Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
PPA & ISO Performance Projections
We’ve noted about the microarchitectural changes in the new V1 and N2 processors, as well as their IPC improvements, but it’s important to actually put things into context of the actual performance and power requirements to reach those figures. Arm presented an ISO-process node figures of what we can expect out of the designs:

Starting off, we’re presented with a refresher of where exactly the Neoverse N1 was projected to end up. Back in 2019, the company had noted that an N1 core with 1MB L2 would take roughly 1.4mm² of area, and use up to 1.8W at 3.1GHz (TSMC 7nm node projection).
We’ve generally seen more conservative implementations (Graviton2) and more aggressive implementations (Altra Q) of the N1, but Arm states that their original presilicon projections ended up within 10% of the actual silicon performance figures of the respective products.

Compared to an N1, the V1 is meant to achieve 50% higher IPC, or 1.5x its predecessor while maintaining the same frequency capabilities.
What’s important to note on the slide here is that Arm is stating that power efficiency ranges from 0.7x to 1x that of the N1. Reversing the calculation for power usage increases, we actually end up with a 1.5x to 2.14x increase, which is actually quite significant. Arm also notes that the core is 1.7x larger than the N1, which is also a significant figure.
SiPearl’s Rhea chip was the first publicly known Neoverse V1 design and it features 72 cores on a N6 process node. The V1 core’s vastly increased power consumption means that it’s going to be incredibly hard to achieve similar clock frequencies while remaining in the similar 250W TDP range such as that of a current-gen top-end 80-core Altra chip, so either the core will have higher TDPs, or running at lower frequencies.
