Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse V1 Microarchitecture: Platform Enhancements
Aside from the core-side microarchitectural aspects of the V1, the new design also features some new system-facing novelties that promise to help vendors integrate the CPU IP better in larger scale implementations.
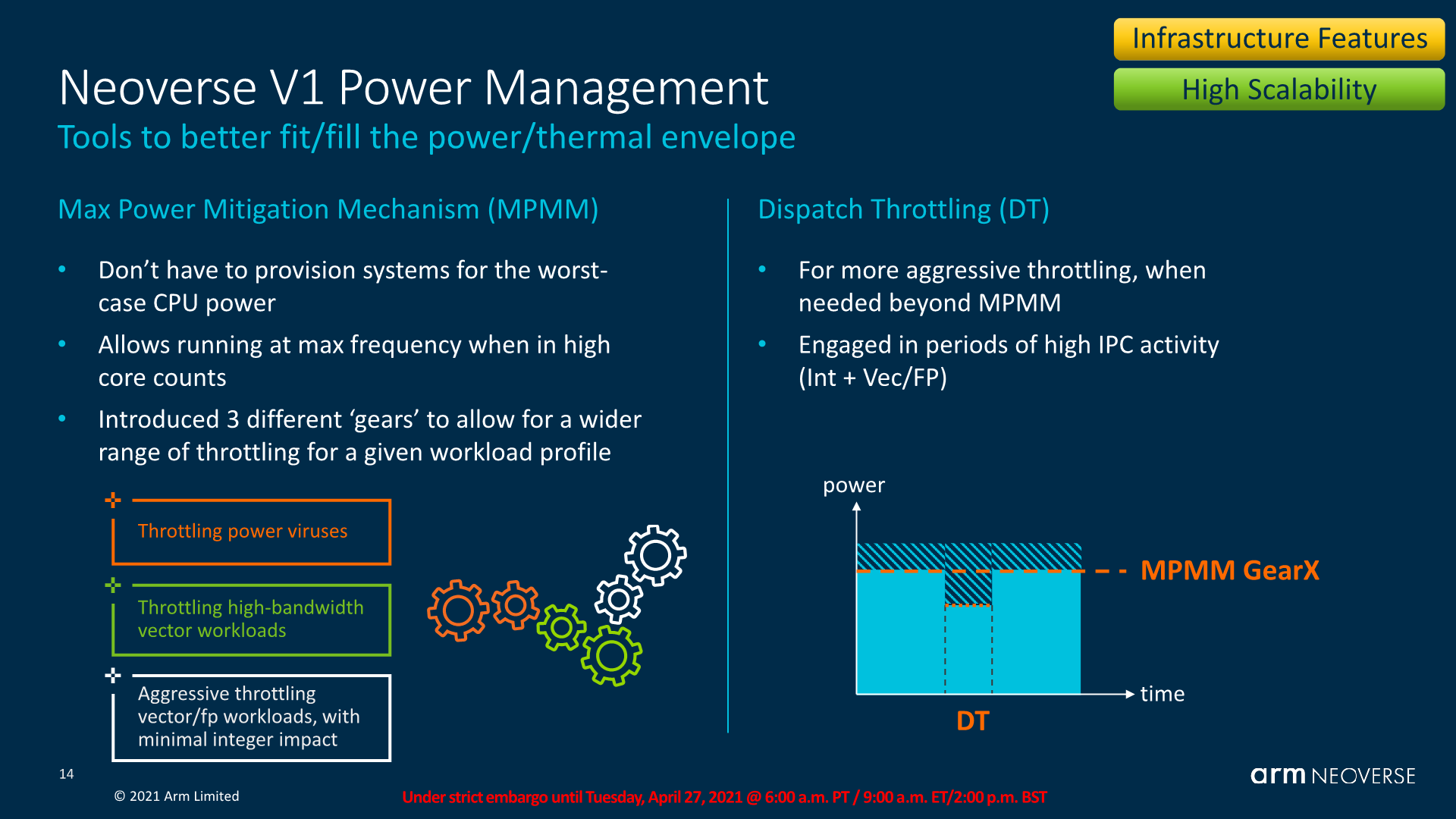
MPAM, or Max Power Mitigation Mechanism is a new fine-grained (to around 100 clock cycles) power management mechanism that promises to help smooth out the power behaviour of the core, and allow vendors’ implementations of the chip’s power delivery mechanisms to be so to say, be built to lesser requirements.
