The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
Topology, Memory Subsystem & Latency
We move onto our usual suite of synthetic tests, trying to expose some of the key hardware characteristics of the systems. The first topic to address is the chip’s physical core topologies, and how inter-core communications take place in the system, particularly interesting since we have access to 2-socket systems.
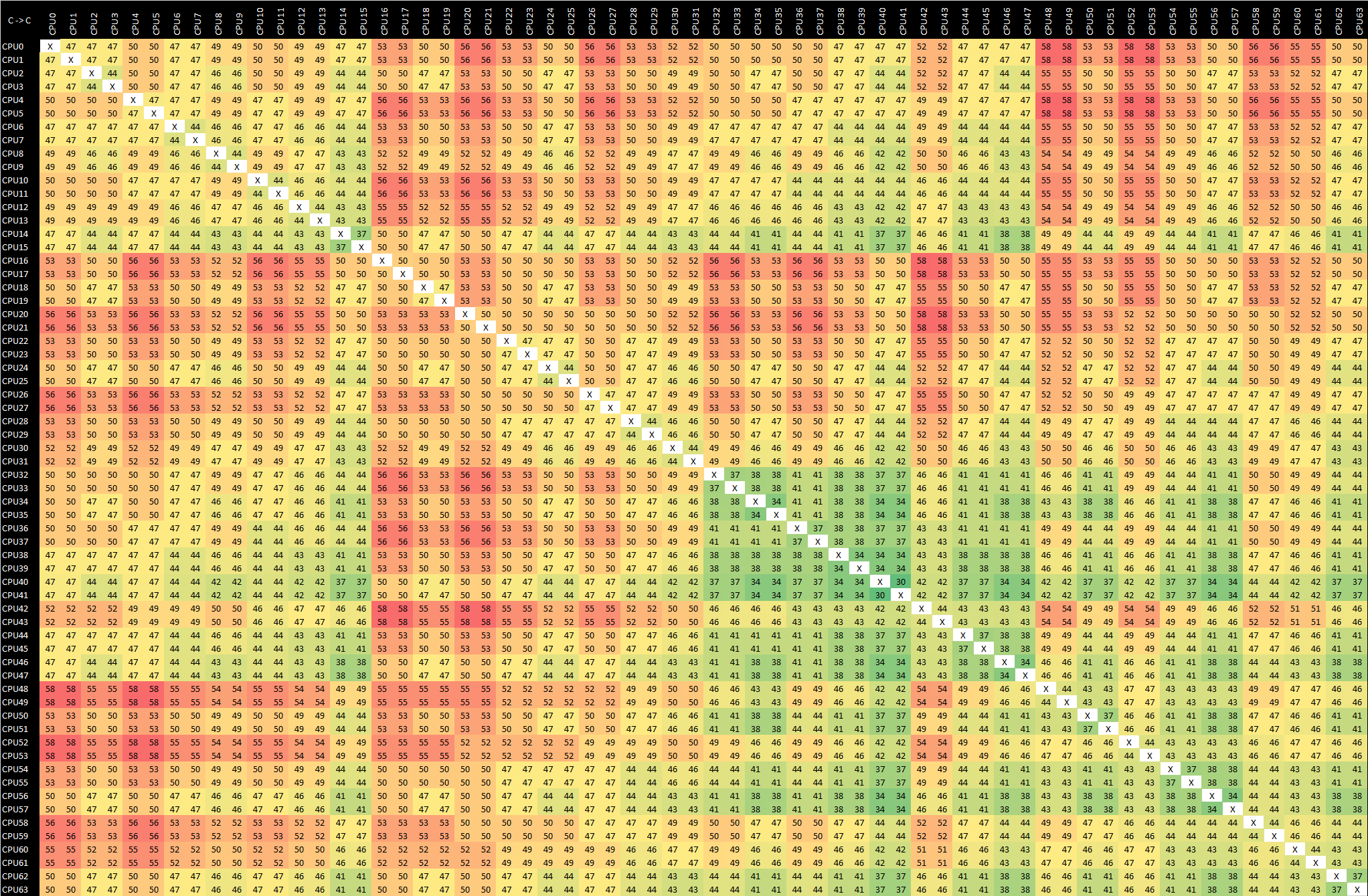
Due to the sheer core-count of the systems, these result matrices are quite huge so I recommend opening up the full resolution images to inspect the detailed results.
As a reminder, our inter-core bounce test consists of an initial main thread which allocates the synchronisation cache line on the core that the executable is spawned on – we try to fix this to the first NUMA node / CPU group of the first socket. This in turn spawns two ping-pong threads which bounce around based on the shared cache line, and we change the affinity of the threads across the system to test out the various core-to-core latencies. Because of the usage of a common shared cache line – usually how real software works, we’re essentially testing core-to-cacheline-to-core – an important distinction to make for some systems which have different cache line placement and cache coherency algorithms.
