Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The SVE Factor - More Than Just Vector Size
We’ve talked a lot about SVE (Scalable Vector Extensions) over the past few years, and the new Arm ISA feature has been most known as being employed for the first time in Fujitsu’s A64FX processor core, which now powers the world’s most performance supercomputer.
Traditionally, employing CPU microarchitectures with wider SIMD vector capabilities always came with the caveat that you needed to use a new instruction set to make use of these wider vectors. For example, in the x86 world, we’ve seen the move from 128b (SSE-SSE4.2 & AVX) to 256b (AVX & AVX2) to 512b (AVX512) vectors always be coupled with a need for software to be redesigned and recompiled to make use of newer wider execution capabilities.
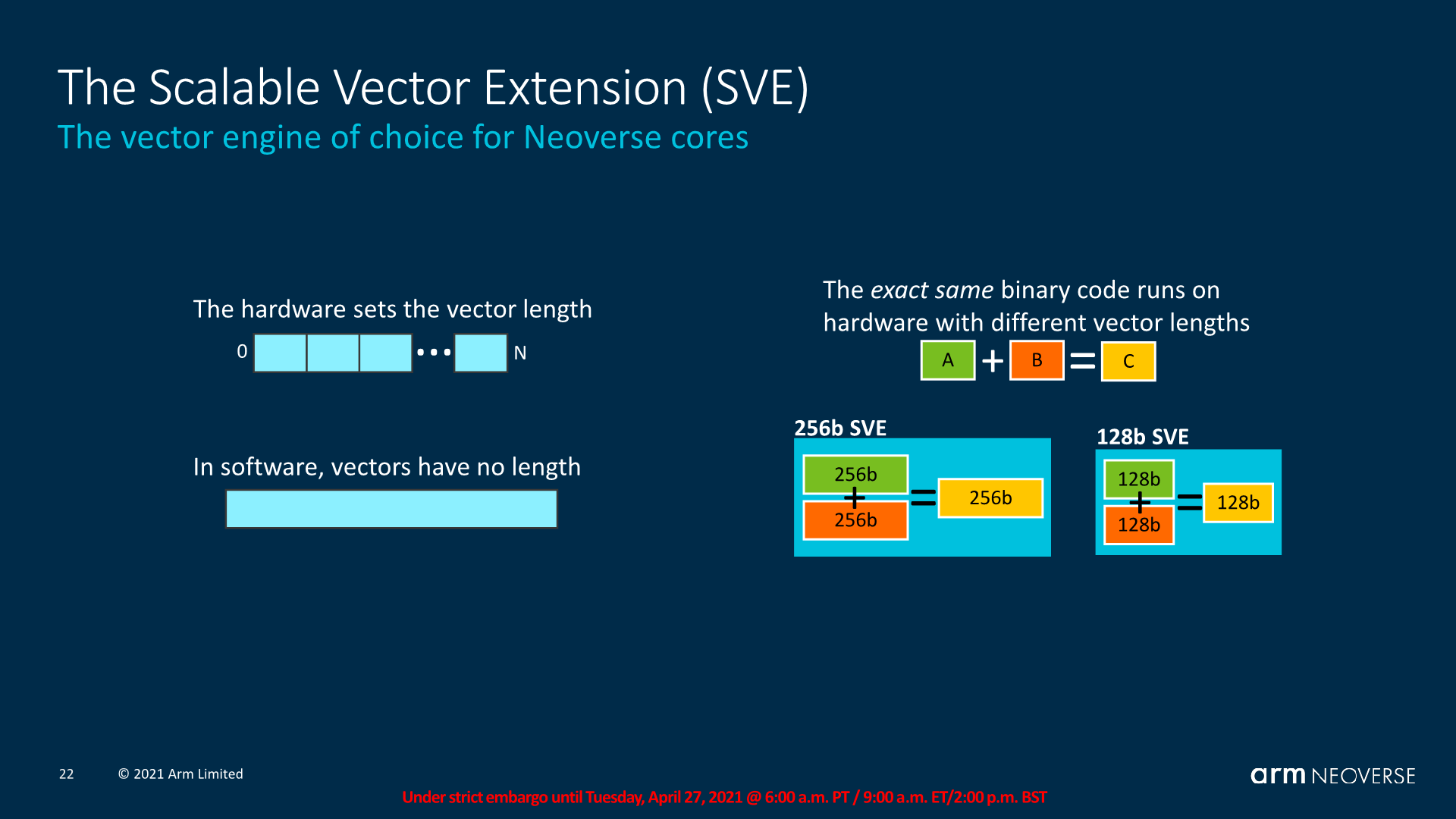
SVE on the other hand is hardware vector execution unit width agnostic, meaning that from a software perspective, the programmer doesn’t actually know the length of the vector that the software will end up running at. On the hardware side, CPU designers can implement execution units in 128b increments from 128b to 2048b in width. As noted earlier, the Neoverse N2 uses this smaller implementation of 128b units, while the Neoverse V1 uses 256b implementations.
