The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
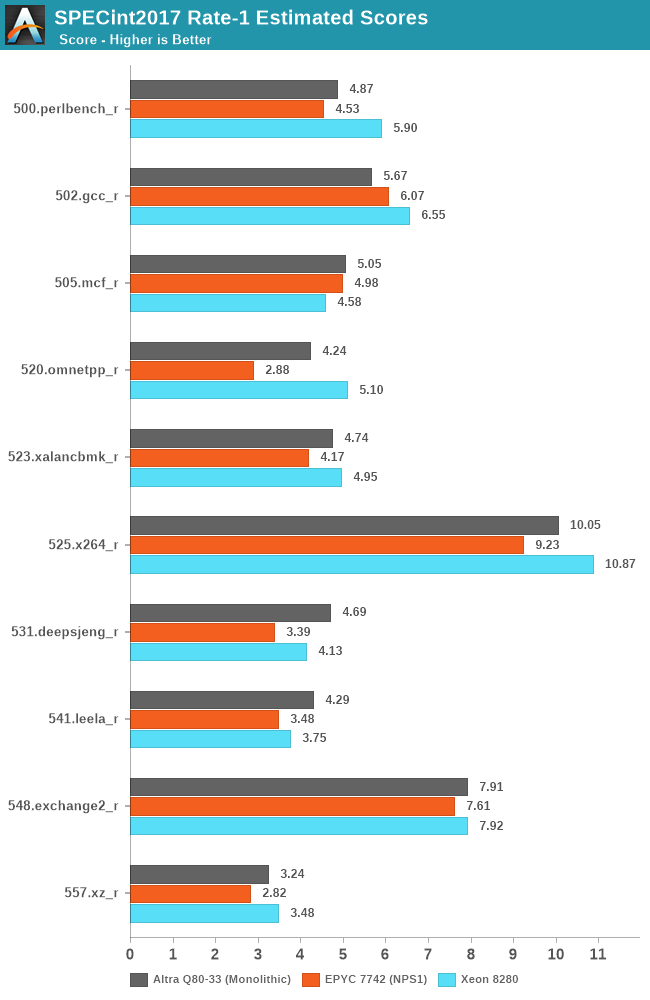
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
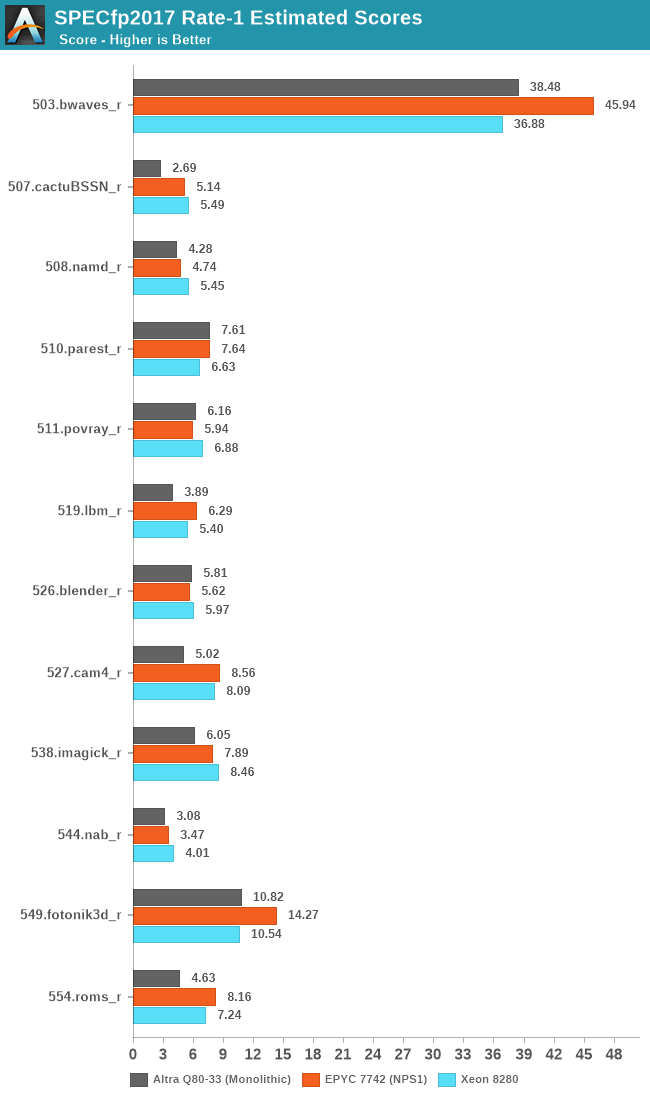
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
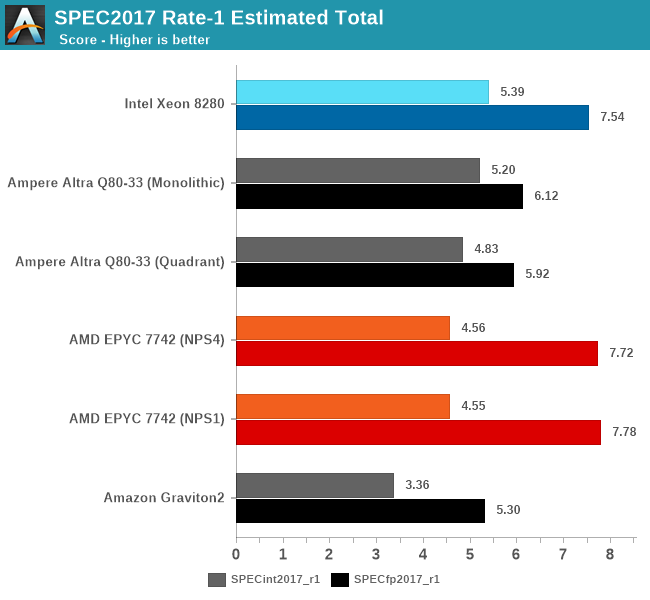
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.








148 Comments
View All Comments
tygrus - Saturday, December 19, 2020 - link
Next step would be to see how ARM performed with 256MB (or more) of cache. The early models didn't suit many workloads compared to the general purpose kings (x86-64). Each generation of ARM based server chips have seen an increase to the number of suitable workloads thus more general purpose. Adding more specialised instructions to x86 has diminishing returns that increase the complexity of decoding & execution it's always good to be challenged "can we make it simpler & faster?".mode_13h - Sunday, December 20, 2020 - link
ARM has been doing some of the same, though. Look at the evolution of ARMv8-A as it has aged, and you'll see several bolt-ons to target additional markets:* new atomics
* signed, saturating multiplies
* CRC instructions
* half-precision floating point
* SVE (their answer to AVX/AVX-512)
* complex number support
* an instruction specifically for floating-point conversion in Javascript
* integer dot products
* random number generation
* matrix multiply & manipulation
* BFloat16 support
* a smattering of other virtualization and security-oriented additions
