AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM ESTDisclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPEC - Single-Threaded Performance
Single-thread performance of server CPUs usually isn’t the most important metric for most scale-out workloads, but there are use-cases such as EDA tools which are pretty much single-thread performance bound.
Power envelopes here usually don’t matter, and what is actually the performance factor that comes at play here is simply the boost clocks of the CPUs as well as the IPC improvement, and memory latency of the cores. We’re also testing the results here in NPS1 mode as if you have single-threaded bound workloads, you should prefer to use the systems in a single NUMA node mode.
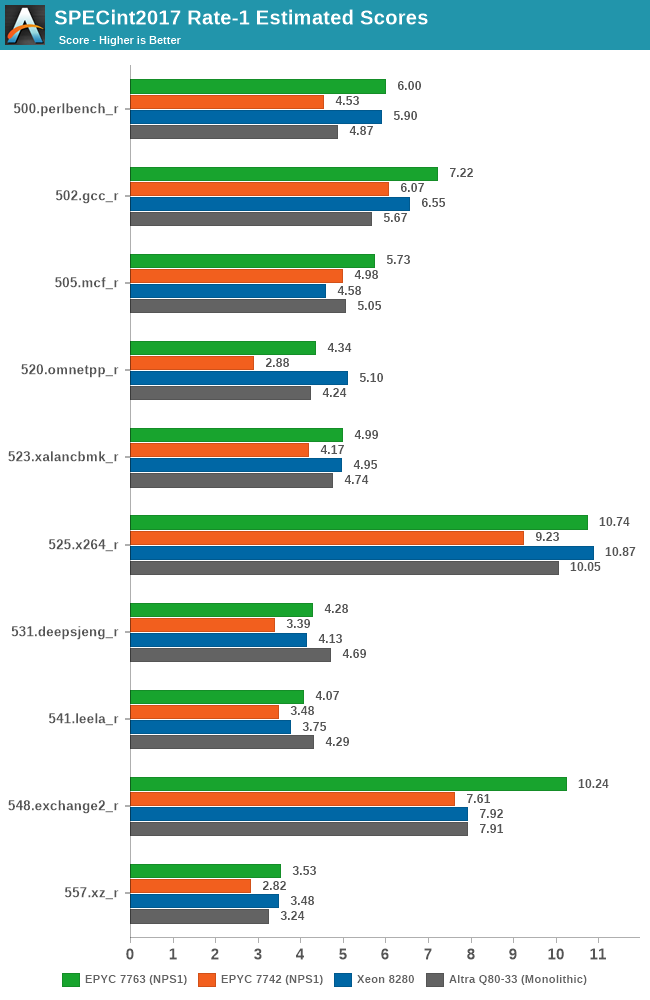
Generationally, the new Zen3-based 7763 improves performance quite significantly over the 7742, even though I noted that both parts boosted almost equally to around 3400MHz in single-threaded scenarios. The uplifts here average over a geomean of +25%, with individual increases from +15 to +50%, with a median of +22%.
The Milan part also now more clearly competes against the best of the competition, even though it’s not a single-threaded optimised part as the 75F3 – we’ll see those scores a bit later.
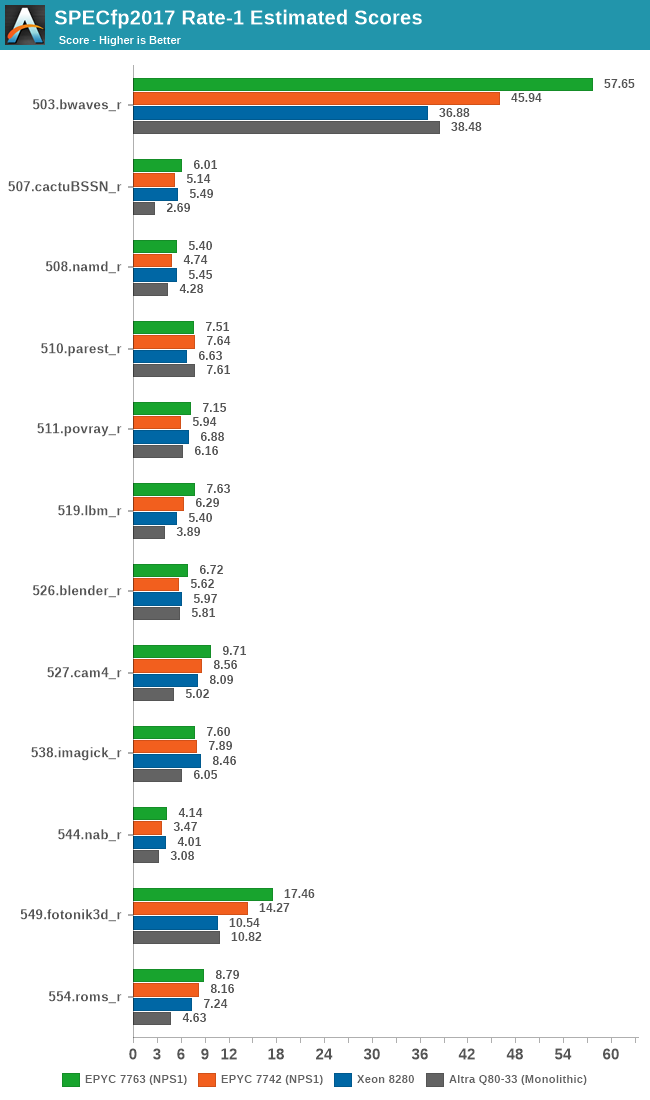
In SPECfp, the Zen3 based Milan chip also does extremely well, measuring an average geomean boost of +14.2% and a median of +18%.
