Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse V1 Microarchitecture: Platform Enhancements
Aside from the core-side microarchitectural aspects of the V1, the new design also features some new system-facing novelties that promise to help vendors integrate the CPU IP better in larger scale implementations.
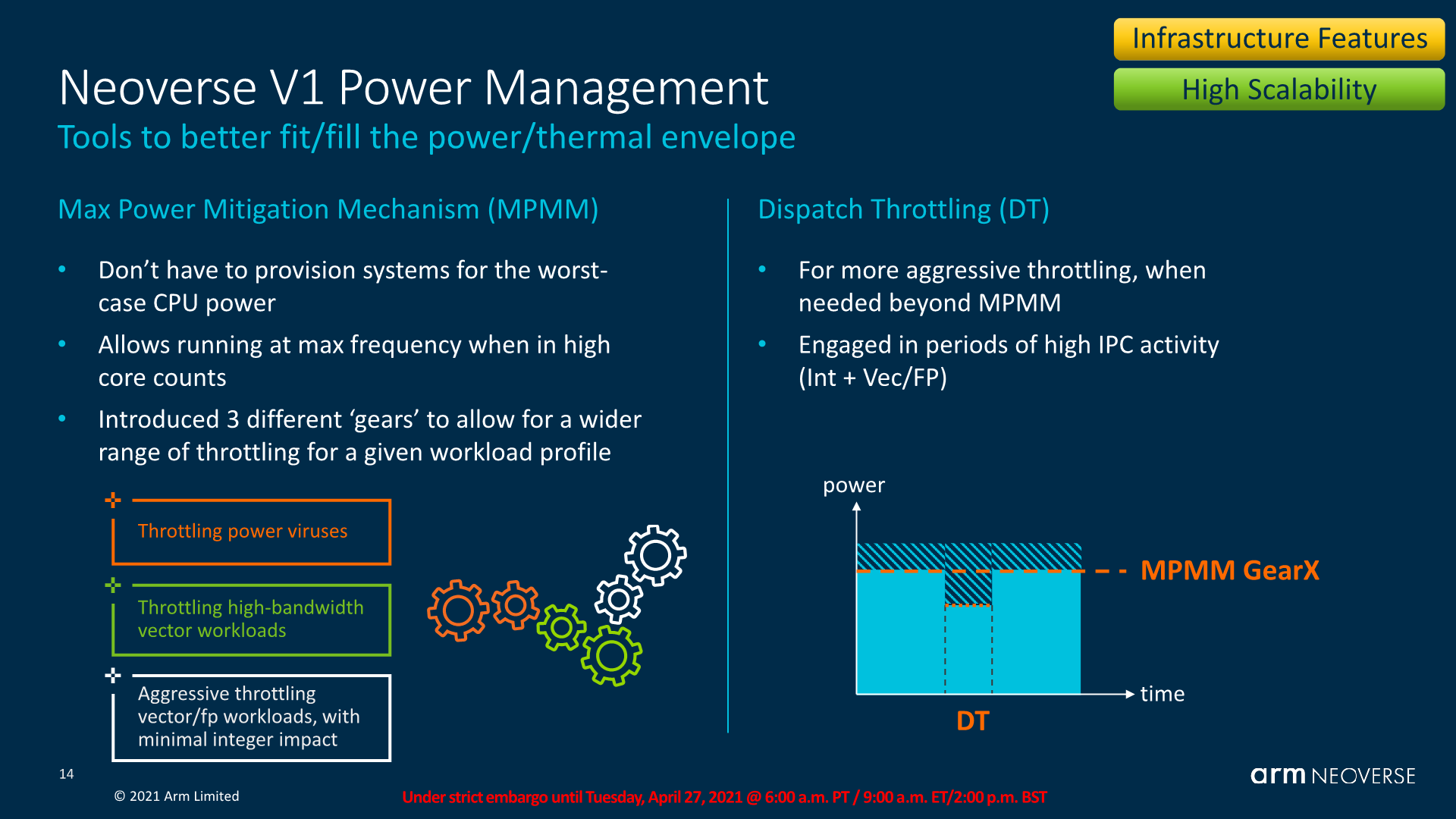
MPAM, or Max Power Mitigation Mechanism is a new fine-grained (to around 100 clock cycles) power management mechanism that promises to help smooth out the power behaviour of the core, and allow vendors’ implementations of the chip’s power delivery mechanisms to be so to say, be built to lesser requirements.
