Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
SPEC CPU - Single-Threaded Performance
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
Single-threaded performance of TGL-H shouldn’t be drastically different from that of TGL-U, however there’s a few factors which can come into play and affect the results: The i9-11980HK TGL-H system has a 200MHz higher boost frequency compared to the i7-1185G7, and a single core now has access to up to 24MB of L3 instead of just 12MB.
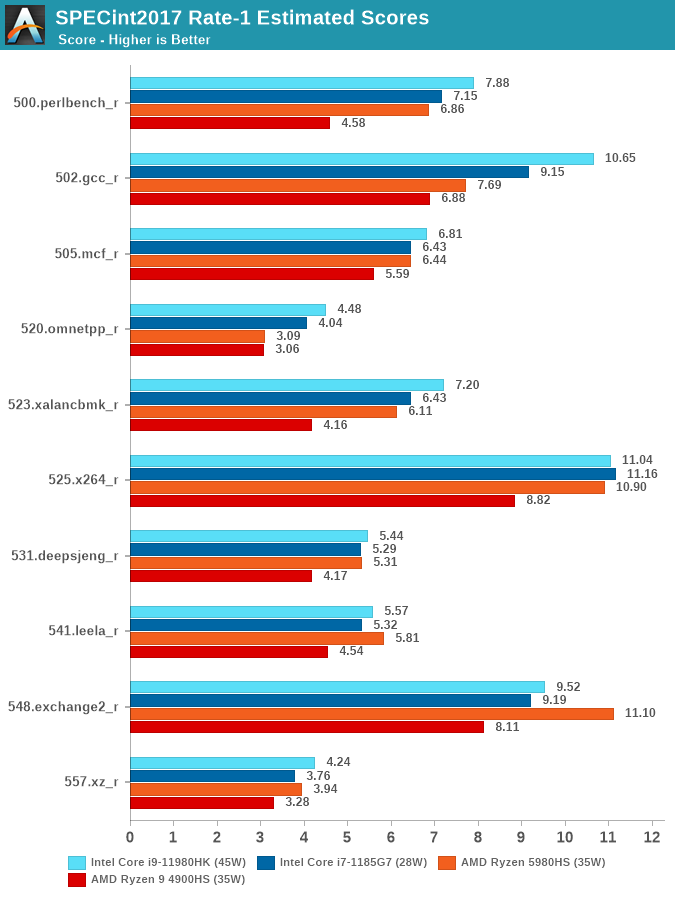
In SPECint2017, the one results which stands out the most if 502.gcc_r where the TGL-H processor lands in at +16% ahead of TGL-U, undoubtedly due to the increased L3 size of the new chip.
Generally speaking, the new TGL-H chip outperforms its brethren and AMD competitors in almost all tests.
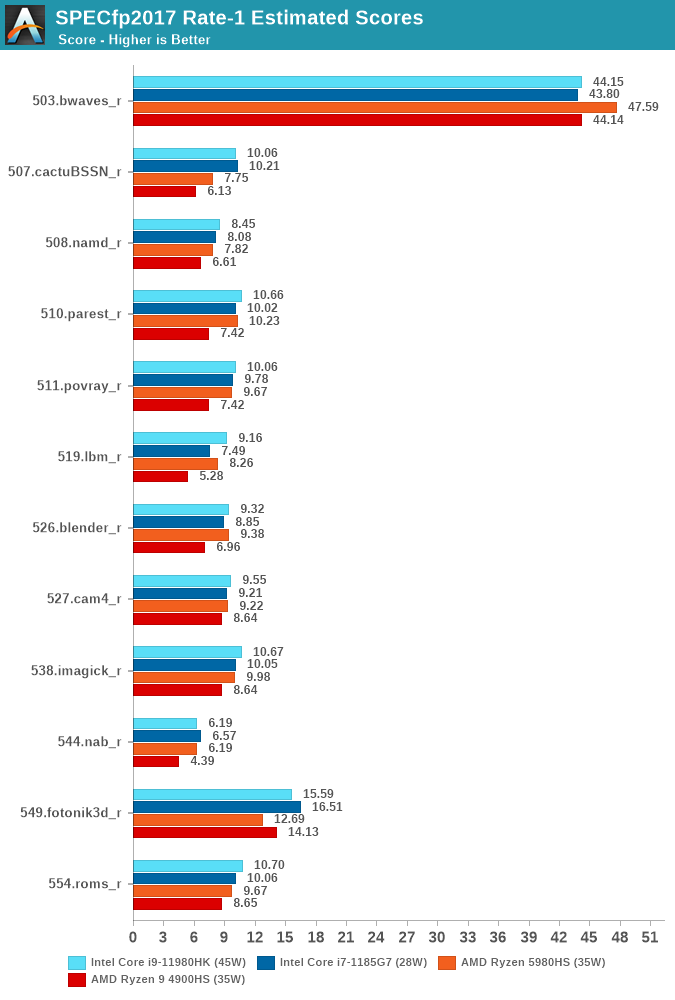
In the SPECfp2017 suite, we also see general small improvements across the board. The 549.fotonik3d_r test sees a regression which is a bit odd, but I think is related to the LPDDR4 vs DDR4 discrepancy in the systems which I’ll get back to in the next page where we’ll see more multi-threaded results related to this.