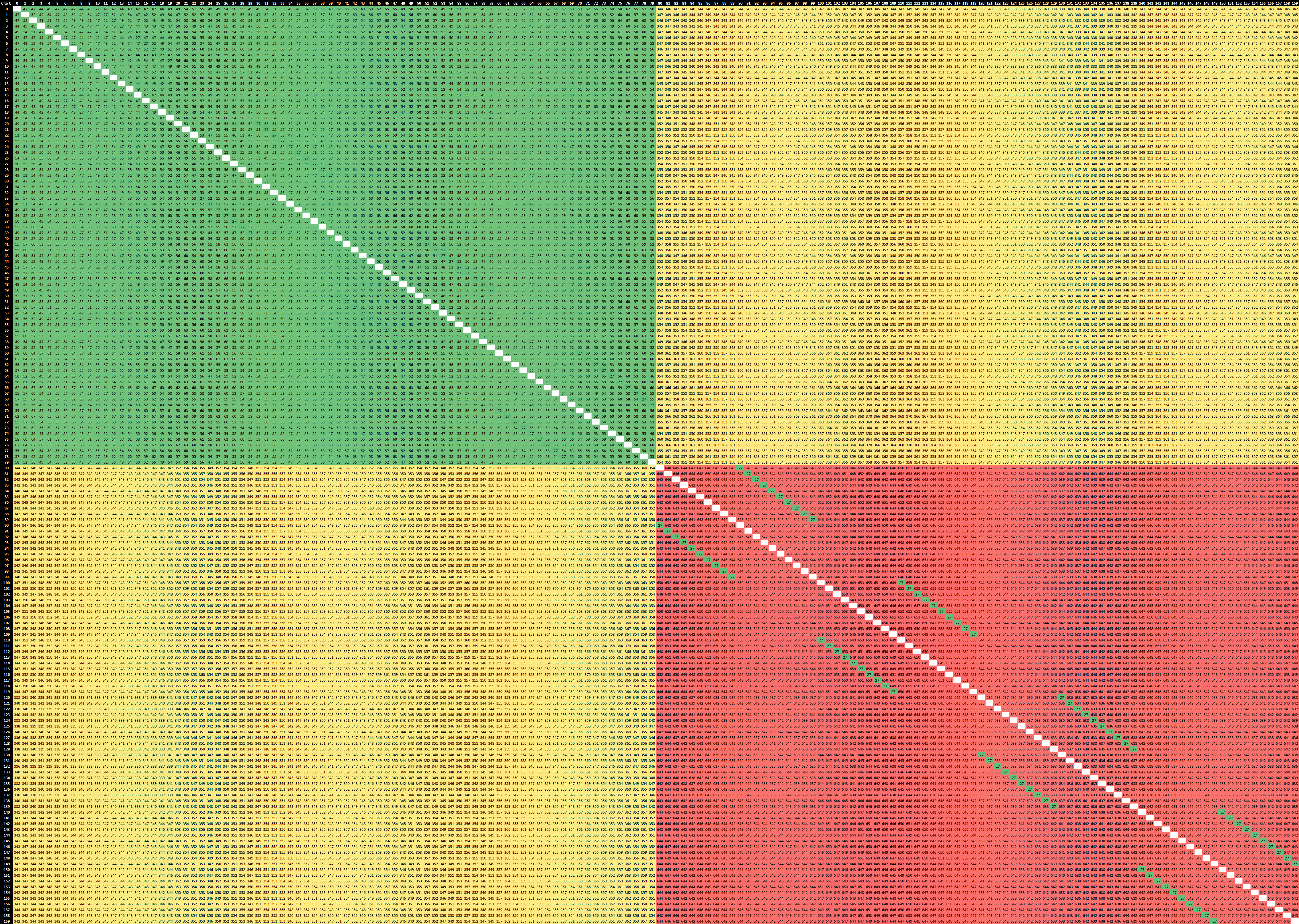
2-Socket Ampere Altra Q80-33
We had already tested the Graviton2 earlier in the year, where we made the distinction between usage of software which compiles to plain Armv8 and exclusive load and excusive store instructions, and the newer Armv8.1 compiled variant of the test which takes advantage of LSE (Large System Extensions) which includes atomic operation instructions – we’re still using the latter variant here on the Altra system.
At first view, in the top-left quadrant of the matrix which represents 80 cores within one single socket, things seem quite similar to the Graviton2 – but not quite. On the Amazon chip’s results what we saw is that the shared cache line remained static within the chip’s mesh structure, meaning cores nearer to that cache slice of the L3 resulted in better latencies compared to cores which were further away.
On the Altra system, the results are quite different here as first of all they’re all more even though it’s a bigger chip with a larger mesh. I tested out the system in a quadrant mode (more on this later) so this might be the reason why things are behaving quite differently to the Graviton2. Interesting to see is this diagonal of results across quarters of a socket landing in at 27ns. I suspect this essentially would represent core-pairs within a single “CPU Tile” within a single mesh node across the chip. If so, then that’s definitely a very different behaviour to the Graviton2.
It actually slipped my mind to re-test this with the chip set to a single monolithic NUMA node so that’s hopefully something I’ll revisit and check if it behaves more similarly to the Graviton2.