As we’ve seen in our review of the Ampere Altra, instead of fluctuating frequency at maximum TDP like how most x86 CPUs behave right now, the chip rather prefers to stay most of the time at maximum frequency, with the actual power consumption many times landing in at quite below the TDP (maximum allowed power consumption). A mechanism such as MPAM would allow, if possible, for the system’s average frequency to be higher by throttling the power limited cores to a finer degree. The mechanism to which this can be achieved can also include microarchitectural features such as dispatch throttling where the core slows down the dispatched instructions, smoothing out high power requirements in workloads having high execution periods, particularly important now with the new wider 2x256b SVE pipelines for example.

MPAM is a different mechanism helping interactions in larger system implementations. The Memory partitioning and monitoring feature is supposed to help with quality of service and reducing side-effects of noisy neighbours in deployments where multiple workloads, such as multiple VMs or processes, operate on the same system. This naturally requires software-hardware cooperation and implementation, but should be something that is particularly helpful in cloud environments.
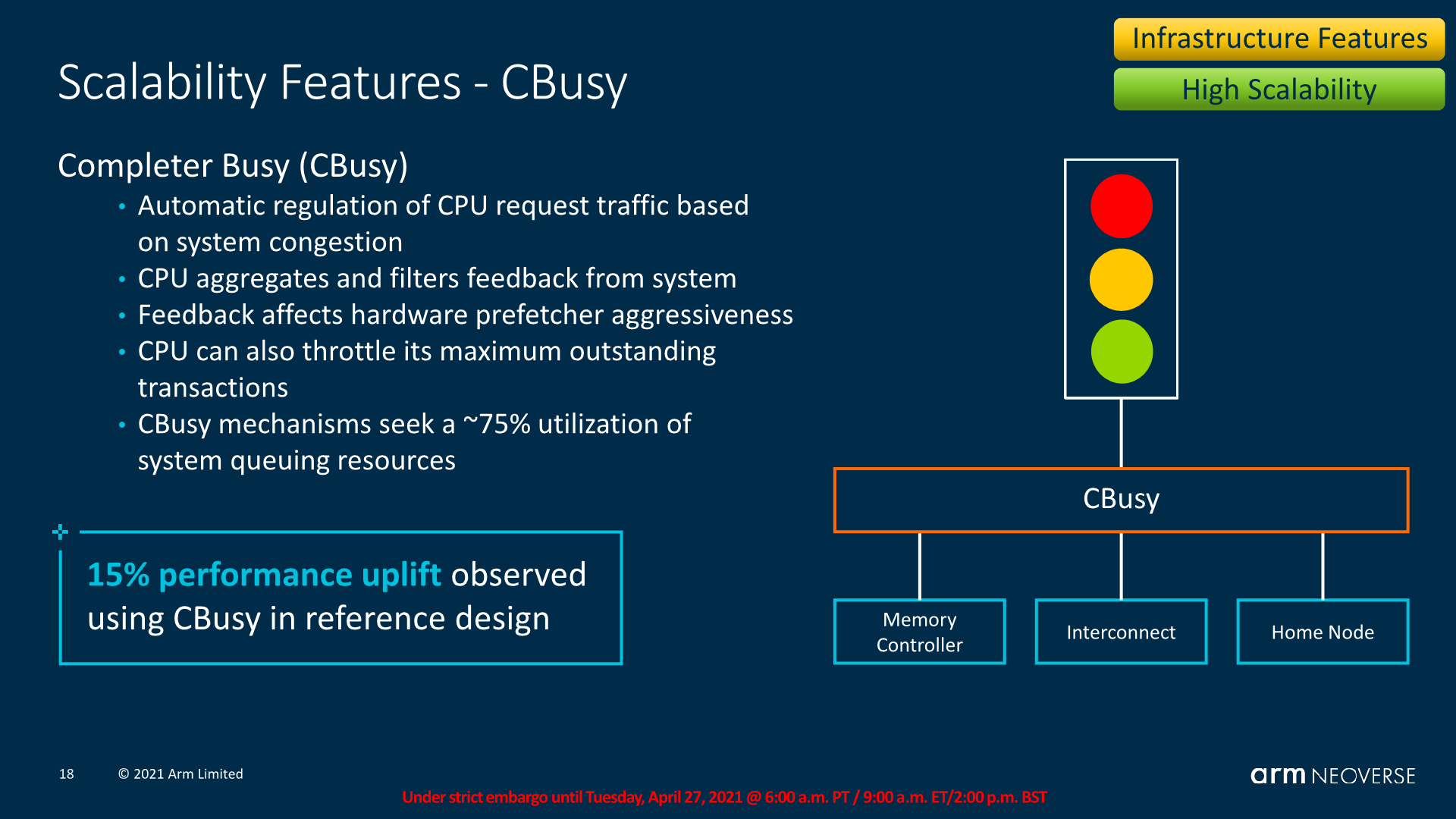
CBusy or Completer Busy is also a new system-side mechanism where the CPU cores interact with the mesh interconnect on a feedback-based basis, where the CPUs can vary their memory prefetcher aggressiveness depending on the overall mesh and system memory load. This ties in with the previously mentioned dynamic prefetcher behaviour where one can have the best of both worlds – better prefetching for more performance per core when the bandwidth is available, and very conservative prefetching when the system is under high load and there’s no room for wasted speculative bandwidth and data transfers.