Generally speaking, the actual execution width of the vector isn’t as important as the total execution width of a microarchitecture, 2x256b isn’t necessarily faster than 4x128b, however it does play a larger role on the software side of things where the same binary and code path can now be deployed to very different target products, which is also very important for Arm and their mobile processor designs.
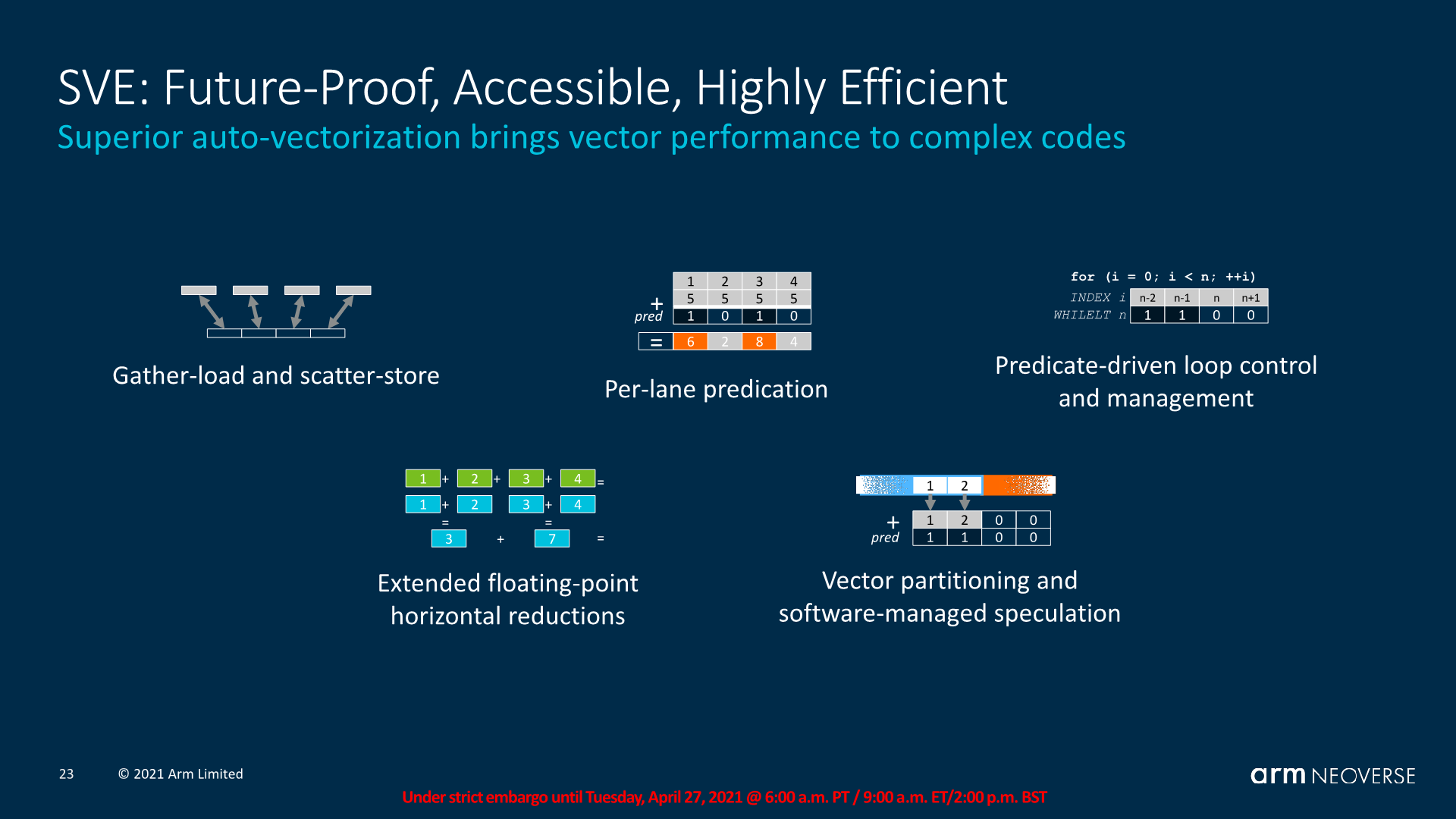
More important than the actual scalable nature of the vectors in SVE, is the new addition of helper instructions and features such as gather-loads, scatter-stores, per-lane predication, predicate-driven loop control (conditional execution depending on SIMD data), and many other features.