When looking at socket-to-socket latencies, we’re looking at latencies of around 350-360ns, which frankly isn’t all that great compared to AMD and Intel’s current multi-socket cache-coherency implementations.
What’s actually quite terrible here, is the inter-core latencies of within the remote socket from the synchronisation shared cache-line. We still very evidently see those 27ns results which we again suspect is within a core-pair CPU tile, but for other cores in the system this actually ends up with a massive latency of around 650ns.
Essentially what the system is doing here, is that one core is sending out a request across the socket, having to be translated from the native AMBA CHI protocol to CCIX, cross the socket, get translated back to CHI to the resident cache line of the initial controller thread, and go back again to the remote socket and incur even further several cache coherency translation penalties.
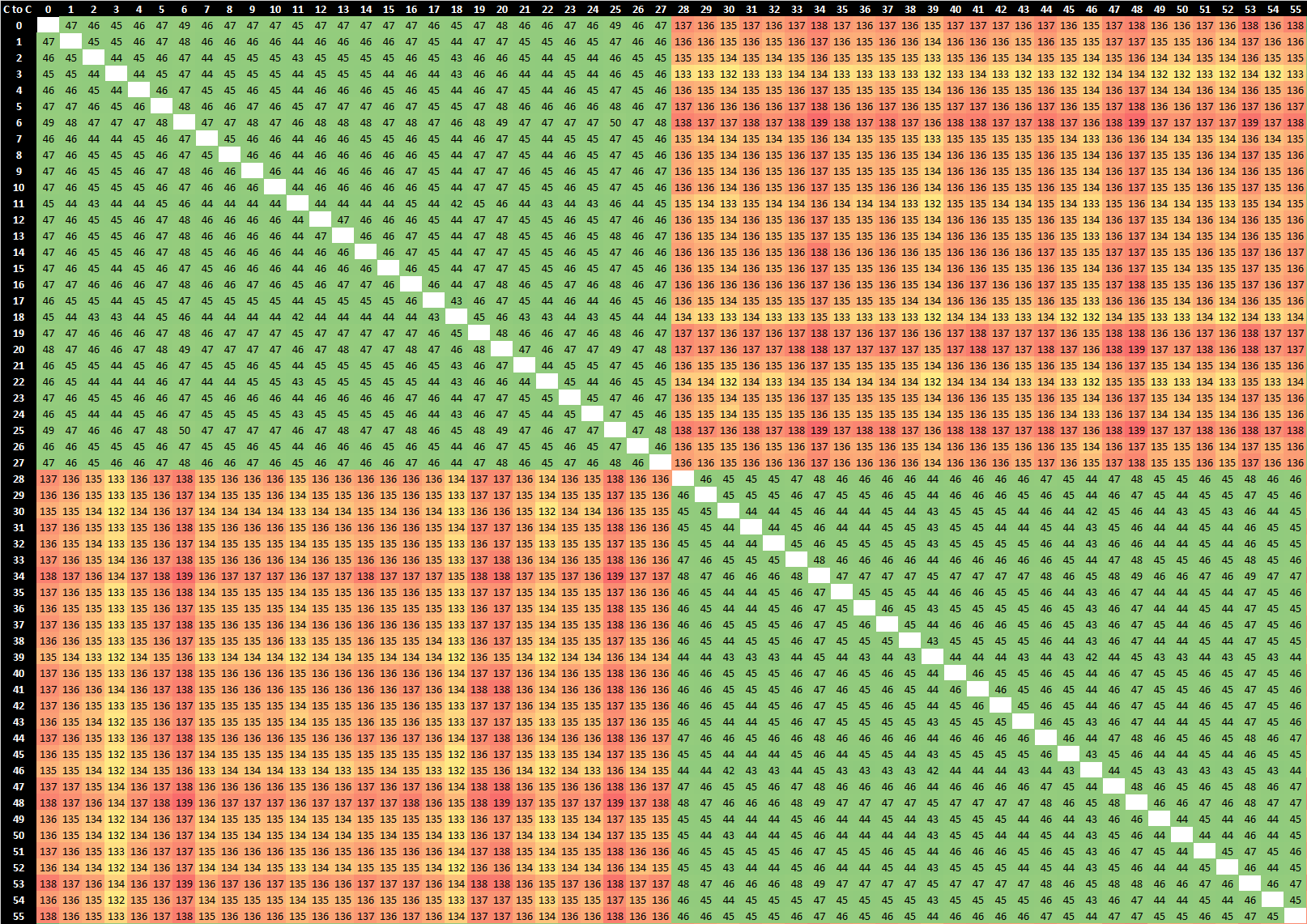
2-Socket Intel Xeon Platinum 8280
Comparing the Altra results to an Intel Xeon Platinum 8280 Cascade Lake 2S system, the latencies within a socket aren’t too different – both implementations are after all monolithic chips with mesh architectures. Keep in mind that the Xeon system here will boost up to 4GHz during the test as we’re only loading 2 cores.
