The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
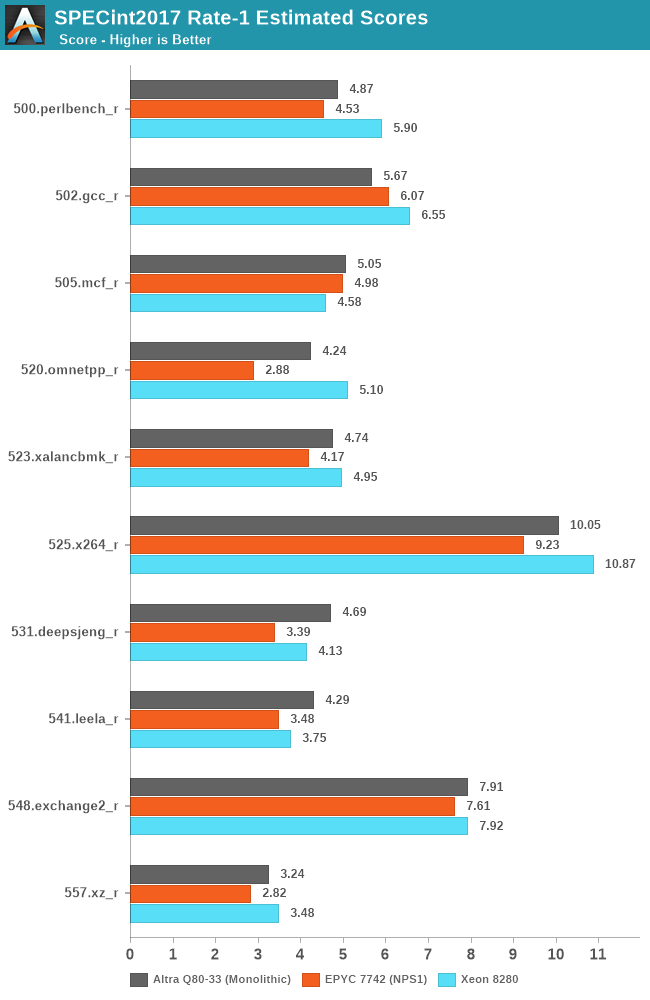
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
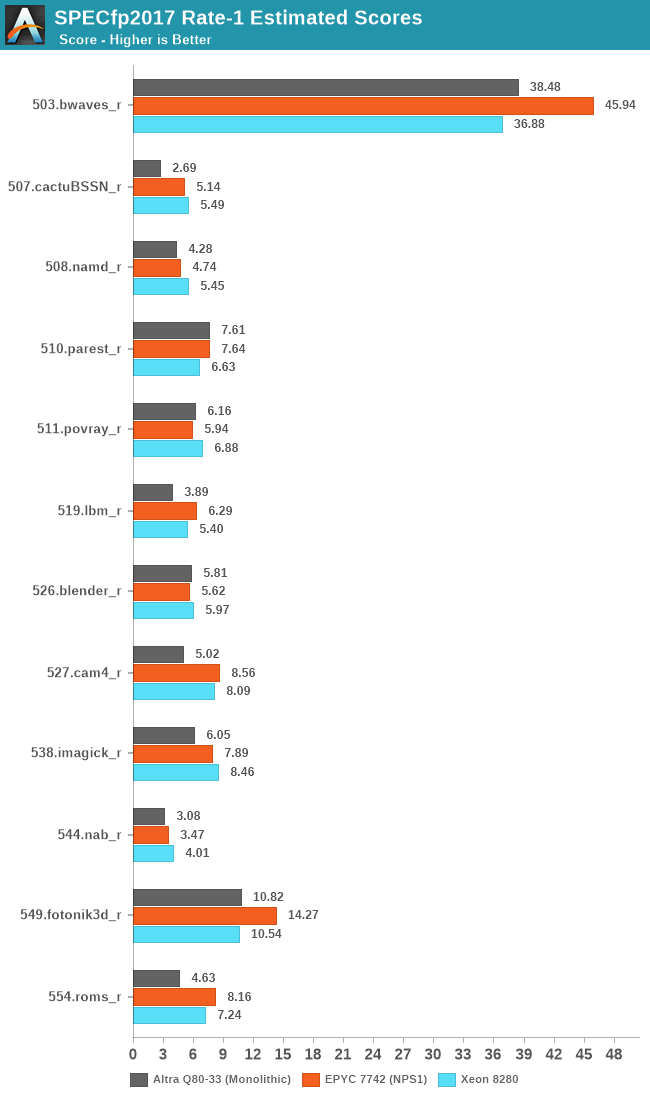
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
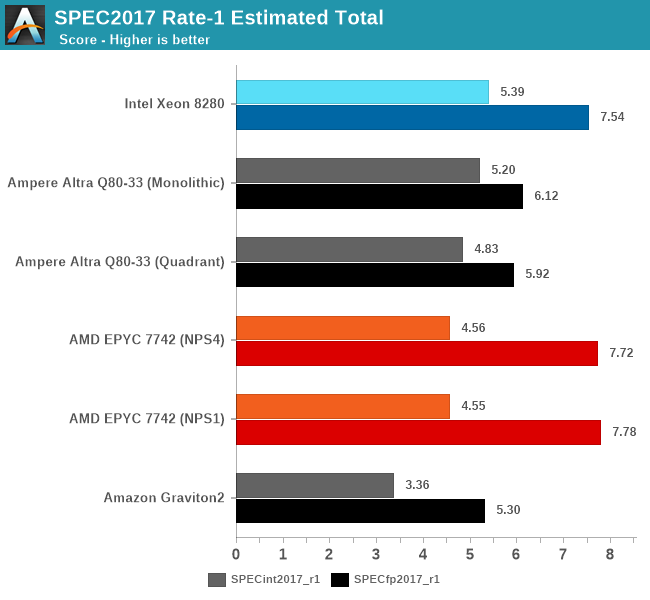
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.