Where these things particularly come into play is for allowing compilers to generate better auto-vectorised code, meaning the compiler would now be capable of emitting SIMD instructions on SVE where previously it wasn’t possible with NEON – regardless of the vector length changes.

Arm here discloses that the performance advantages on auto-vectorizable code can be quite significant. In a 2x128b comparison between the N1 and the N2, we can see around 40th-percentile gains of at least 20% of performance, with some code reaching even much higher gains of up to +90%.
The V1 versus N1 increase being higher comes natural from the fact that the core has double the vector execution capabilities over the N1.

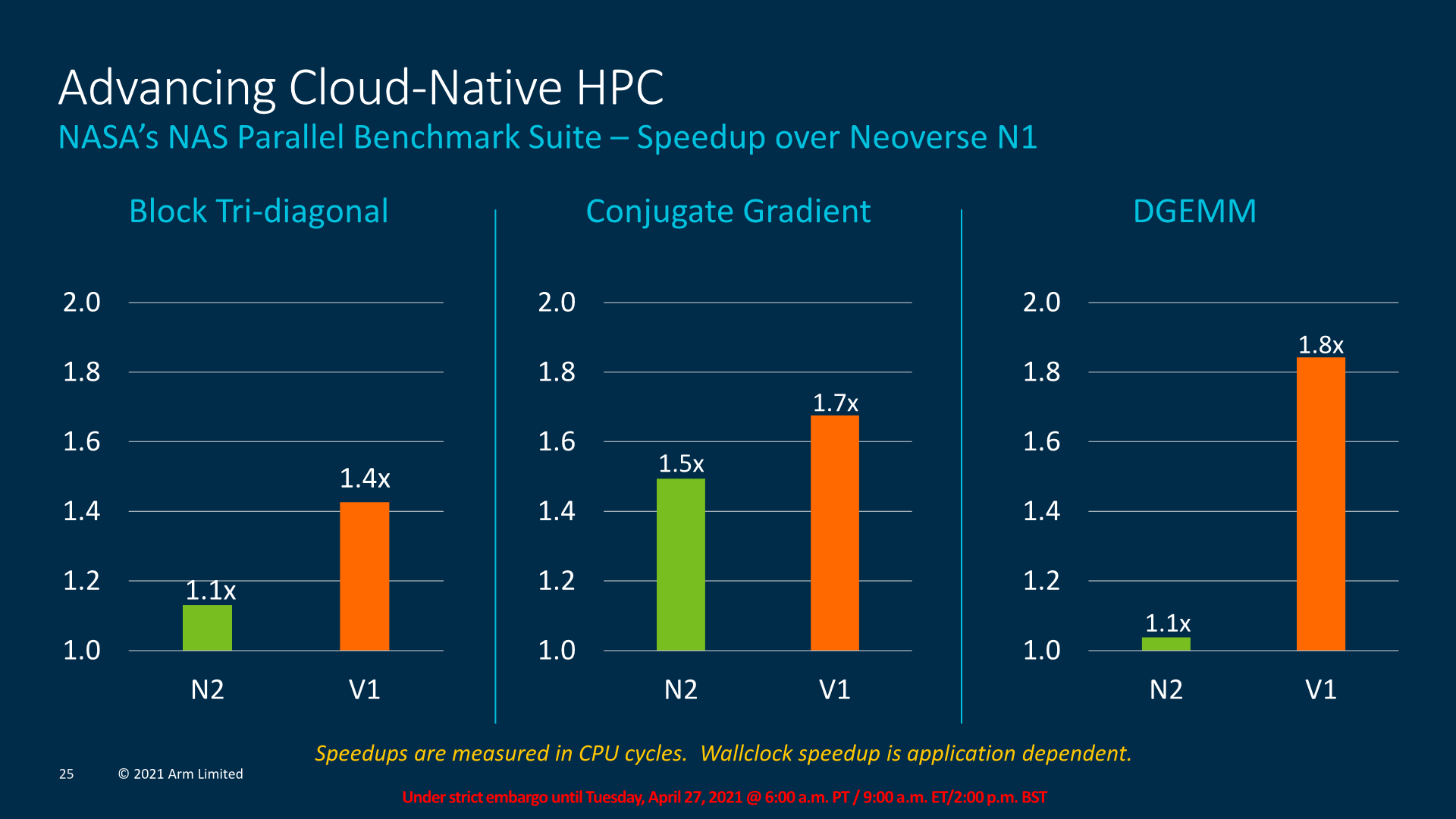
In general, both the N2, but particularly the V1, promise quite large increase in HPC workloads with vector heavy compute characteristics. It’ll definitely be interesting to see how these future designs play out and how SVE auto-vectorisation plays out in more general purpose workloads.