Inter-socket latencies for the Xeon lands in at around 135ns which is very good and a fraction of the Altra system. The chips here use Intel’s UPI interface links and protocols – 3x 10.4GT/s interfaces. In theory the bandwidth here is less than the Altra system, however because it’s all running on the same native protocol across sockets it doesn’t have to incur any penalties as the Altra.
Most importantly, latencies within the second socket are identical to the first socket, meaning the coherency protocols are transferring the shared cache line ownership across sockets even though these are two different NUMA nodes.
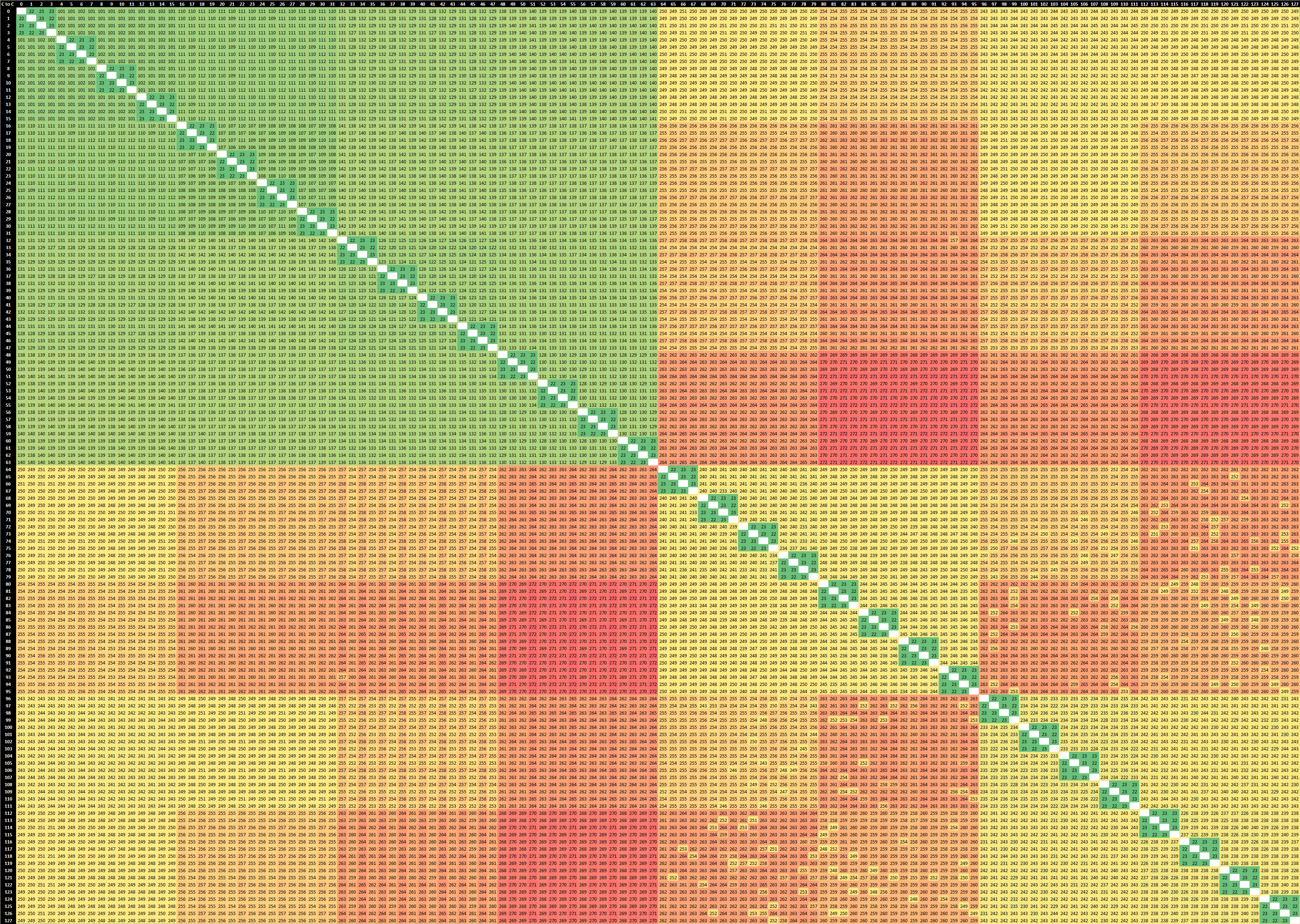
2-Socket AMD EPYC 7742
Finally, AMD’s EPYC 7742 here performs middle-of-the-road across the implementations, with the biggest difference being that it’s not a monolithic cache hierarchy across a whole chip, but rather within 4-core CCX clusters within the CPU chiplets, which are then further divided into physical quadrants on the I/O die which connects the 8 chiplets of a single-socket package.
Socket-to-socket, the Rome chip essentially doubles up the worse in-socket latencies. Within the remote socket, AMD is able to locally copy ownership of the shared cache-line within a CCXs, but access latencies between CCXs within the remote socket still seem to have to communicate back to the home socket with similar latencies as the socket-to-socket core figures.
