Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse V1 Microarchitecture: Platform Enhancements
Aside from the core-side microarchitectural aspects of the V1, the new design also features some new system-facing novelties that promise to help vendors integrate the CPU IP better in larger scale implementations.
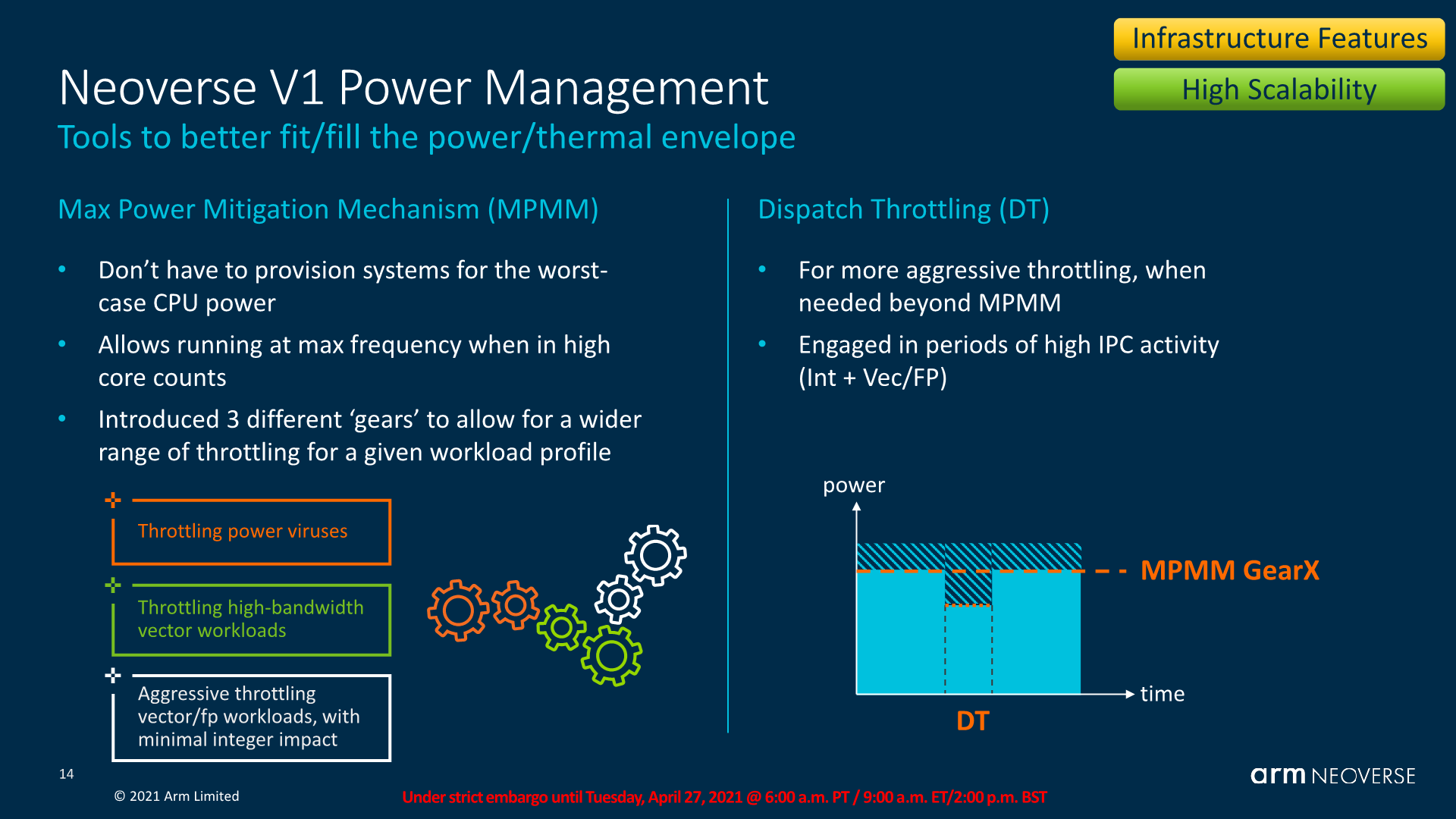
MPAM, or Max Power Mitigation Mechanism is a new fine-grained (to around 100 clock cycles) power management mechanism that promises to help smooth out the power behaviour of the core, and allow vendors’ implementations of the chip’s power delivery mechanisms to be so to say, be built to lesser requirements.