Arm also projects further non-ISO process performance figures which we’ll cover just a bit later, but there the company showcases a reference design of the V1 with 96 cores on 5nm at 2.7GHz. This means that whilst the microarchitecture seemingly would have the same frequency capabilities, the much higher power consumption of the core puts a practical limit onto the maximum frequency of any such larger core count designs.
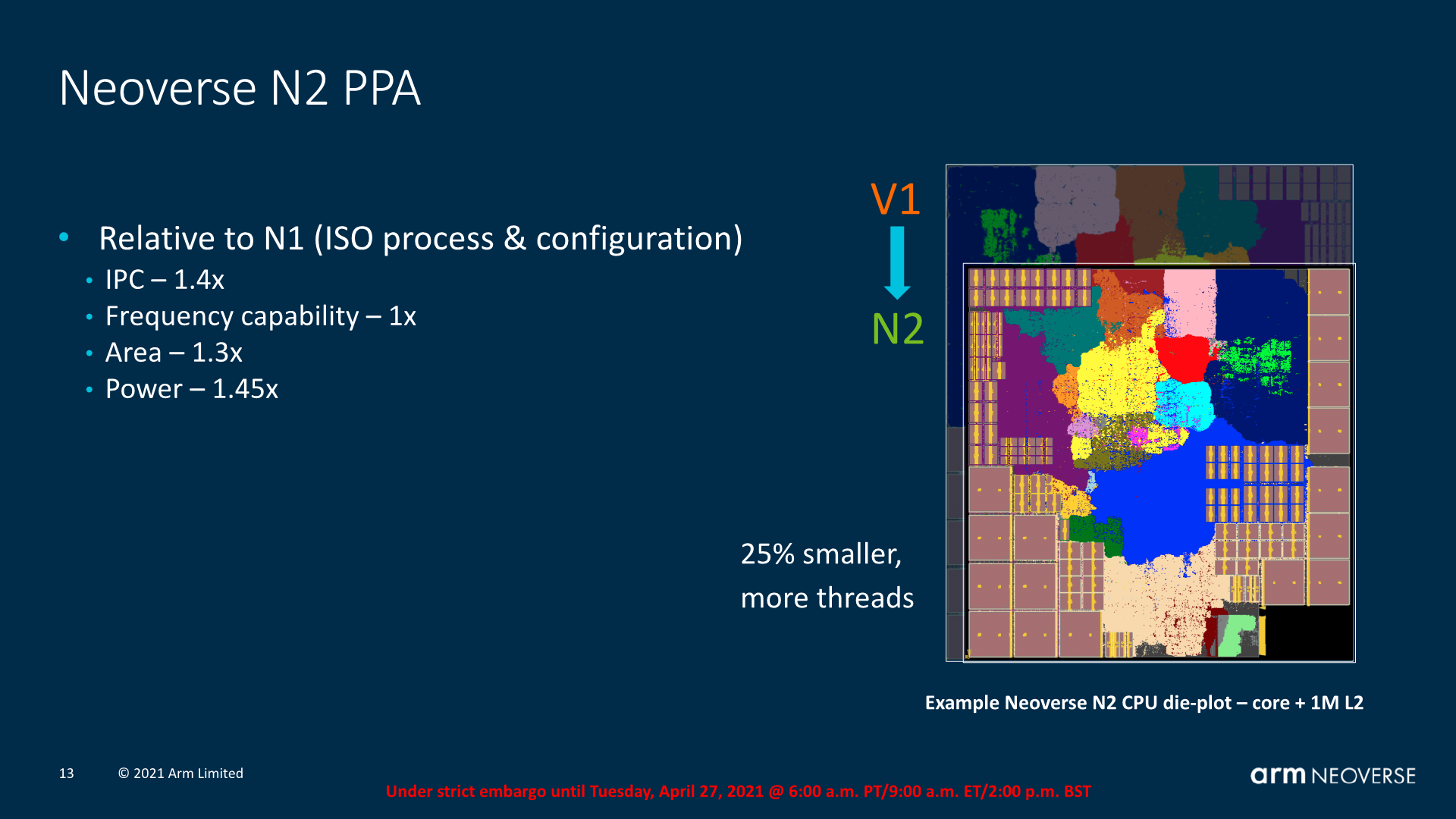
The Neoverse N2 seems a more appropriate design. Only losing out 10% IPC versus the V1, its power consumption is targeted to be only 1.45x higher than that of an N1, meaning efficiency lands in at an almost equal 96%. The area usage here is also only 1.3x that of an N1.
So generally speaking, the N2 seems to be a linear increase in performance over the N1 – both in performance and power. While this is not a regression in efficiency (well a small one at least), it does actually mean that in terms of frequency and end-performance targets, new N2 designs require larger generational process node improvements for actual vendors to be able to actually achieve the larger IPC and performance improvements that the new microarchitectures are promising.
I take note again of situations and workloads on the Ampere Altra where we’ve seen that there’s lots of workloads where the chip operates at below the TDP because the CPUs are underutilised. If an N2 design would be able to raise performance in such workloads, and more heavily throttle itself in higher demanding high utilisation workloads, it would still mean a net positive performance benefit even regardless of process node progresses. It’s a balance and situation that will be interesting to see how it plays out in eventual Neoverse N2 products.