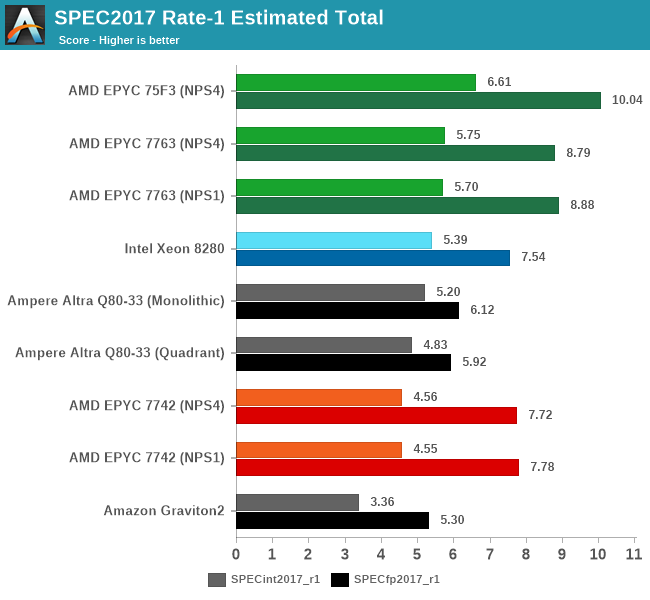
The new 7763 takes a notable lead in single-threaded performance amongst the large core count SKUs in the market right now. More notably, the 75F3 further increases this lead through the higher 4GHz boost clock this frequency optimised part enables.








120 Comments
View All Comments
lejeczek - Monday, March 15, 2021 - link
But those Altra Q80-33 ... gee guys. I have been thinking for a while - next upgrade of the stack in the rack might as well be...mode_13h - Monday, March 15, 2021 - link
Well, if it does well on the benchmarks that align with your workload, then I'd certainly consider at least a single-CPU Altra. IIRC, the multi-CPU interconnect was one of its weak points. You could even go dual-CPU, if you're provisioning VMs that fit on a single CPU (or better yet, just one quadrant).Pinn - Monday, March 15, 2021 - link
When does this filter to the Threadrippers?mode_13h - Monday, March 15, 2021 - link
Probably either when demand for the 3000-series Threadrippers starts slipping or if/when the supply of top-binned Zen3 dies ever catches up.It would be interesting to see what performance could be extracted from these CPUs, if AMD would raise the power/thermal limit another 100 W. Maybe the 5000-series TR Pro will be our chance to find out!
mode_13h - Monday, March 15, 2021 - link
Someone please remind me why Altra's memory performance is so much stronger. Is it simply down to avoiding the cache write-miss penalty? I'm pretty sure x86 CPUs long-ago added store buffers to fix that, but I can't think of any other explanation for that incredible stream benchmark discrepancy!Andrei Frumusanu - Monday, March 15, 2021 - link
It's due to the Neoverse N1 cores being able to dynamically transform arbitrary memory writes into non-temporal write streams instead of doing regular RFO before a write as the x86 systems are currently doing. I explain it more in the Altra review:https://www.anandtech.com/show/16315/the-ampere-al...
mode_13h - Monday, March 15, 2021 - link
That's more or less what I recall, but do you know it's *truly* emitting non-temporal stores? Those partially-bypass some or all of the cache hierarchy (I seem to recall that the Pentium 4 actually just restricted them to one set of L2 cache). It would seem to me that implausibly deep analysis would be needed for the CPU to determine that the core in question wouldn't access the data before it was replaced. And that's not even to speak of determining whether code running on *other* cores might need it.On the other hand, if it simply has enough write-buffering, it could avoid fetching the target cacheline by accumulating enough adjacent stores to determine that the entire cacheline would be overwritten. Of course, the downside would be a tiny bit more write latency, and memory-ordering constraints (esp. for x86) might mean that it'd only work for groups of consecutive stores to consecutive addresses.
I guess a way to eliminate some of those restrictions would be to observe through analysis of the instruction stream that a group of stores would overwrite the cacheline and then issue an allocation instead of a fetch. Maybe that's what Altra is doing?
Andrei Frumusanu - Tuesday, March 16, 2021 - link
You're over-complicating things. The core simply sees a stream pattern and switches over to nontemporal writes. They can fully saturate the memory controller when doing just pure write patterns.mode_13h - Wednesday, March 17, 2021 - link
But, do you know they're truly non-temporal writes? As I've tried to explain, there are ways to avoid the write-miss penalty without using true non-temporal writes.And how much of that are you inferring vs. basing this on what you've been told from official or unofficial sources?
Andrei Frumusanu - Saturday, March 20, 2021 - link
It's 100% non-temporal writes, confirmed by both hardware tests and architects.