Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Per-Core Performance under Load
A metric that is actually more interesting than isolated single-thread performance, is actually per-thread performance in a fully loaded system. This actually is a measurement and benchmark figure that would greatly interest enterprises and customers which are running software or workloads that are possibly licensed on a per-core basis, or simply workloads that require a certain level of per-thread service level agreement in terms of performance.
This has been a strong-point of Intel SKUs for some time now, even when the chips wouldn’t be competitive in terms of total throughput. With the new Ice Lake SPs SKUs now more notably increasing total throughput, it’ll be interesting to see the per-thread breakdown and resulting performance:
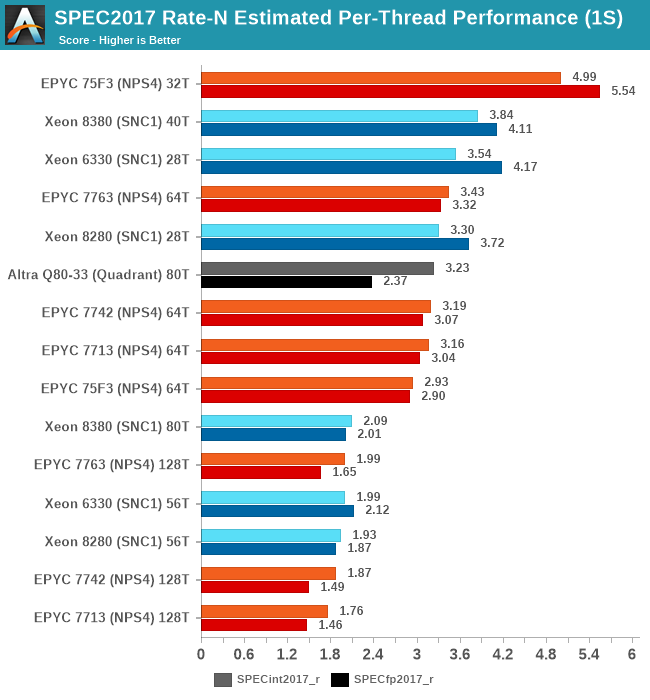
Because the total throughput generational performance increase is larger than the core count increase of the parts, this means that per-thread and per-core performance is higher with this generation. The Xeon 8380 is posting +16.3% and +10.4% per-thread performance versus the Xeon 8280 when only using one thread per core.
Interestingly, these figures are less at +8.2 and +7.4% when using both SMT threads per core. Intel has explained such an increase through the better usage of shared microarchitectural structure usage in the new Sunny Cove cores, essentially diminishing the SMT yield by improving 1/T per core performance.
Generally, Intel is extremely competitive in this benchmark metric, and while AMD easily beats them with the frequency-optimised parts, it’s an advantage that should help Intel in the SLA-centric workloads.








169 Comments
View All Comments
fallaha56 - Tuesday, April 6, 2021 - link
surebut when your 64-core part virtually beats Intel's dual socket 32-core part on performance alone?
add the energy savings and suddenly it's a 300-400% perf lead
Jorgp2 - Tuesday, April 6, 2021 - link
The fuck?You do realize that they put more than CPUs onto servers right?
Andrei Frumusanu - Tuesday, April 6, 2021 - link
We are testing non-production server configurations, all with varying hardware, PSUs, and other setup differences. Socket comparisons remain relatively static between systems.edzieba - Tuesday, April 6, 2021 - link
Would be interesting to pit the 4309 (or 5315) against the Rocket Lake octacores. Yes, it's a very different platform aimed at a different market, but it would be interesting to see what a hypothetical '10nm Sunny Cove consumer desktop' could have resembled compared to what Rocket Lake's Sunny Cove delivered on 14nm.Jorgp2 - Tuesday, April 6, 2021 - link
You could also compare it to the 10900x, which is an existing AVX-512 CPU with large L2 caches.Holliday75 - Tuesday, April 6, 2021 - link
Typical consumer workloads the RL will be better. For typical server workloads the IL will be better. That is the gist of what would be said.ricebunny - Tuesday, April 6, 2021 - link
These tests are not entirely representative of real world use cases. For open source software, the icc compiler should always be the first choice for Intel chips. The fact that Intel provides such a compiler for free and AMD doesn’t is a perk that you get with owning Intel. It would be foolish not to take advantage of it.Andrei Frumusanu - Tuesday, April 6, 2021 - link
AMD provides AOCC and there's nothing stopping you from running ICC on AMD either. The relative positioning in that scenario doesn't change, and GCC is the industry standard in that regard in the real world.ricebunny - Tuesday, April 6, 2021 - link
Thanks for your reply. I was speaking from my experience in HPC: I’ve never compiled code that I intended to run on Intel architectures with anything but icc, except when the environment did not provide me such liberty, which was rare.If I were to run the benchmarks, I would build them with the most optimal settings for each architecture using their respective optimizing compilers. I would also make sure that I am using optimized libraries, e.g. Intel MKL and not Open BLAS for Intel architecture, etc.
Wilco1 - Tuesday, April 6, 2021 - link
And I could optimize benchmarks using hand crafted optimal inner loops in assembler. It's possible to double the SPEC score that way. By using such optimized code on a slow CPU, it can *appear* to beat a much faster CPU. And what does that prove exactly? How good one is at cheating?If we want to compare different CPUs then the only fair option is to use identical compilers and options like AnandTech does.