Still, even AMD’s unorthodox system vastly outperforms the socket-to-socket communication of the Ampere Altra by not having to translate between different coherency protocols – that’s the advantage of owning the IP and designing the protocols yourself. Ampere here would have to rely on Arm to release a native AMBA CHI-like implementation to support inter-socket coherency across two mesh systems.
Memory Latency
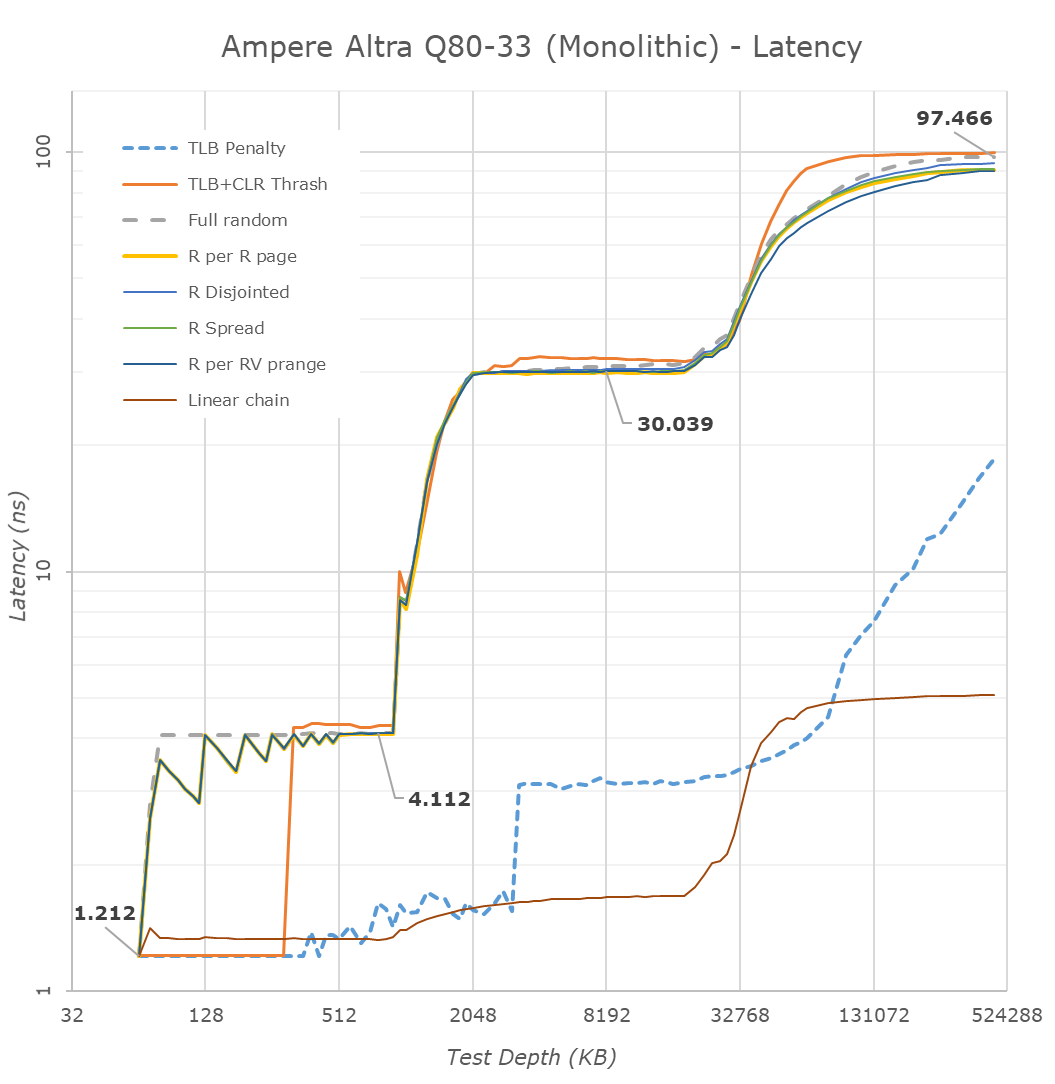
In terms of memory latency, the new Altra Q80-33 and its siblings should be quite straightforward.
Starting off with the monolithic native results of the Altra, we can see the full cache hierarchy of the chip, with the 64KB L1D and 1MB L2 caches of the Neoverse N1 cores, as well as the 32MB L3 cache of the mesh.
What stands out here compared to the Graviton2 results earlier in the year, is that the Altra’s advanced prefetchers are essentially all disabled by default, and all our access patterns are behaving essentially identical, simply exposing the hardware latencies, with only the next-line prefetcher still being active for linear streams.
That’s interesting, and maybe a decision made due to the sheer core-count of the system – every bit of bandwidth is needed for feed all the cores with usable data, so there’s no room speculative prefetching.
DRAM memory latency of the system is excellent at 97ns and below that of the Graviton2 – though one big note we have to make here is that the Altra system is running CentOS with 64KB pages by default, which will give the system some advantage in TLB misses.