As we’ve seen in our review of the Ampere Altra, instead of fluctuating frequency at maximum TDP like how most x86 CPUs behave right now, the chip rather prefers to stay most of the time at maximum frequency, with the actual power consumption many times landing in at quite below the TDP (maximum allowed power consumption). A mechanism such as MPAM would allow, if possible, for the system’s average frequency to be higher by throttling the power limited cores to a finer degree. The mechanism to which this can be achieved can also include microarchitectural features such as dispatch throttling where the core slows down the dispatched instructions, smoothing out high power requirements in workloads having high execution periods, particularly important now with the new wider 2x256b SVE pipelines for example.

MPAM is a different mechanism helping interactions in larger system implementations. The Memory partitioning and monitoring feature is supposed to help with quality of service and reducing side-effects of noisy neighbours in deployments where multiple workloads, such as multiple VMs or processes, operate on the same system. This naturally requires software-hardware cooperation and implementation, but should be something that is particularly helpful in cloud environments.
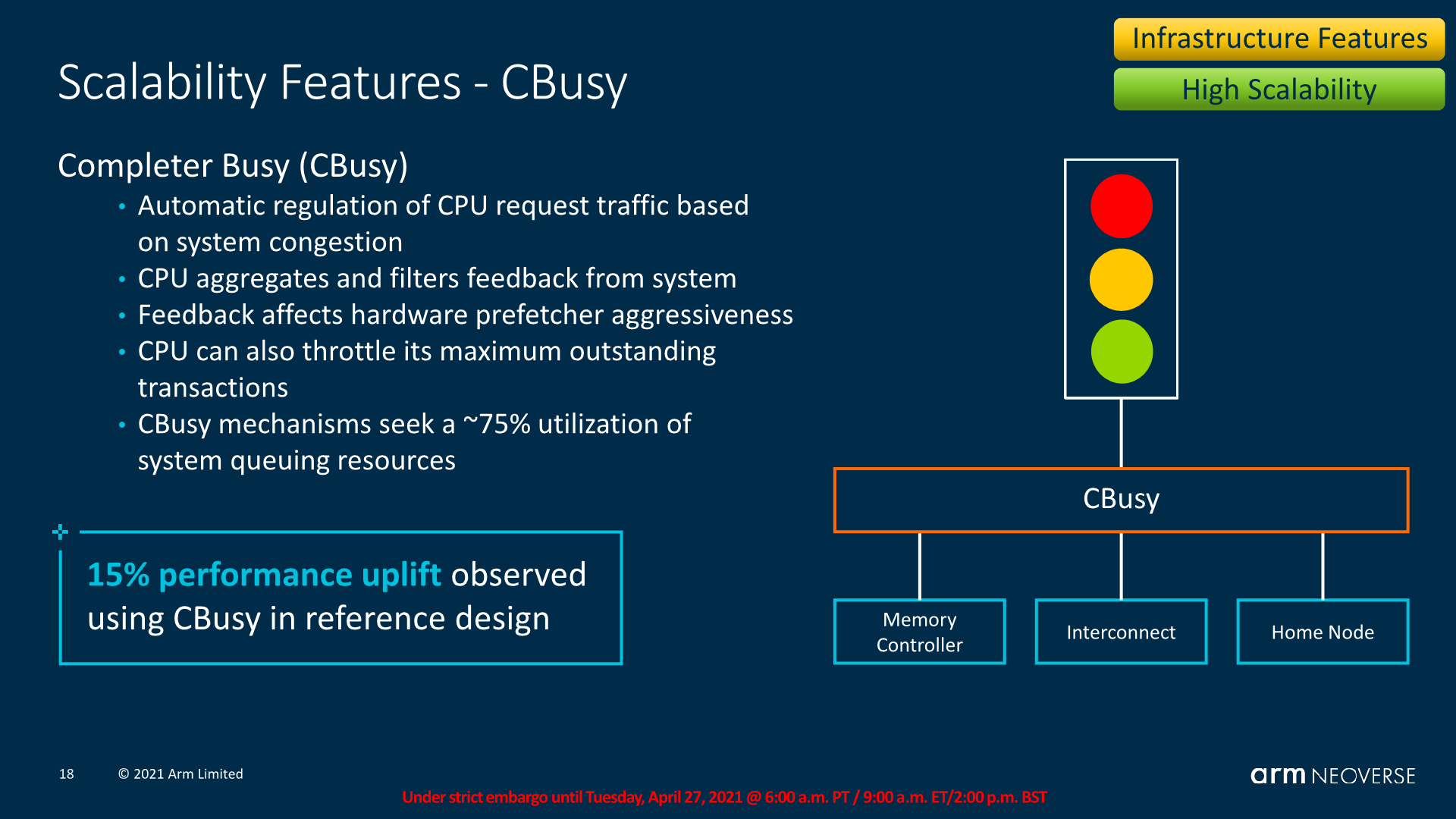
CBusy or Completer Busy is also a new system-side mechanism where the CPU cores interact with the mesh interconnect on a feedback-based basis, where the CPUs can vary their memory prefetcher aggressiveness depending on the overall mesh and system memory load. This ties in with the previously mentioned dynamic prefetcher behaviour where one can have the best of both worlds – better prefetching for more performance per core when the bandwidth is available, and very conservative prefetching when the system is under high load and there’s no room for wasted speculative bandwidth and data transfers.