148 Comments
View All Comments
mode_13h - Thursday, December 31, 2020 - link
Isn't Blender included in SPECfp2017 as 526.blender_r? Or is that something different?Teckk - Friday, December 18, 2020 - link
Whoever decided on naming these products — fantastic job. Simple, clear and effective.Maybe you can offer some free advice to Intel and Sony.
Calin - Friday, December 18, 2020 - link
The answer to the question of "how powerful it is" is clear - more than good enough.The real question in fact is:
"How much can they produce?"
AMD has the crown in x86 processor performance, but this doesn't really matter very much as long as they can build enough processors only for a part of the market.
jwittich - Friday, December 18, 2020 - link
How many do you need? :)Bigos - Friday, December 18, 2020 - link
64kB pages might significantly enhance performance on workload with large memory sets, as the TLB will be up to 16x less used. On the other hand, memory usage of the Linux file system cache will also increase a lot.Would you be able to test the effect of 64kB vs 4kB page size on at least some workloads?
Andrei Frumusanu - Friday, December 18, 2020 - link
It's something that I wanted to test but it requires a OS reinstall / kernel recompile - I didn't want to get into that rabbit hole of a time sink as already spent a lot of time verifying a lot of data across the three platforms over a few weeks already.arnd - Friday, December 18, 2020 - link
I'd love to see that as well. For workloads that use transparent huge pages, there should not be much difference since both would use 2MB huge pages (512*4KB or 32*64KB), plus one or more even larger page sizes, but it needs to be measured to beThe downsides of 64KB requiring larger disk I/O and more RAM are often harder to quantify, as most benchmarks try to avoid the interesting cases.
I've tried benchmarking kernel compiles on Graviton2 both ways and found 64kB pages to be a few percent faster when there is enough RAM, but forcing the system to swap by limiting the total RAM made the 64kB kernel easily 10x to 1000x slower than the 4kB one, depending on the how the available memory lined up with the working set.
abufrejoval - Friday, December 18, 2020 - link
Thank you for the incredible amount of information and the work you put into this: Anandtech's best!Yet I wonder who would deploy this and where. The purchasing price of the CPU would seem to become a rather miniscule part of the total system cost, especially once you go into big RAM territory. And I wonder if it's not similar with the energy budget: I see my larger systems requiring more $ and Watts on RAM than on the CPUs. Are they doing, can they do anything there to reduce DRAM energy consumption vs. Intel/AMD?
The cost of the ecosystem change to ARM may be less relevant once you have the scale to pay for it, but where exactly would those scale benefits come from? And what scales are we talking about? Would you need 100k or 1m servers to break even?
And what sort of system load would you have to reach/maintain to have significant energy advantages vs. x86 iron?
Do they support special tricks like powering down quadrants and RAM banks for load management, do they enable quick standby/actvation modes so that servers can be take off and on for load management?
And how long would the benefits last? AMD has demonstrated rather well, that the ability to execute over at least three generations of hardware are required to shift attention even from the big guys and they have still all the scaling benefits the x86 installed base provides.
These guys are on a 2nd generation product, promise 3rd but essentially this would seem to have the same level of confidence as the 1st EPIC.
askar - Friday, December 18, 2020 - link
Would you mind testing ML performance, i.e. python's SKLearn library classes that can be multithreaded (random forest for example)?mode_13h - Sunday, December 20, 2020 - link
MLPerf?