Compared to a Xeon 8280, the Altra system still loses out in memory latency even though both are monolithic chips, and the Xeon is actually running slower DDR4-2933 versus DDR-3200 of the Altra and EPYC.
In NPS1 mode, the EPYC 7742 has to interleave memory accesses across all of its I/O die quadrants which on top of the chiplet architecture results in larger memory latency penalties, up to 133ns here at our equal depth measurement point.

One speciality of the Altra is that Ampere actually offering various operating modes when running the chip in different NUMA configurations: You can either treat the chip as a native large monolithic design, just like the hardware is designed, or you can subdivide the mesh and memory controllers into either two hemispheres, or four quadrants. The point of subdividing the chip this way even though it’s a monolithic design seems at first counter-productive, but Ampere says there are practical benefits to this.
The first benefit would be that this allows for better segregation of workloads across cloud workloads. A customer deploying an Altra system in the cloud would want to run multiple virtual machines on a single chip – subdividing the chip into quadrants here has the practical benefit of completely eliminating effects of noisy-neighbours within that quadrant. Furthermore, this actually also subdivides the cache of the mesh system, meaning that the 32MB get divided into 8MB quadrants, something which one can immediately see in the graph.
Beyond reducing cross-chip traffic and reducing noisy neighbours in VM systems, the division slightly also improves latencies. For example, DRAM accesses go down from 97ns to 93ns because a CPU only accesses its two-nearest memory controller channels instead of accessing the further across-the-chip controllers. Similarly, the L3 latency also slightly goes down from 30.0ns to 27.6ns as it has to interleave accesses just across the nearest located quadrant cache node slices, reducing wire latency.
Of course, because the Altra is still a monolithic chip, the benefits aren’t quite as significant as what we see on AMD’s EPYC Rome system which sees DRAM latency go down from 133ns to 117ns due to it no longer hopping around Infinity Fabric nodes across the I/O die quadrants.
Memory Bandwidth
Multi-core memory bandwidth is a topic I don’t really enjoy, due to nuances of different systems and how memory behaves across large systems. The data that you want to showcase has to serve a pre-determined purpose – either you’re trying to benchmark things from a software perspective, or you want to expose hardware capabilities. STREAM is a benchmark that has been abused quite a bit over the years in that it crossed this boundary between scopes far too much, especially across multi-socket systems. The vanilla version is meant to benchmark memory within a single memory node, which is exactly what we’ll be doing. On top of that, we’re also compiling a vanilla copy of the benchmark using plain optimisation flags, further avoiding the rabbit-hole of apples-and-oranges comparisons that are done out there in the wild.