In terms of absolute IPC improvements, Arm also disclosed a more varied set of workloads and what to expect out of the V1 and N2.
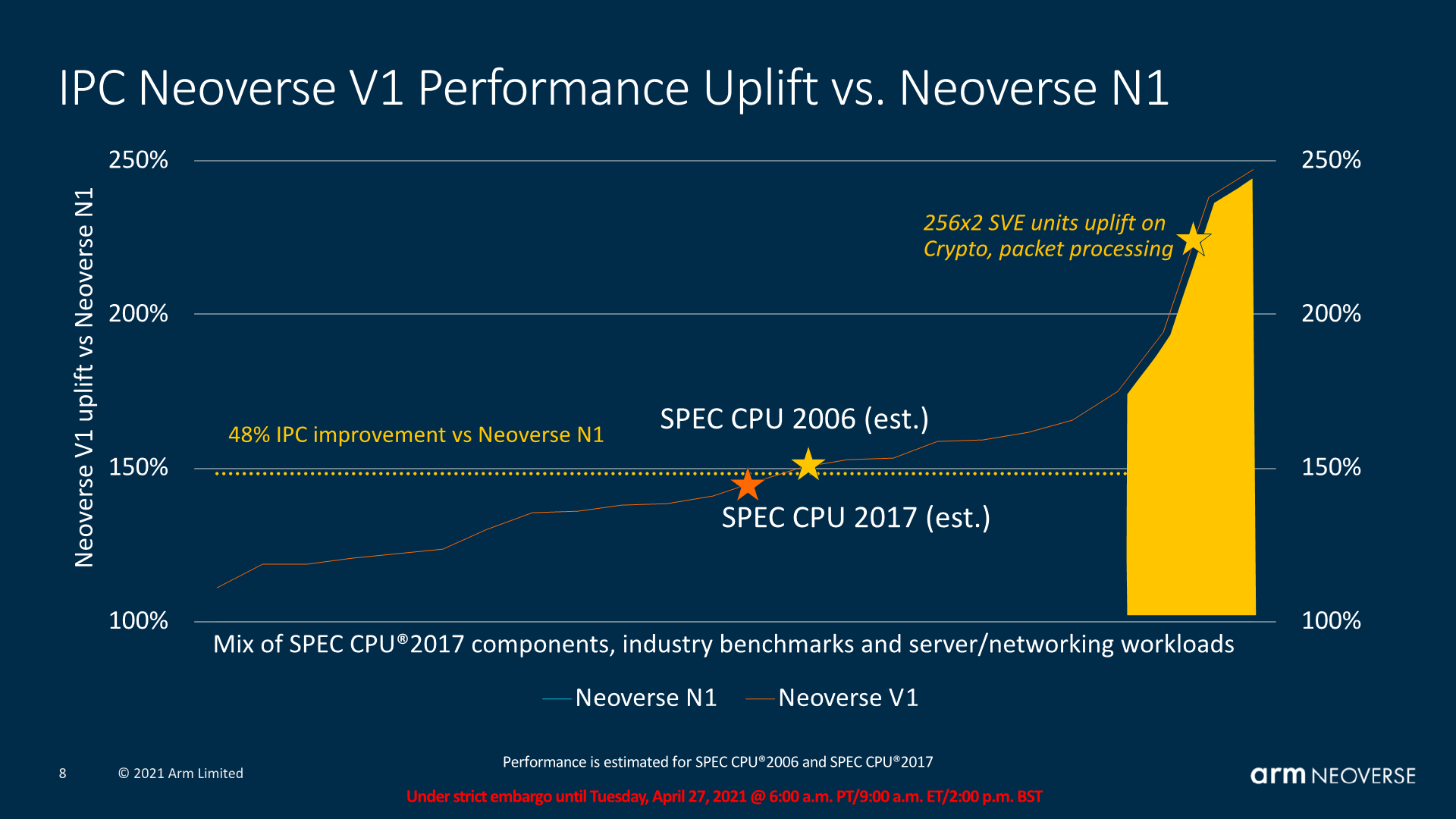
For the V1, the IPC improvements are roughly 50% median, with SPEC CPU essentially ending up at this figure. Arm made emphasis that there’s a set of workloads that are able to take advantage of SVE and the increased vector execution width of the V1 microarchitecture to achieve IPC improvements in excess of 100-125%, which is quite impressive.

The N2’s median IPC increase lands at a median of 32%, with SPEC CPU at roughly those marketed 40% figure. The high-end isn’t as high as that of the V1, but still in excess of +50% IPC.
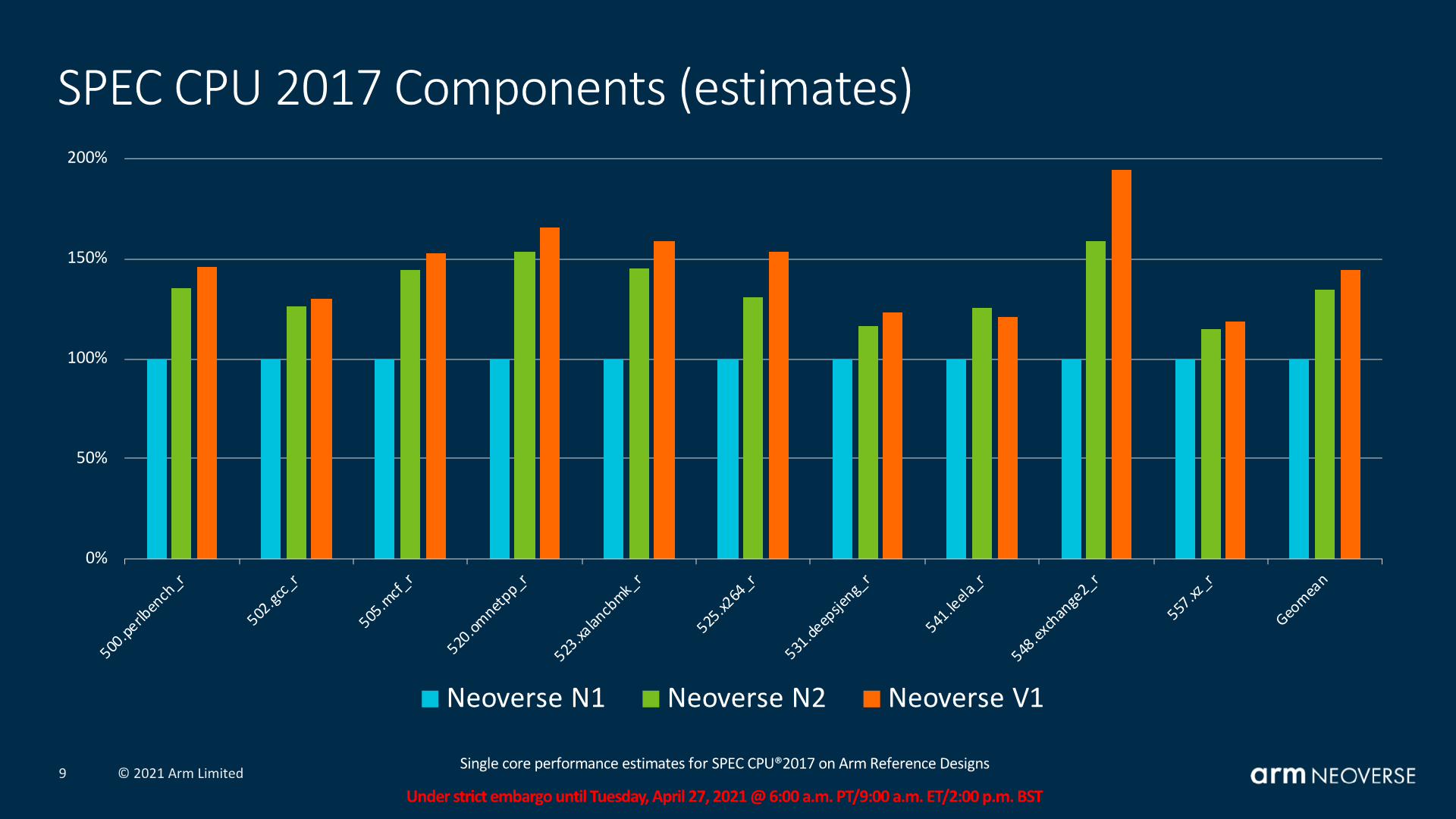
Finally, Arm also posted estimated figures for the components of SPEC CPU 2017, where we see the generational improvements be relatively even across the workloads, with a few exceptions where the V1’s larger characteristics come into play. There’s also workloads such as 541.leela_r where the N2 actually leads the V1, and Arm explained this by the fact that the N2 is actually a newer microarchitecture with further front-end improvements that aren’t found on the V1.








95 Comments
View All Comments
mode_13h - Wednesday, April 28, 2021 - link
Ah, yes! wikichip says of Zen 1:> Accordingly the peak throughput is four SSE/AVX-128 instructions
> or two AVX-256 instructions per cycle.
And Zen 2:
> This improvement doubles the peak throughput of AVX-256 instructions to four per cycle
Wow!
mode_13h - Tuesday, April 27, 2021 - link
What's SLC? I figured it was Second-Level Cache, until I saw the slide referencing "SLC -> L2 traffic"."System Level Cache", maybe? Could it be the term they use instead of L3 or LLC?
Thala - Tuesday, April 27, 2021 - link