95 Comments
View All Comments
GeoffreyA - Friday, April 30, 2021 - link
"This is in comparison to x86 which seems to live in (probably justified) terror that any change they make, no matter how low level"P6, Netburst, Sandy Bridge, and Bulldozer seem like pretty big changes.
name99 - Friday, April 30, 2021 - link
(a) Sandy Bridge was the last such.(b) Look at the relative spacing (in time) for the two cases.
Look, I'm not interested in "x86 vs ARM. FIGHT!!!"
I'm simply pointing out various patterns I've noted that strike me as interesting and significant. If other people have similar such patterns to point out -- interesting and non-obvious aspects of new x86 micro-architectures, or patterns in how those micro-architectures have evolved over the past few years, they should add a comment.
But to this outsider the micro-architectures look stagnant -- utterly so in the case of Intel, mostly so in the case of AMD. In particular slight scaling up of an existing micro-architectures because a new process is more dense is not interesting! What is interesting is a new way of conceptualizing the problem that allows for a step change in the micro-architecture; and that is what I am not seeing on the x86 side.
I do see it in IBM (though for purposes that are, to me, uninteresting, both for POWER and for z/)
I do see it in ARM Ltd.
mode_13h - Friday, April 30, 2021 - link
> What is interesting is a new way of conceptualizing the problem that allows for a step change in the micro-architectureYes, but I think that largely depends on the ISA. And there, ARM has indeed been rather stagnant. Besides SVE and their new security features, most of their ISA changes have been tweaking around the margins. Not a fundamental rethink, or anything close to it.
What we need is more willingness to rethink the SW/HW divide and look at what more software can do to make hardware more efficient. Whenever I say this, people immediately seem to think I mean doing a VLIW-like approach, but that's too extreme for most workloads. You just have to look at an energy breakdown of a modern CPU and think creatively about where compilers could make the hardware's job a little bit easier or simpler, for the same or better result.
You can also flip it around, and ask where the primitives CPUs provide don't quite match up with what software is trying to do. I think TSX/HLE stands as an interesting example of that, and probably one where Intel doesn't get enough credit (granted, partly due to their own missteps).
name99 - Friday, April 30, 2021 - link
Architecture and micro-architecture are two different things.You want to fantasize about different architectures, be my guest. But I'm interested in MICRO-ARCHITECTURE and that was the content of my comments.
mode_13h - Saturday, May 1, 2021 - link
> Architecture and micro-architecture are two different things.The principle manifestation of the HW/SW divide is the ISA. That's why I talk about it rather than "architecture", which is a word that can mean different things to different people and in different contexts.
> You want to fantasize about different architectures, be my guest.
It's about as on-topic here as ever, given that we've gotten our most detailed look at ARMv9, yet. And performance + efficiency numbers!
> But I'm interested in MICRO-ARCHITECTURE and that was the content of my comments.
There's only so much you can do, within the constraints of an ISA. ARM had a chance to think really big, but they chose to play it safe and be very incremental. That could turn out to be a very costly mistake, for them and some of their licensees.
I just want what I think we all want, which is another decade of progress in performance and efficiency like the last one. So far, I'm not very hopeful. I guess we need to really hit the wall, before people are ready to get serious about embracing options to push it back, a bit further.