Having that in mind, let’s check out the STREAM Triad results of the various processors:
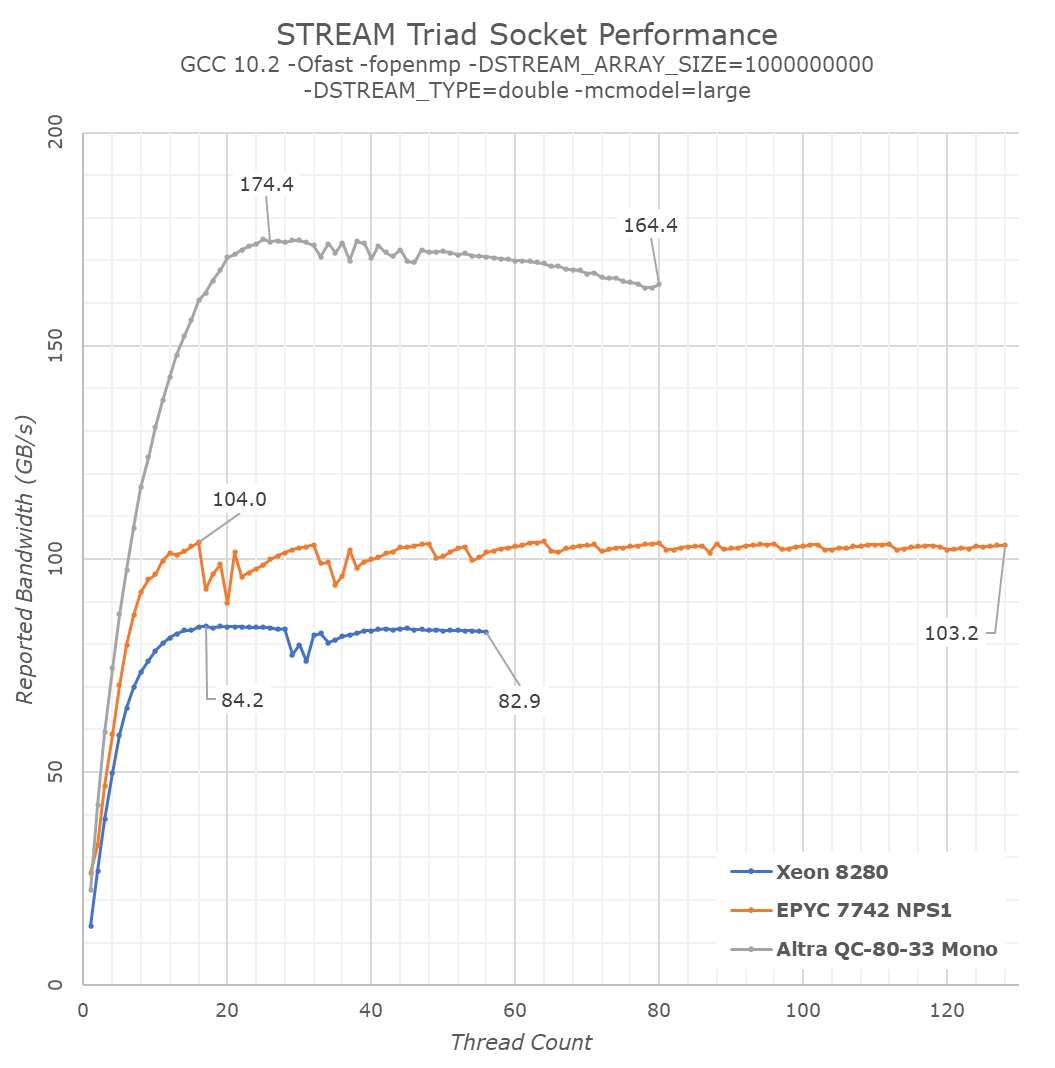
What first comes to light of course the difference between the new Altra processor, and the x86 platforms which appear to be performing much worse. It’s again at this point where we have to disambiguate what we’re measuring, software performance, or hardware behaviour?
From a software standpoint, the Altra indeed vastly outperforms the competition, and the reason for this is an architecture and microarchitecture one. The Neoverse-N1 cores in the Altra system are able to take advantage of Arm’s weaker memory model: the CPU cores will detect that they’re working on a streaming workload, meaning it’s going over large amounts of data with no re-use of the previous results. The CPU thus automatically converts its memory write operations into non-temporal ones.
The difference between “regular” RFO (Read For Ownership) memory writes and non-temporal writes is that the former incurs further cache coherency operations on the part of the hardware. For example, writing a 64B cache-line to memory write from a software perspective here actually results in 128B of hardware traffic as the core has to first read out the target cache line before it can write to it.
For STREAM, for example in the Triad test whose kernel is a[j] = b[j]+scalar*c[j];, the test assumes 3 memory operations, one write to a[j] and two reads out of b[j] and c[j], where in reality for x86 systems it’s actually 4 memory operations, thus 1.33x the reported bandwidth from the test. The memory copy kernel which is c[j] = a[j]; assumes there to be 2 memory operations, while in reality there’s 3, thus 1.5x higher.
It’s possible to compile STREAM to outright explicitly use non-temporal stores on x86 systems, with the test using instructions that hint out to the core to avoid checking the cache line to be written. Essentially this is what various ICC compiled and optimised variants of STREAM do.
Unfortunately, when using such optimised variants of the benchmark you’re no longer testing apples to apples software performance, but rather something else, and tread into the realm of trying to measure what the hardware is doing. In my view that’s not what STREAM is meant for. I have custom tests that showcase vastly higher bandwidth than STREAM on all platforms, but they’re doing something completely different in terms of design.
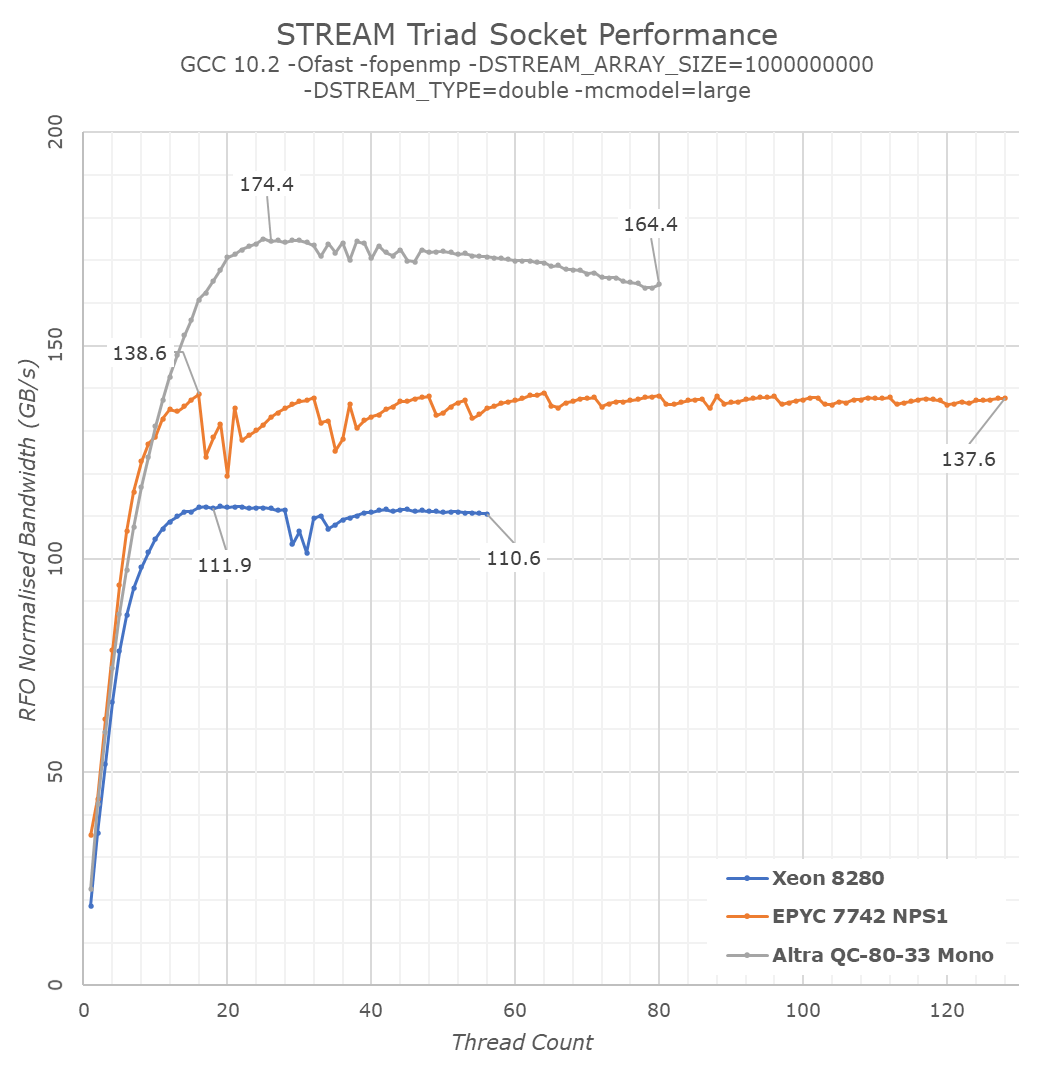
In any case, even if we were to compensate with the 1.33x or 1.5x factors for the x86 systems, they don’t reach the memory performance that the Altra Q80-33 is showcasing here. Arm’s smart usage of the architecture’s memory model flexibility and ability to transforms arbitrary streams into non-temporal operations is a real-world benefit to all software. As a note, this behaviour is also present on mobile cores from Arm from the Cortex-A76 onwards, Samsung’s cores from M4 onwards, and from this year’s Apple Firestorm cores in the A14 and M1.