As we’ve seen in our review of the Ampere Altra, instead of fluctuating frequency at maximum TDP like how most x86 CPUs behave right now, the chip rather prefers to stay most of the time at maximum frequency, with the actual power consumption many times landing in at quite below the TDP (maximum allowed power consumption). A mechanism such as MPAM would allow, if possible, for the system’s average frequency to be higher by throttling the power limited cores to a finer degree. The mechanism to which this can be achieved can also include microarchitectural features such as dispatch throttling where the core slows down the dispatched instructions, smoothing out high power requirements in workloads having high execution periods, particularly important now with the new wider 2x256b SVE pipelines for example.

MPAM is a different mechanism helping interactions in larger system implementations. The Memory partitioning and monitoring feature is supposed to help with quality of service and reducing side-effects of noisy neighbours in deployments where multiple workloads, such as multiple VMs or processes, operate on the same system. This naturally requires software-hardware cooperation and implementation, but should be something that is particularly helpful in cloud environments.
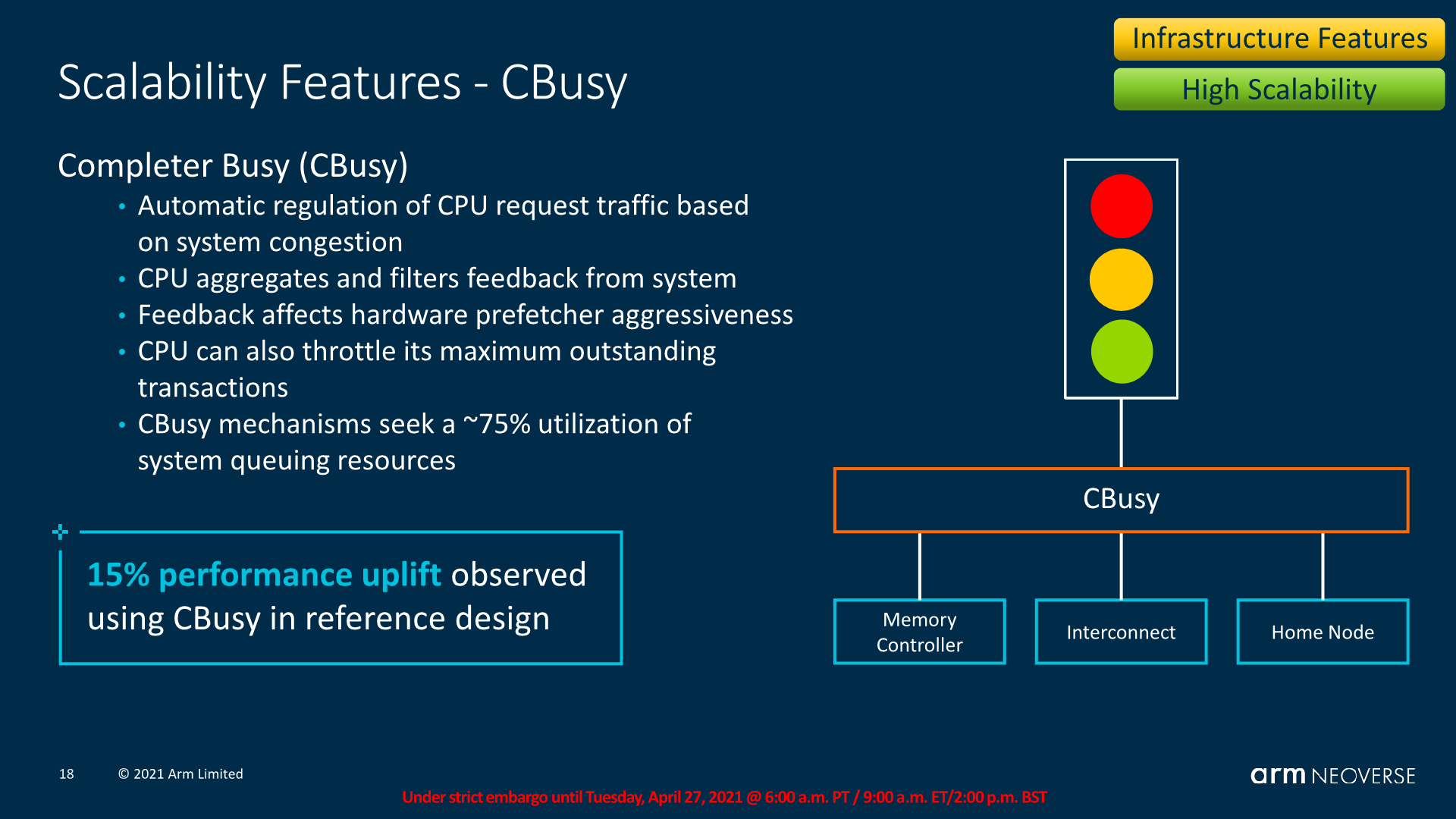
CBusy or Completer Busy is also a new system-side mechanism where the CPU cores interact with the mesh interconnect on a feedback-based basis, where the CPUs can vary their memory prefetcher aggressiveness depending on the overall mesh and system memory load. This ties in with the previously mentioned dynamic prefetcher behaviour where one can have the best of both worlds – better prefetching for more performance per core when the bandwidth is available, and very conservative prefetching when the system is under high load and there’s no room for wasted speculative bandwidth and data transfers.








95 Comments
View All Comments
mode_13h - Wednesday, April 28, 2021 - link
Ah, yes! wikichip says of Zen 1:> Accordingly the peak throughput is four SSE/AVX-128 instructions
> or two AVX-256 instructions per cycle.
And Zen 2:
> This improvement doubles the peak throughput of AVX-256 instructions to four per cycle
Wow!
mode_13h - Tuesday, April 27, 2021 - link
What's SLC? I figured it was Second-Level Cache, until I saw the slide referencing "SLC -> L2 traffic"."System Level Cache", maybe? Could it be the term they use instead of L3 or LLC?
Thala - Tuesday, April 27, 2021 - link
I think you are totally right - SLC == LLC.Thala - Tuesday, April 27, 2021 - link
Quick addition. The term SLC is more popular lately, as it emphasize that the cache is not only shared among the cores but also with the system (GPU, DMAs etc).mode_13h - Wednesday, April 28, 2021 - link
Thanks. I guess I should've just waited until I'd finished reading it, because the interconnect slide made it abundantly clear.Now, I'm wondering about this "snoop filter" and why so much RAM is needed for it, when Graviton 2 & Altra have so little SLC. So, I gather it's not like tag RAM, then? Does it index the L2 of the adjacent cores, or something like that?
mode_13h - Tuesday, April 27, 2021 - link
Question and corrections on Page 6: PPA & ISO Performance ProjectionsWhat do the colors on the chip plots mean?
> Only losing out 10% IPC versus the N1
I'm sure that's meant to say "V1".
> In terms of absolute IPC improvements
Huh? These are definitely "relative IPC improvements" or just "IPC improvements".
Calin - Wednesday, April 28, 2021 - link
AWS share by vendor type: It should have been "Vendor A" and "Vendor I"mode_13h - Wednesday, April 28, 2021 - link
That slide was provided by ARM and I think they're trying to have at least the *appearance* of maintaining anonymity, even if the identities are abundantly clear.Also, you realize that their Vendor A is your Vendor I, right?
serendip - Wednesday, April 28, 2021 - link
How does the narrower front end and shallower pipeline of the N2 compare to Apple's M1? I'm thinking about how this could translate to the A78 successor, if that uses an evolution of the X1 core with improvements from N2 brought in.mode_13h - Thursday, April 29, 2021 - link
Good point. It suggests the A78+1 will perform < N2.Although, a derivative X-core would likely be > N2.