Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Single-Threaded Performance
Single-thread performance of server CPUs usually isn’t the most important metric for most scale-out workloads, but there are use-cases such as EDA tools which are pretty much single-thread performance bound.
Power envelopes here usually don’t matter, and what is actually the performance factor that comes at play here is simply the boost clocks of the CPUs as well as the IPC improvement, and memory latency of the cores.
The one hiccup for the Xeon 8380 this generation is the fact that although there’s plenty of IPC gains to be had compared to previous microarchitectures, the new SKU is only boosting up to 3.4GHz, whereas the 8280 was able to boost up to 4GHz, which is a 15% deficit.
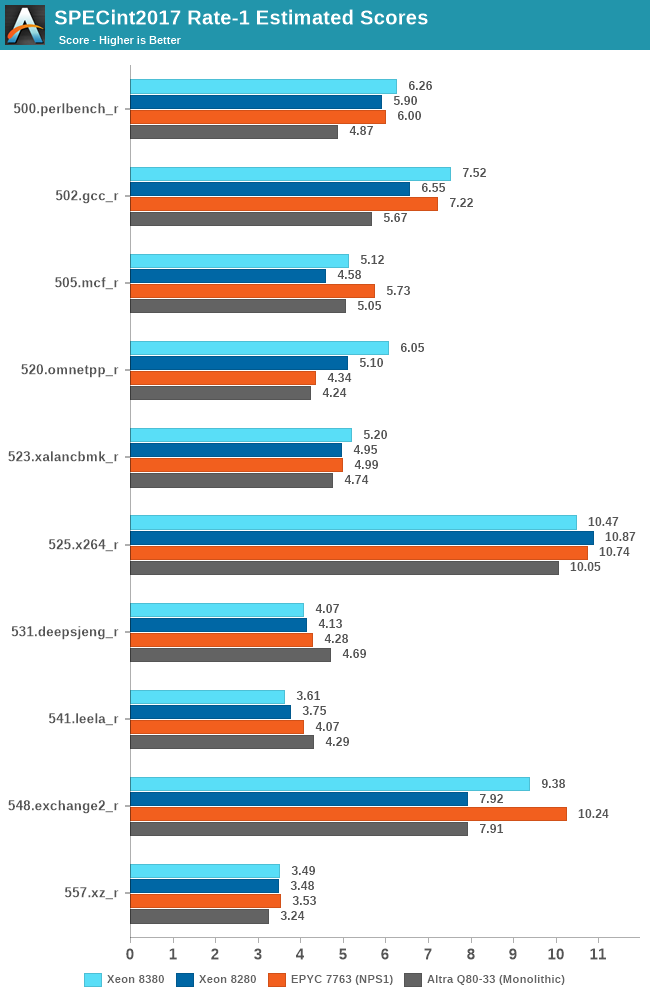
Even with the clock frequency disadvantage, thanks to the IPC gains, much improved memory bandwidth, as well as the much larger L3 cache, the new Ice Lake part to most of the time beat the Cascade Lake part, with only a couple of compute-bound core workloads where it falls behind.
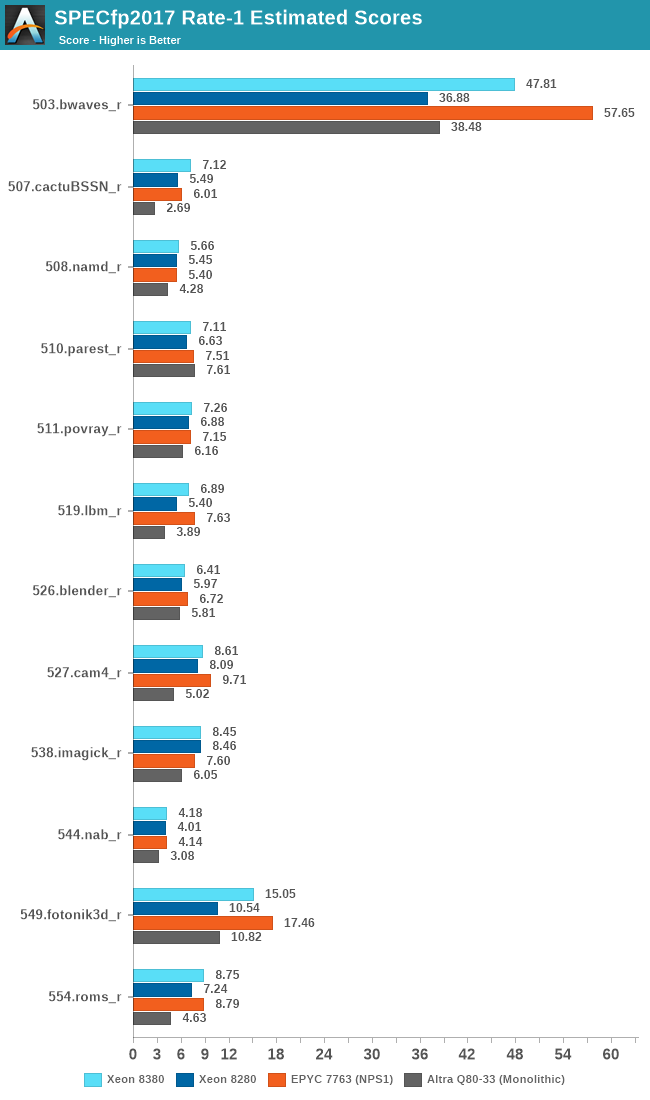
The floating-point figures are more favourable to the ICX architecture due to the stronger memory performance.
