Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
In terms of the core-to-core tests on the Tiger Lake-H 11980HK, it’s best to actually compare results 1:1 alongside the 4-core Tiger Lake design such as the i7-1185G7:
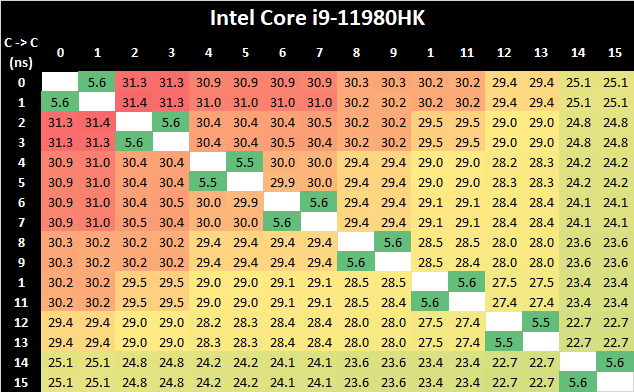

What’s very interesting in these results is that although the new 8-core design features double the cores, representing a larger ring-bus with more ring stops and cache slices, is that the core-to-core latencies are actually lower both in terms of best-case and worst-case results compared to the 4-core Tiger Lake chip.
This is generally a bit perplexing and confusing, generally the one thing to account for such a difference would be either faster CPU frequencies, or a faster clock of lower cycle latency of the L3 and the ring bus. Given that TGL-H comes 8 months after TGL-U, it is plausible that the newer chip has a more matured implementation and Intel would have been able to optimise access latencies.
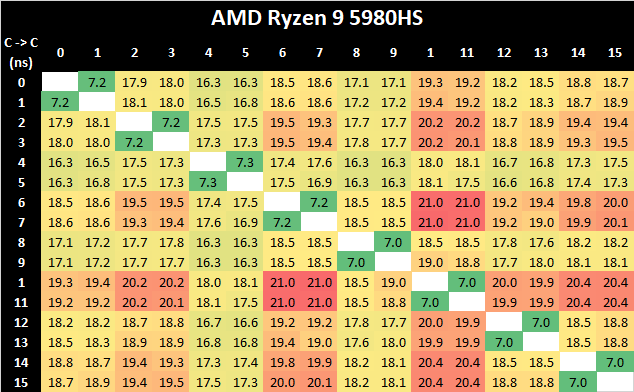
Due to AMD’s recent shift to a 8-core core complex, Intel no longer has an advantage in core-to-core latencies this generation, and AMD’s more hierarchical cache structure and interconnect fabric is able to showcase better performance.
Cache & DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
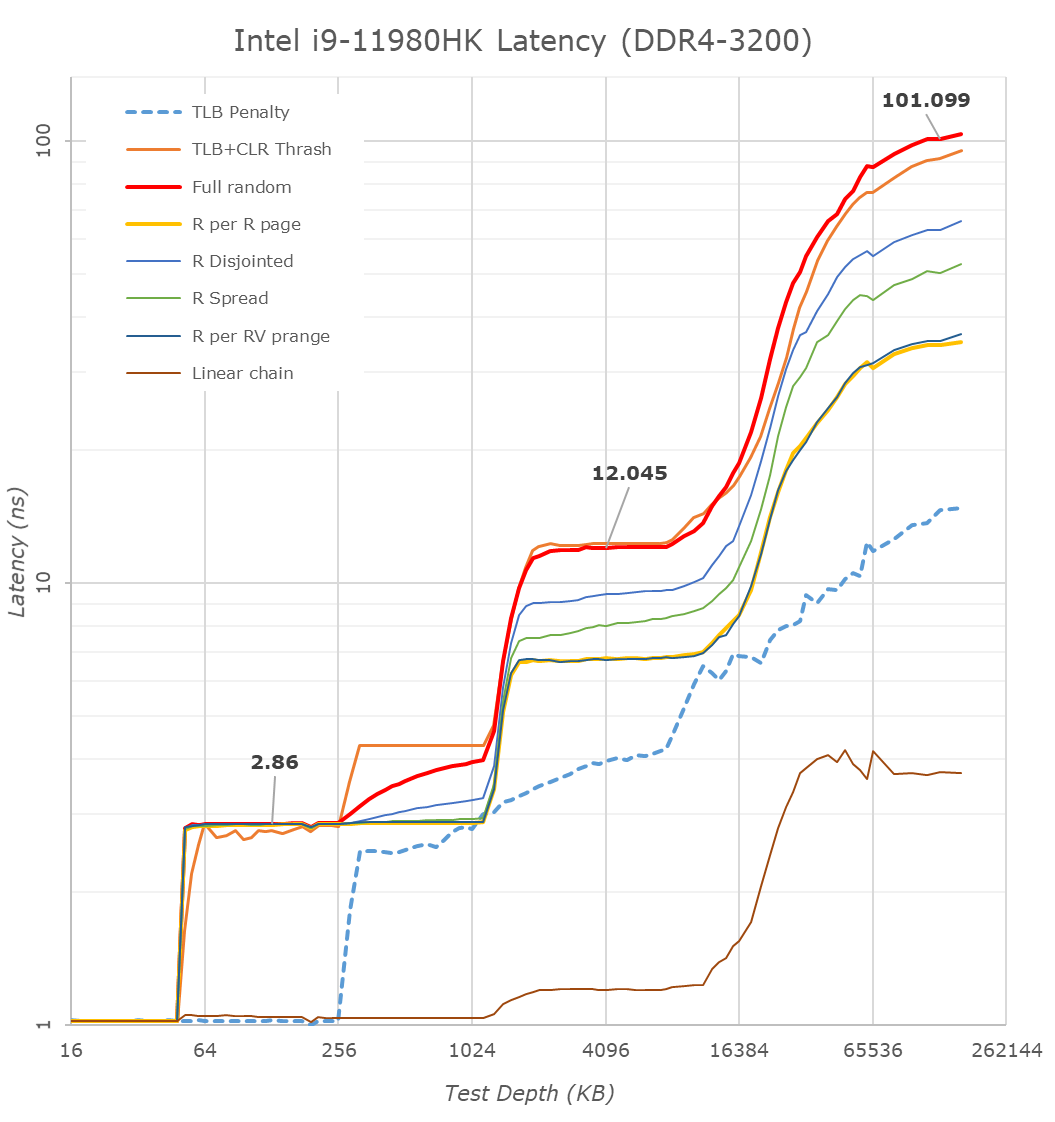
What’s of particular note for TGL-H is the fact that the new higher-end chip does not have support for LPDDR4, instead exclusively relying on DDR4-3200 as on this reference laptop configuration. This does favour the chip in terms of memory latency, which now falls in at a measured 101ns versus 108ns on the reference TGL-U platform we tested last year, but does come at a cost of memory bandwidth, which is now only reaching a theoretical peak of 51.2GB/s instead of 68.2GB/s – even with double the core count.
