb MultiJVM - Java Performance
Moving on from SPECCPU, we shift over to SPECjbb2015. SPECjbb is a from ground-up developed benchmark that aims to cover both Java performance and server-like workloads, from the SPEC website:
“The SPECjbb2015 benchmark is based on the usage model of a worldwide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations. It exercises Java 7 and higher features, using the latest data formats (XML), communication using compression, and secure messaging.
Performance metrics are provided for both pure throughput and critical throughput under service-level agreements (SLAs), with response times ranging from 10 to 100 milliseconds.”
The important thing to note here is that the workload is of a transactional nature that mostly works on the data-plane, between different Java virtual machines, and thus threads.
We’re using the MultiJVM test method where as all the benchmark components, meaning controller, server and client virtual machines are running on the same physical machine.
The JVM runtime we’re using is OpenJDK 15 on both x86 and Arm platforms, although not exactly the same sub-version, but closest we could get:
EPYC & Xeon systems:
openjdk 15 2020-09-15
OpenJDK Runtime Environment (build 15+36-Ubuntu-1)
OpenJDK 64-Bit Server VM (build 15+36-Ubuntu-1, mixed mode, sharing)
Altra system:
openjdk 15.0.1 2020-10-20
OpenJDK Runtime Environment 20.9 (build 15.0.1+9)
OpenJDK 64-Bit Server VM 20.9 (build 15.0.1+9, mixed mode, sharing)
Furthermore, we’re configuring SPECjbb’s runtime settings with the following configurables:
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT -Dspecjbb.forkjoin.workers=N -Dspecjbb.forkjoin.workers.Tier1=N -Dspecjbb.forkjoin.workers.Tier2=1 -Dspecjbb.forkjoin.workers.Tier3=16"
Where N=160 for 2S Altra test runs, N=80 for 1S Altra test runs, N=112 for 2S Xeon 8280, N=56 for 1S Xeon 8280, and N=128 for 2S and 1S on the EPYC system. The 75F3 system had the worker count reduced to 64 and 32 for 2S/1S runs, with the 7443, 7343 and 72F3 also having the same thread to core ratiio.
The Xeon 8380 was running at N=140 for 2S Xeon 8380 and N=70 for 1S - the benchmark had been erroring out at higher thread counts.
In terms of JVM options, we’re limiting ourselves to bare-bone options to keep things simple and straightforward:
EPYC & Altra systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC "
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms48g -Xmx48g -Xmn42g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Cascade Lake systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms172g -Xmx172g -Xmn156g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Ice Lake systems (SNC1):
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms192g -Xmx192g -Xmn168g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Ice Lake systems (SNC2):
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms96g -Xmx96g -Xmn84g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
The reason the Xeon CLX system is running a larger back-end heap is because we’re running a single NUMA node per socket, while for the Altra and EPYC we’re running four NUMA nodes per socket for maximised throughput, meaning for the 2S figures we have 8 backends running for the Altra and EPYC and 2 for the Xeon, and naturally half of those numbers for the 1S benchmarks.
For the Ice Lake system, I ran both SNC1 (one NUMA node) as SNC2 (two nodes), with the corresponding scaling in the back-end memory allocation.
The back-ends and transaction injectors are affinitised to their local NUMA node with numactl –cpunodebind and –membind, while the controller is called with –interleave=all.
The max-jOPS and critical-jOPS result figures are defined as follows:
"The max-jOPS is the last successful injection rate before the first failing injection rate where the reattempt also fails. For example, if during the RT-curve phase the injection rate of 80000 passes, but the next injection rate of 90000 fails on two successive attempts, then the max-jOPS would be 80000."