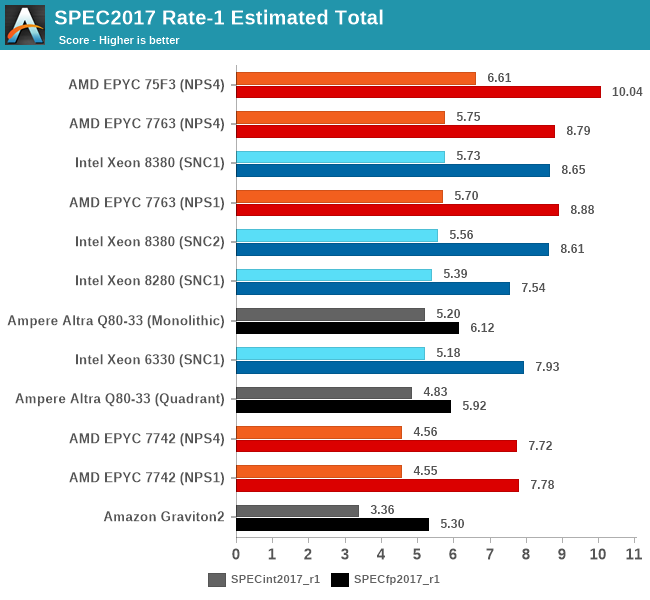
Overall, the new Xeon 8380 at least manages to post slight single-threaded performance increases this generation, with larger gains in memory-bound workloads. The 8380 is essentially on par with AMD’s 7763, and loses out to the higher frequency optimised parts.
Intel has a few SKUs which offers slightly higher ST boost clocks of up to 3.7GHz – 300Mhz / 8.8% higher than the 8380, however that part is only 8-core and features only 18MB of cache. Other SKUS offer 3.5-3.6GHz boosts, but again less cache. So while the ST figures here could improve a bit on those parts, it’s unlikely to be significant.








169 Comments
View All Comments
Oxford Guy - Wednesday, April 7, 2021 - link
You're arguing apples (latency) and oranges (capability).An Apple II has better latency than an Apple Lisa, even though the latter is vastly more powerful in most respects. The sluggishness of the UI was one of the big problems with that system from a consumer point of view. Many self-described power users equated a snappy interface with capability, so they believed their CLI machines (like the IBM PC) were a lot better.
GeoffreyA - Wednesday, April 7, 2021 - link
"today's software and OSes are absurdly slow, and in many cases desktop applications are slower in user-time than their late 1980s counterparts"Oh yes. One builds a computer nowadays and it's fast for a year. But then applications, being updated, grow sluggish over time. And it starts to feel like one's old computer again. So what exactly did we gain, I sometimes wonder. Take a simple suite like LibreOffice, which was never fast to begin with. I feel version 7 opens even slower than 6. Firefox was quite all right, but as of 85 or 86, when they introduced some new security feature, it seems to open a lot slower, at least on my computer. At any rate, I do appreciate all the free software.
ricebunny - Wednesday, April 7, 2021 - link
Well said.Frank_M - Thursday, April 8, 2021 - link
Intel Fortran is vastly faster then GCC.How did ricebunny get a free compiler?
mode_13h - Thursday, April 8, 2021 - link
> It's strange to tell people who use the Intel compiler that it's not used much in the real world, as though that carries some substantive point.To use the automotive analogy, it's as if a car is being reviewed using 100-octane fuel, even though most people can only get 93 or 91 octane (and many will just use the cheap 87 octane, anyhow).
The point of these reviews isn't to milk the most performance from the product that's theoretically possible, but rather to inform readers about how they're likely to experience it. THAT is why it's relevant that almost nobody uses ICC in practice.
And, in fact, BECAUSE so few people are using ICC, Intel puts a lot of work into GCC and LLVM.
GeoffreyA - Thursday, April 8, 2021 - link
I think that a common compiler like GCC should be used (like Andrei is doing), along with a generic x86-64 -march (in the case of Intel/AMD) and generic -mtune. The idea would be to get the CPUs on as equal a footing as possible, even with code that might not be optimal, and reveal relative rather than absolute performance.Wilco1 - Thursday, April 8, 2021 - link
Using generic (-march=x86-64) means you are building for ancient SSE2... If you want a common baseline then use something like -march=x86-64-v3. You'll then get people claiming that excluding AVX-512 is unfair eventhough there is little difference on most benchmarks except for higher power consumption ( https://www.phoronix.com/scan.php?page=article&... ).GeoffreyA - Saturday, April 10, 2021 - link
I think leaving AVX512 out is a good policy.GeoffreyA - Thursday, April 8, 2021 - link
If I may offer an analogy, I would say: the benchmark is like an exam in school but here we test time to finish the paper (and with the constraint of complete accuracy). Each pupil should be given the identical paper, and that's it.Using optimised binaries for different CPUs is a bit like knowing each child's brain beforehand (one has thicker circuitry in Bodman region 10, etc.) and giving each a paper with peculiar layout and formatting but same questions (in essence). Which system is better, who can say, but I'd go with the first.
Oxford Guy - Wednesday, April 7, 2021 - link
Well, whatever tricks were used made Blender faster with the ICC builds I tested — both on AMD's Piledriver and on several Intel releases (Lynnfield and Haswell).