What’s in favour of the TGL-H system is the increased L3 cache from 12MB to 24MB – this is still 3MB per core slice as on TGL-U, so it does come with the newer L3 design which was introduced in TGL-U. Nevertheless, this fact, we do see some differences in the L3 behaviour; the TGL-H system has slightly higher access latencies at the same test depth than the TGL-U system, even accounting for the fact that the TGL-H CPUs are clocked slightly higher and have better L1 and L2 latencies. This is an interesting contradiction in context of the improved core-to-core latency results we just saw before, which means that for the latter Intel did make some changes to the fabric. Furthermore, we see flatter access latencies across the L3 depth, which isn’t quite how the TGL-U system behaved, meaning Intel definitely has made some changes as to how the L3 is accessed.








229 Comments
View All Comments
Otritus - Monday, May 17, 2021 - link
And that's why if there is an option to run AVX-512, I'd like to see it being run. Also with the massive efficiency deficit of Tiger Lake, and AVX-512 requiring even more power, it's plausible Cezanne might be competitive at the same power limits. Although with NAMD, I'd expect Tiger Lake to top the chart.vyor - Monday, May 17, 2021 - link
That is not how AVX512 works.mode_13h - Monday, May 17, 2021 - link
Depends on how well the compiler can vectorize your workload or if you're using something like OpenMP. However, if I really wanted max performance from AVX-512, I'd be using the intrinsics.BTW, it's worth noting that you can't simply disable AVX-512 with build-time compiler flags, for software that performs runtime code-generation (usually via LLVM). Many popular deep learning frameworks fall in this category.
mode_13h - Monday, May 17, 2021 - link
> Even Skylake-X and cascadelake-X there is a noticeable improvement in performance in AVX-512Not always. Clock throttling is so bad in Skylake SP & Cascade Lake that you need an AVX-512 -heavy workload to see a net-benefit.
zaza - Monday, May 17, 2021 - link
I actually ran that test myself in my university lab. we ran AI workloads and vectorized workloads on avx2 and avx512. Running avx512 on all threads would result in a significant clock drop, but despite this, I was testing 20% faster than AVX 256 (they were using the same power ~200 watts). When you mixing several workloads (AVX and non-AVX), you don't see the same drop unless more than 50% of the cores are running AVX. Granted this is anecdotal evidence, but I think the power budgeting across the chip was working well to maximize performance.mode_13h - Monday, May 17, 2021 - link
> I actually ran that test myself in my university lab. we ran AI workloads and vectorized> workloads on avx2 and avx512. Running avx512 on all threads would result in a
> significant clock drop, but despite this, I was testing 20% faster than AVX 256
> (they were using the same power ~200 watts).
Depends on your network architecture. We saw the opposite, and this was confirmed by engineers at Intel. To resolve the problem, they sent us a patch to disable AVX-512.
> When you mixing several workloads (AVX and non-AVX), you don't see the same drop
> unless more than 50% of the cores are running AVX.
I'm talking specifically about AVX-512. And when I had a lot of threads using it for maybe only 10% of the time (different scenario than above), I also saw clock drops big enough to decrease overall system throughput.
This was all on 14 nm CPUs, so I'm eager to try Intel's 10 nm chips.
mode_13h - Monday, May 17, 2021 - link
> I'm conflicted on your decision to omit AVX-512 on NAMD.Let's remember that this is a notebook processor. Sure, it's what most Intel-based mobile workstations will probably use, but most users of this processor aren't going to be recompiling their apps with -march=native.
In other words, I think the case for testing AVX-512 on this CPU is a lot weaker than on server CPUs or even desktop processors.
ballsystemlord - Monday, May 17, 2021 - link
Good point!Techtree101 - Monday, May 17, 2021 - link
Dwarf Fortress looks like a great benchmark tool for judging heavy single threaded AI/Simulation games?Could I use these benchmark results with it, loosely, to extrapolate what this CPU can do for Civilization VI, Cities Skylines, Minecraft, etc.?
Techtree101 - Monday, May 17, 2021 - link
And Dolphin 5.0 I suppose too.