That's not a small list, and definitely not a less-is-more approach.
Leeea - Sunday, December 20, 2020 - link
Very interesting.Great article.
Sivar - Sunday, December 20, 2020 - link
Typo report, conclusion: "The se*ver landscape is changing very quickly. "Sivar - Sunday, December 20, 2020 - link
Imagine the response if someone made a prediction of this statement just five years ago:"Intel’s current Xeon offering simply isn’t competitive in any way or form at this moment in time. Cascade Lake is twice as slow and half as efficient – so unless Intel is giving away the chips at a fraction of a price, they really make no sense."
mode_13h - Sunday, December 20, 2020 - link
Heh, good call!Makste - Monday, December 21, 2020 - link
Truly exciting times. Thanks for the review.There's going to be a massive restructuring in "computeverse".
I hope they'll be a merger at one point.
hyc - Monday, December 21, 2020 - link
It would've been more appropriate to compare Q64-33 to AMD to assess the merits of each architectural design. Could you repeat some of these tests, limiting the Altra to only 64 cores/threads?Wilco1 - Tuesday, December 22, 2020 - link
It might be an interesting comparison with SMT disabled since the extra 25% of cores are the alternative to adding SMT. However should we also limit EPYC to 32MB L3 to make things more equal?hyc - Friday, December 25, 2020 - link
Are you saying that turning off 16 cores in the Q80-33 is not the equivalent of running a Q64-33?Turning off SMT may have some merits, depending on workload.