The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
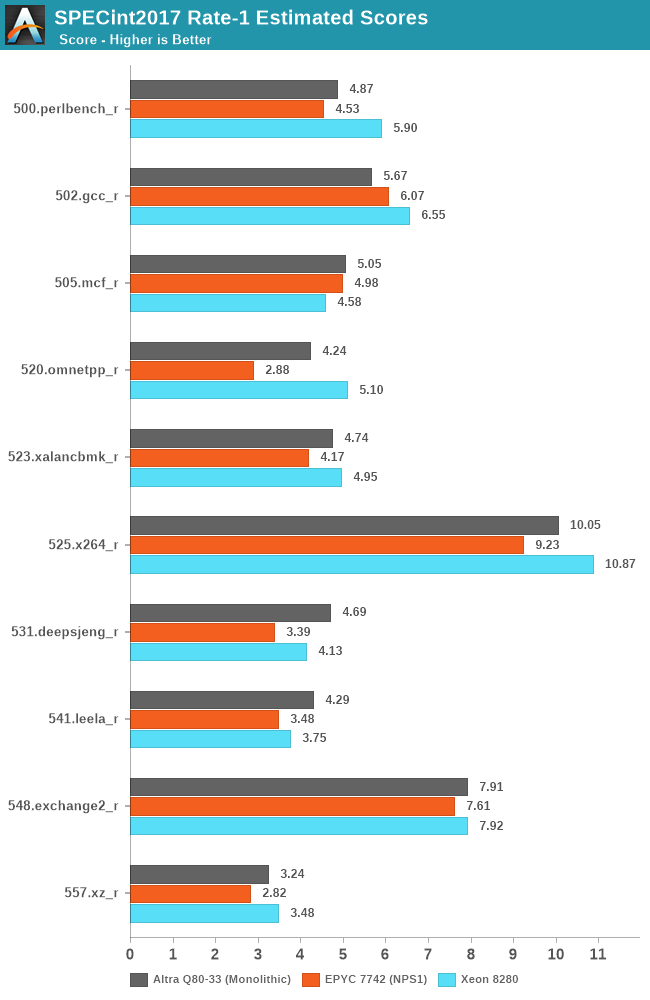
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
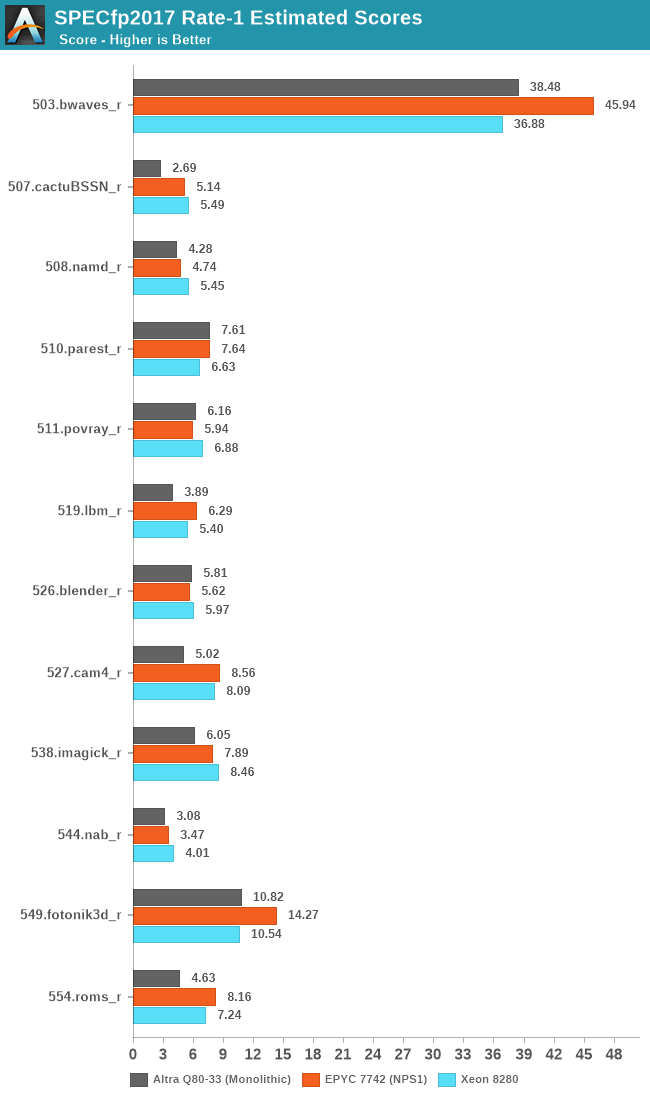
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
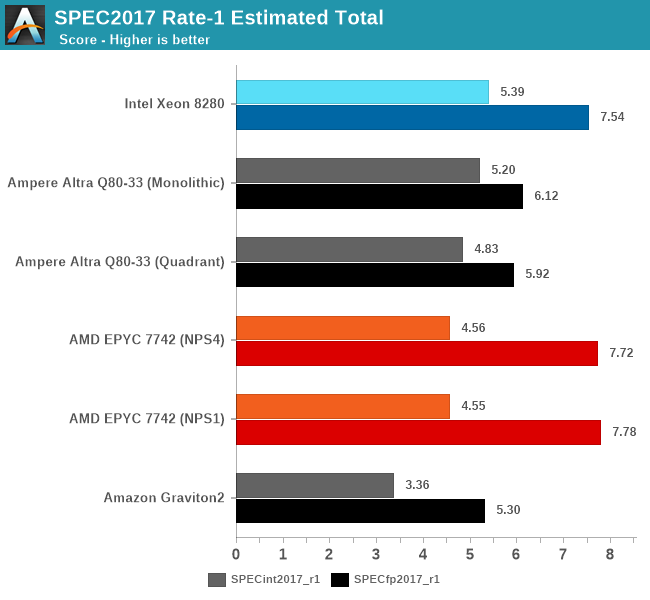
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.