"The overall critical-jOPS is computed by taking the geomean of the individual critical-jOPS computed at these five SLA points, namely:
• Critical-jOPSoverall = Geo-mean of (critical-jOPS@ 10ms, 25ms, 50ms, 75ms and 100ms response time SLAs)
During the RT curve building phase the Transaction Injector measures the 99th percentile response times at each step level for all the requests (see section 9) that are considered in the metrics computations. It then computes the Critical-jOPS for each of the above five SLA points using the following formula:
(first * nOver + last * nUnder) / (nOver + nUnder) "
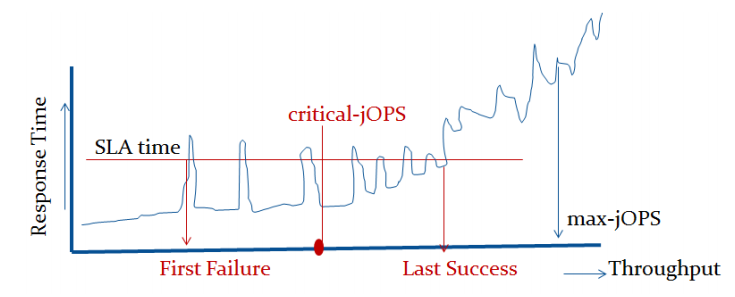
That’s a lot of technicalities to explain an admittedly complex benchmark, but the gist of it is that max-jOPS represents the maximum transaction throughput of a system until further requests fail, and critical-jOPS is an aggregate geomean transaction throughput within several levels of guaranteed response times, essentially different levels of quality of service.
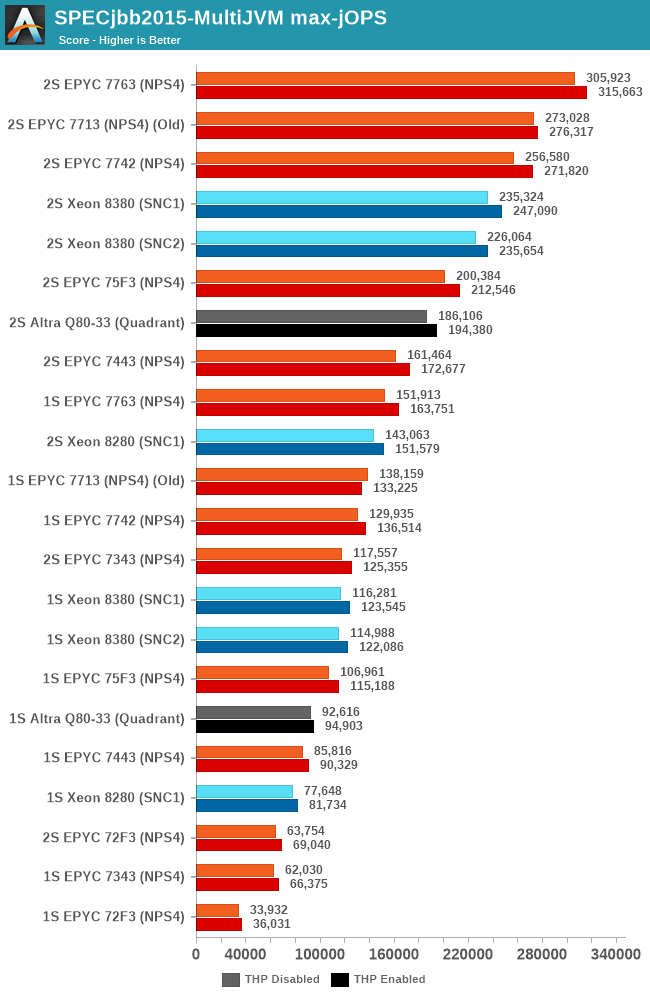
In the max-jOPS metric, the re-tested 7763 increases its throughput by 5%, while the 75F3 oddly enough didn’t see a notable increase.
The 7343 here doesn’t fare quite as well to the Intel competition as in prior tests, AMD’s high core-to-core latency is still a larger bottleneck in such transactional and database-like workloads compared to Intel’s monolithic mesh approach. Only the 7443 manages to have a slight edge over the 28-core Intel SKU.