I think you are totally right - SLC == LLC.Thala - Tuesday, April 27, 2021 - link
Quick addition. The term SLC is more popular lately, as it emphasize that the cache is not only shared among the cores but also with the system (GPU, DMAs etc).mode_13h - Wednesday, April 28, 2021 - link
Thanks. I guess I should've just waited until I'd finished reading it, because the interconnect slide made it abundantly clear.Now, I'm wondering about this "snoop filter" and why so much RAM is needed for it, when Graviton 2 & Altra have so little SLC. So, I gather it's not like tag RAM, then? Does it index the L2 of the adjacent cores, or something like that?
mode_13h - Tuesday, April 27, 2021 - link
Question and corrections on Page 6: PPA & ISO Performance ProjectionsWhat do the colors on the chip plots mean?
> Only losing out 10% IPC versus the N1
I'm sure that's meant to say "V1".
> In terms of absolute IPC improvements
Huh? These are definitely "relative IPC improvements" or just "IPC improvements".
Calin - Wednesday, April 28, 2021 - link
AWS share by vendor type: It should have been "Vendor A" and "Vendor I"mode_13h - Wednesday, April 28, 2021 - link
That slide was provided by ARM and I think they're trying to have at least the *appearance* of maintaining anonymity, even if the identities are abundantly clear.Also, you realize that their Vendor A is your Vendor I, right?
serendip - Wednesday, April 28, 2021 - link
How does the narrower front end and shallower pipeline of the N2 compare to Apple's M1? I'm thinking about how this could translate to the A78 successor, if that uses an evolution of the X1 core with improvements from N2 brought in.mode_13h - Thursday, April 29, 2021 - link
Good point. It suggests the A78+1 will perform < N2.Although, a derivative X-core would likely be > N2.