148 Comments
View All Comments
Brane2 - Saturday, December 19, 2020 - link
Meh. Nothing special. it has been benchmarked on Phoronix and it performed more or less on par with Rome. 80 newest ARM cores against 64 mature x86 cores within constrained power envelope.Naples is just about to come out and I suspect some time after that AMD will have something like really wide new RISC-V cores.
Wilco1 - Saturday, December 19, 2020 - link
It won most benchmarks on Phoronix while using significantly less power. Yes Milan is about to be released, and it will have to compete with the 128-core Altra Max. Which do you believe is going to win - 64 SMT cores or 128 real cores?mode_13h - Sunday, December 20, 2020 - link
It actually won less than half of the benchmarks on phoronix, since a number of those graphs just re-state the results in score/W. There are also questions over some of the compiler options used on those benchmarks, since many of the tests are compiled with options that won't enable AVX on benchmarks where it should be beneficial (yet, not having SVE, the N1 cores are at no such disadvantage).Wilco1 - Monday, December 21, 2020 - link
"should be beneficial" -> "might help in a few limited cases". AVX/AVX512 isn't that useful for general C/C++ code. You typically only see large gains when people optimize using intrinsics.mode_13h - Monday, December 21, 2020 - link
Intrinsics don't compile if they're for a CPU arch beyond what the compiler is being instructed to target. So, even packages where people take the time to optimize with intrinsics need to guard them with compile-time checks to ensure the CPU target is capable of executing those instructions.Compilers do generate vectorized code. I don't know how well GCC is doing on that front, lately, but the TNN tests should be a good way to see that. Too bad those tests don't use -march=native.
What's interesting about TNN is I'm looking at the exact source revision Phoronix is using, and it seems they've completely dropped their backend for x86. The source/tnn/device/x86/ is simply missing. So, I wonder if they decided the compiler was good enough that they didn't need to bother with their own hand-optimized code for it, or if they just decided they don't care how fast their stuff runs on it.
See:
* https://openbenchmarking.org/innhold/83a730ed41d4e...
* https://github.com/Tencent/TNN/tree/v0.2.3
Wilco1 - Monday, December 21, 2020 - link
TNN does not benefit from -march=native. Phoronix uses the generic C++ version which doesn't benefit from vectorization. Try it yourself.Optimized versions using intrinsics typically use runtime checks so you automatically get the fastest version that works on your CPU. The makefile selects the right ISA variant for any files using intrinsics. But none of this is used in the TNN test.
mode_13h - Monday, December 21, 2020 - link
> TNN does not benefit from -march=native. Phoronix uses the generic C++ version which doesn't benefit from vectorization. Try it yourself.At this point, I probably will.
> Optimized versions using intrinsics typically use runtime checks so you automatically get the fastest version that works on your CPU.
That's a whole additional level of effort for the developers. For them to bother compiling and conditionally calling different versions only makes sense if they think their main userbase aren't going to bother recompiling specifically for their hardware. In the case of specialized packages, it's reasonable to expect your users to take a little trouble for the best performance. It's really things like very low-level libs or multimedia code where you tend to see the sort of elaborate runtime detection and dynamic codepath selection that you're describing.
mode_13h - Monday, December 21, 2020 - link
I think Basis Universal and High Performance Conjugate Gradient are some other cases where the wider SIMD of Zen2 and Skylake-SP should confer significant benefit.Wilco1 - Monday, December 21, 2020 - link
"should give significant benefit" -> "might give some benefit". I suggest you try out. Autovectorization is not nearly as good as you seem to believe, and the overall speedup is often disappointing even if some loops are 10-20x faster.vinayshivakumar - Saturday, December 19, 2020 - link
I am a bit puzzled why none of these processors support SMT... Can someone shed light on why this is the case ?