95 Comments
View All Comments
GeoffreyA - Friday, April 30, 2021 - link
"This is in comparison to x86 which seems to live in (probably justified) terror that any change they make, no matter how low level"P6, Netburst, Sandy Bridge, and Bulldozer seem like pretty big changes.
name99 - Friday, April 30, 2021 - link
(a) Sandy Bridge was the last such.(b) Look at the relative spacing (in time) for the two cases.
Look, I'm not interested in "x86 vs ARM. FIGHT!!!"
I'm simply pointing out various patterns I've noted that strike me as interesting and significant. If other people have similar such patterns to point out -- interesting and non-obvious aspects of new x86 micro-architectures, or patterns in how those micro-architectures have evolved over the past few years, they should add a comment.
But to this outsider the micro-architectures look stagnant -- utterly so in the case of Intel, mostly so in the case of AMD. In particular slight scaling up of an existing micro-architectures because a new process is more dense is not interesting! What is interesting is a new way of conceptualizing the problem that allows for a step change in the micro-architecture; and that is what I am not seeing on the x86 side.
I do see it in IBM (though for purposes that are, to me, uninteresting, both for POWER and for z/)
I do see it in ARM Ltd.
mode_13h - Friday, April 30, 2021 - link
> What is interesting is a new way of conceptualizing the problem that allows for a step change in the micro-architectureYes, but I think that largely depends on the ISA. And there, ARM has indeed been rather stagnant. Besides SVE and their new security features, most of their ISA changes have been tweaking around the margins. Not a fundamental rethink, or anything close to it.
What we need is more willingness to rethink the SW/HW divide and look at what more software can do to make hardware more efficient. Whenever I say this, people immediately seem to think I mean doing a VLIW-like approach, but that's too extreme for most workloads. You just have to look at an energy breakdown of a modern CPU and think creatively about where compilers could make the hardware's job a little bit easier or simpler, for the same or better result.
You can also flip it around, and ask where the primitives CPUs provide don't quite match up with what software is trying to do. I think TSX/HLE stands as an interesting example of that, and probably one where Intel doesn't get enough credit (granted, partly due to their own missteps).
name99 - Friday, April 30, 2021 - link
Architecture and micro-architecture are two different things.You want to fantasize about different architectures, be my guest. But I'm interested in MICRO-ARCHITECTURE and that was the content of my comments.
mode_13h - Saturday, May 1, 2021 - link
> Architecture and micro-architecture are two different things.The principle manifestation of the HW/SW divide is the ISA. That's why I talk about it rather than "architecture", which is a word that can mean different things to different people and in different contexts.
> You want to fantasize about different architectures, be my guest.
It's about as on-topic here as ever, given that we've gotten our most detailed look at ARMv9, yet. And performance + efficiency numbers!
> But I'm interested in MICRO-ARCHITECTURE and that was the content of my comments.
There's only so much you can do, within the constraints of an ISA. ARM had a chance to think really big, but they chose to play it safe and be very incremental. That could turn out to be a very costly mistake, for them and some of their licensees.
I just want what I think we all want, which is another decade of progress in performance and efficiency like the last one. So far, I'm not very hopeful. I guess we need to really hit the wall, before people are ready to get serious about embracing options to push it back, a bit further.