95 Comments
View All Comments
nandnandnand - Tuesday, April 27, 2021 - link
Looking at Cortex-X-next. It seems like Arm can put out a new Cortex-X for every new Cortex-A78 successor, since the Cortex-X is very similar but bigger.mode_13h - Tuesday, April 27, 2021 - link
Form an earlier article:> The Cortex-X1 was designed within the frame of a new program at Arm,
> which the company calls the “Cortex-X Custom Program”.
> The program is an evolution of what the company had previously
> already done with the “Built on Arm Cortex Technology” program
> released a few years ago. As a reminder, that license allowed
> customers to collaborate early in the design phase of a new
> microarchitecture, and request customizations to the configurations,
> such as a larger re-order buffer (ROB), differently tuned prefetchers,
> or interface customizations for better integrations into the SoC designs.
> Qualcomm was the predominant benefactor of this license,
Alistair - Tuesday, April 27, 2021 - link
I just want to be able to use ARM in standard DIY with an Asus motherboard and a socket, just like AMD and Intel.mode_13h - Tuesday, April 27, 2021 - link
I wonder if Nvidia will put out a Jetson-style board in something like a mini-ITX form factor.Alistair - Wednesday, April 28, 2021 - link
i sure hope so, and something not massively overpriced like right nowmode_13h - Thursday, April 29, 2021 - link
Yeah, because Nvidia is known for their bargain pricing!; )
Although, if they wanted to create a whole new product segment, it's conceivable they might keep prices rather affordable for a couple generations.
nandnandnand - Wednesday, April 28, 2021 - link
I want it. You want it. Some people seem to want it. Maybe demand is forming? Get on it, China.16-core Cortex-X2 please.
mode_13h - Wednesday, April 28, 2021 - link
They already did, sort of. See: https://e.huawei.com/us/products/servers/kunpeng/k...Whoops! Had to get this out of Google cache, because the page 404'd:
Board Model D920S10
Processors 1 Kunpeng 920 processor, 4/8 cores, 2.6 GHz
Internal Storage 6 SATA 3.0 hard drive interfaces, 2 M.2 SSD slots
Memory 4 DDR4-2666 UDIMM slots, up to 64 GB
PCIe Expansion 1 PCIe 3.0 x16, 1 PCIe 3.0 x4, and 1 PCIe 3.0 x1 slots
LOM Network Ports 2 LOM NIC, supporting GE network ports or optical ports
USB 4 USB 3.0 and 4 USB 2.0
mode_13h - Tuesday, April 27, 2021 - link
Do any of the current x86 cores pair up SSE operations for >= 4x throughput per cycle?AVX2 has been around for long enough that a lot of the code which could benefit from it has already been written to do so, yet *most* people are still compiling to baseline x86-64 (or just above that), since Intel is still making low-power cores without any AVX. So, I'm sure there's still *some* code that could benefit from >= 4x SSEn execution.
AntonErtl - Wednesday, April 28, 2021 - link
Zen has 4 128-bit FP units (2 FMA and 2 FADD). Not sure if that's what you are interested in.