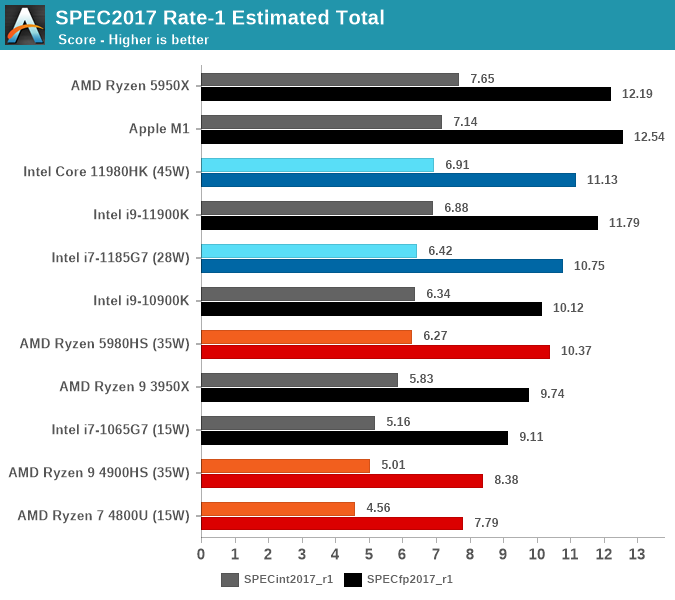
From an overall single-threaded performance standpoint, the TGL-H i9-11980HK adds in around +3.5-7% on top of what we saw on the i7-1185G7, which lands it amongst the best performing systems – not only amongst laptop CPUs, but all CPUs. The performance lead against AMD’s strongest mobile CPU, the 5980HS is even a little higher than against the i7-1185G7, but loses out against AMD’s best desktop CPU, and of course Apple M1 CPU and SoC used in the latest Macbooks. This latter comparison is apples-to-apples in terms of compiler settings, and is impressive given it does it at around 1/3rd of the package power under single-threaded scenarios.








229 Comments
View All Comments
HendoAuScBa - Tuesday, May 18, 2021 - link
How confident are you with that Compile test result? You have the i9-11980HK at 86.9 compiles per day which is a huge jump higher than the best desktop CPUs listed on your benchmark page (the best of which is the i9-11900K at 77).https://www.anandtech.com/bench/CPU-2020/2974
Also, that benchmark page is missing Zen 3 mobile results that you've included in this article.
mode_13h - Tuesday, May 18, 2021 - link
It's eye-catcing, alright. I was also wondering about it.Could it be due to the laptop simply having more RAM or an Optane SSD or something? Mitigations are another thing that comes to mind.
RobJoy - Tuesday, May 18, 2021 - link
Intel is about 1.5 years behind the competition.Once their 5nm fab starts puking out some silicon, we might see them return in the fold.
But that's like 2023 or even 2024.
Until then, accept the fact that Intel HAS competition.
mode_13h - Tuesday, May 18, 2021 - link
> puking out some siliconLOL. I used to work with a guy who used another bodily function as an analogy for the operation of a systolic pipeline. You wouldn't have to think very hard to guess it.
usiname - Tuesday, May 18, 2021 - link
More like 2025, i doubt they will realese just 1 gen with 7nm and will rush to new processdrothgery - Wednesday, May 19, 2021 - link
I wouldn't be shocked to see them rebrand their "7nm" as something with a 5 in it that gets called "5nm" by the press; it wouldn't be unreasonable.LordSojar - Tuesday, May 18, 2021 - link
Good lord the power consumption on these chips... Intel DESPERATELY needs 7nm.usiname - Tuesday, May 18, 2021 - link
You know their 10nm has same transistor density as 7nm TSMC? They don't need new proces, they need new engineersmode_13h - Tuesday, May 18, 2021 - link
> their 10nm has same transistor density as 7nm TSMC?Which 10 nm, though? From what I heard, Ice Lake's density is lower than Cannon Lake's. And I'm not sure if SF or ESF reduced it, further.
Otritus - Wednesday, May 19, 2021 - link
Ice lake having a lower density isn't demonstrative of differences in process density. When designing Sunny Cove, the engineers may not have cared about density, and instead focused on performance and efficiency, resulting in Sunny Cove being less dense than Palm Cove (Cannon Lake). Intel's 10nm being slightly denser than TSMC's 7nm also doesn't mean that it is more efficient. When moving from TSMC's less-dense 7nm to Samsung's more-dense 5nm, mobile SOCs appeared to suffer from a regression in efficiency. Intel needs a node that is both performant and efficient and better engineering because their architectures are clearly less efficient than the competition. Golden Cove might fix Willow Cove's poor density and performance per watt, or we might be waiting till 2023-4 when Intel expects to be properly competitive again.