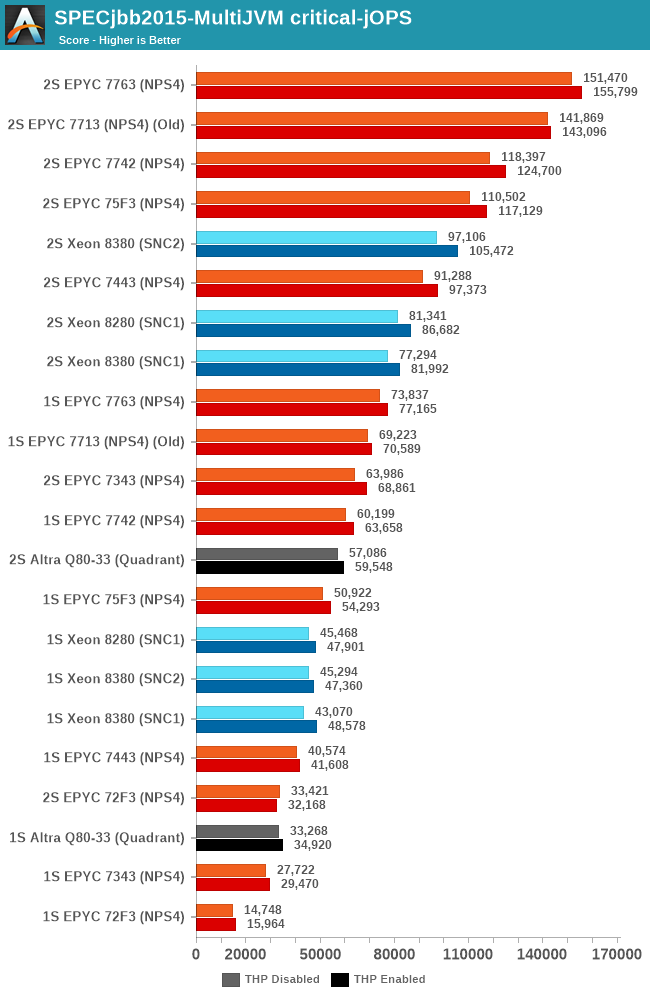
In the critical-jOPS metric, both the 16- and 24-core EPYCs lose out to the 28-core Xeon. Unfortunately we don’t have the Xeon 6330 numbers here due those chips and system being in a different location.








58 Comments
View All Comments
mode_13h - Sunday, June 27, 2021 - link
Thanks for this update. Exciting findings!Gondalf - Sunday, June 27, 2021 - link
SPECint2017 is good but....SPECint2017 Rate to estimate the per-core performance, no no absolutely no. SPECint2017 Rate have a very small dataset and it can not be utilized to estimate the single core performance, we need of the full SPECint2017 workload, the only manner to bypass the crazy L3 of Ryzen. Half the article have a so so sense ( obviously SPEC Rate is very criticized by many and very likely means less than nothing, expeciallly if you rise the bar on L3 ), the other half nope, without sense.In fact Intel claim a new 10nm 32 cores superior than a 32 cores Milan, after all the two cores ( Zen 3 and Willow Cove) have around the same IPC, more or less, and being chiplets, 32 cores Milan is out of the games.
Obviously in this article the world "latency" is hidden or so. A single die solution is always better than chiplet design under load with the same number of cores.