{kind=link}
{kind=link}
148 Comments
View All Comments
realbabilu - Friday, December 18, 2020 - link
well it support fortran also using Arm Fortran Compiler, unlike m1.realbabilu - Friday, December 18, 2020 - link
my bad. Numerical Algorithms Group (Nag) has fortran for m1. lets battle begin X86 vs armGruenSein - Friday, December 18, 2020 - link
The userbase for fortran on M1 is probably super small anyway. Although.. I can see the HPC cluster entirely made up of Macbook Airs before my eye. Just like the PS3-cluster the air force used to have ;)davidorti - Friday, December 18, 2020 - link
Wouldn't it be way cheaper a cluster of minis?Flunk - Friday, December 18, 2020 - link
No, the hardware would be cheaper but the maintenance would be much more time-intensive. That's why companies that need a lot of processing hardware buy enterprise level hardware. The cost of maintaining the system quickly eclipses the hardware costs. And if you're using a computer to make money, quite often the hardware cost is only a small amount of your costs.FunBunny2 - Friday, December 18, 2020 - link
I dunno about the "quite often the hardware cost is only a small amount of your costs." part. as modern production methods have been ever more automated, (I'm talkin to you, bitcoin mining), there's almost no other cost. now, some may argue, in the extreme case of mining for instance, that power is the largest component; but isn't that 'hardware' cost? it certainly isn't labor or interest or land or even CxOs' cut. fewer and fewer automation efforts are conducted in assembler or even naked C or java or FORTRAN, but in frameworks, often with bespoke syntax and with headcounts way lower than their native languages. so, yeah, now into the foreseeable future, hardware is the biggest byte.at_clucks - Friday, December 18, 2020 - link
The point was a cluster of Minis would probably be cheaper than a cluster of Airs because why pay for screen, battery, keyboard and all that.Spunjji - Monday, December 21, 2020 - link
True, but I did enjoy the holistic response. Just think of the potential: batteries are a built-in UPS, and you don't need to mess about with any sort of KVM arrangement - if a node drops out, you can go right to it and poke it to find out what's up!ProDigit - Saturday, December 19, 2020 - link
I guess the results showing lower TDP despite 100% load, means that the cores are sometimes idling for a part of their clock frequency.It means the cpu is lacking buffers, and isn't fully optimized.
mode_13h - Sunday, December 20, 2020 - link
Buffers and even cache can't completely avoid memory bottlenecks.Also, you can run a core 100% on code with very little parallelism and not draw much power. Code with lots of ILP and especially vector arithmetic burns a lot more power, which is why AVX2 and especially AVX-512 trigger significant clock-throttling on Intel.