Qasar - Sunday, June 27, 2021 - link
and there is the highly biased anti amd post from gondalf that he is known for." In fact Intel claim a new 10nm 32 cores superior than a 32 cores Milan, after all the two cores ( Zen 3 and Willow Cove) have around the same IPC, more or less, and being chiplets, 32 cores Milan is out of the games. "
yea ok, more pr bs from intel that you blindly believe ? post a link to this. the fact that you start with " in fact intel claim" kind of point to it being bs.
schujj07 - Monday, June 28, 2021 - link
Gandalf missed a link I posed that has a 32c Intel vs 32c AMD. In that the AMD averages 20% better performance than the Intel across the entire test suite. https://www.servethehome.com/intel-xeon-gold-6314u...iAPX - Sunday, June 27, 2021 - link
There's a lot to read and understand on the last chart (per-Thread score / Socket Perf), about usefulness of SMT (or not), about who is the per-Thread performance leader and also the per-Socket performance leader, with a notable exception, the Altra Q80-33.I would like to see these kind of chart more often, it sum-up things very clearly, while naturally you have to understand that it is just a long-story short, and have to read about specific performance depending on the payload (ie: DB as stated).
Kudos!
nordform - Thursday, July 1, 2021 - link
Too bad Apple's M1 was left out ... it clearly would have smoked the "competition". Everything with a TDP higher than 25W is inappropriate, not to say obscene.Apple rules hands down
Qasar - Friday, July 2, 2021 - link
" Everything with a TDP higher than 25W is inappropriate, not to say obscene. " and why would that be ?mode_13h - Friday, July 2, 2021 - link
That would be like drag racing a Tesla car against some 18-wheeled diesel trucks.Server CPUs are not optimized for low-thread performance. They're designed to scale, and have data fabrics to handle massive amounts of I/O that the M1 can't. It wouldn't be a fair (or relevant) comparison.
Now, try running that Tesla car in a tractor pull and we'll see who's laughing!
Oxford Guy - Thursday, July 8, 2021 - link
Happy to have won another debate in which my suggestion was aggressively attacked.I said having dual channel DDR4 for Zen 3 was unfortunate, as DDR4 is so long in the tooth — a fact that dual channel configuration makes more salient. I said it would have been good for the company to add more value by giving it quad channel RAM or, if possible, a support for both DDR4 and DDR5 — something some mainstream Intel quads had (support for DDR3 and DDR4).
My remark was derided mainly on the basis of the claim that dual channel is plenty. This new set of parts demonstrate the benefit of having more RAM and cache.
Considering how high the core counts are for Zen 3 desktop CPUs and how much Apple has set people on notice about what’s possible in CPU performance...
Also, part of the rebuttal was citing the existence of TR. That’s still Zen 2, eh? Can’t really go out and buy that rebuttal.
Is the benefit of being able to stay with the AM4 socket bigger than having less starvation of the CPU, particularly given the very high core counts of CPUs like the 5950? TR may be everyone’s segmentation dream (particularly when it’s being laughingly sold with obsolete Zen 2 and subjected to rapid expensive motherboard orphaning) but I think having five motherboard specs is a bridge too far. Let the low-end have dual channel and no overclocking, dump TR, and consolidate the enthusiast boards to a single (not two) chipset. But... that’s me. I like more value versus little crumbs and redundancies. When a whopping two companies is the state of the competition, though, people become trained to celebrate banality.
mode_13h - Thursday, July 8, 2021 - link
> Zen 3 was unfortunate, as DDR4 is so long in the tooth ...> it would have been good for the company to add more value by giving it quad channel RAM
Agreed. Would've been nice. In spite of that, the 5950X manages to show gains over the 5900X, but we can still wonder how much better it might be with more memory bandwidth.
I wouldn't have an issue with quad-channel being reserved for their TR platform if:
* they were more affordable
* they brought Zen3 to the platform more promptly
An interesting counter-point to consider is how little 8-channel RAM benefitted TR Pro:
"In the tests that matter, most noticeably the 3D rendering tests, we’re seeing a 3% speed-up on the Threadripper Pro compared to the regular Threadripper at the same memory frequency and sub-timings."
https://www.anandtech.com/show/16478/64-cores-of-r...
That's much less benefit than I'd have expected, as a 64-core TR on quad-channel should be far more bandwidth-starved than a 16-core Ryzen on dual-channel. However, that same article features a micro-benchmark which shows the full potential of 8-channel. So, it's obviously workload-dependent.