Apple Announces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14
by Andrei Frumusanu on November 10, 2020 3:00 PM EST- Posted in
- Apple
- Apple A14
- Apple Silicon
- Apple M1
From Mobile to Mac: What to Expect?
To date, our performance comparisons for Apple’s chipsets have always been in the context of iPhone reviews, with the juxtaposition to x86 designs being a rather small footnote within the context of the articles. Today’s Apple Silicon launch event completely changes the narrative of what we portray in terms of performance, setting aside the typical apples vs oranges comparisons people usually argument with.
We currently do not have Apple Silicon devices and likely won’t get our hands on them for another few weeks, but we do have the A14, and expect the new Mac chips to be strongly based on the microarchitecture we’re seeing employed in the iPhone designs. Of course, we’re still comparing a phone chip versus a high-end laptop and even a high-end desktop chip, but given the performance numbers, that’s also exactly the point we’re trying to make here, setting the stage as the bare minimum of what Apple could achieve with their new Apple Silicon Mac chips.
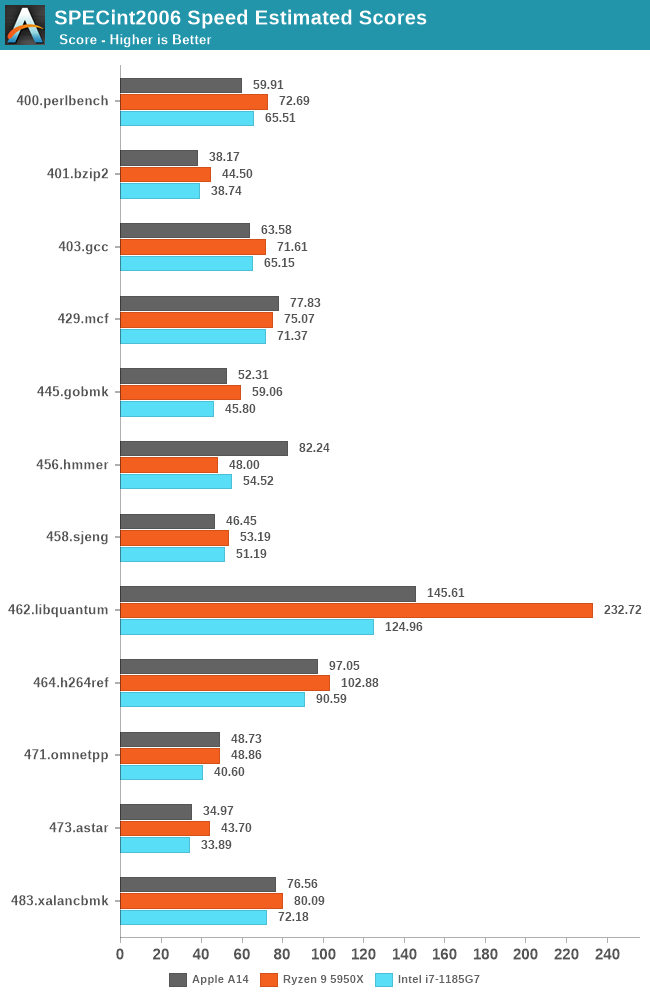
The performance numbers of the A14 on this chart is relatively mind-boggling. If I were to release this data with the label of the A14 hidden, one would guess that the data-points came from some other x86 SKU from either AMD or Intel. The fact that the A14 currently competes with the very best top-performance designs that the x86 vendors have on the market today is just an astonishing feat.
Looking into the detailed scores, what again amazes me is the fact that the A14 not only keeps up, but actually beats both these competitors in memory-latency sensitive workloads such as 429.mcf and 471.omnetpp, even though they either have the same memory (i7-1185G7 with LPDDR4X-4266), or desktop-grade memory (5950X with DDR-3200).
Again, disregard the 456.hmmer score advantage of the A14, that’s majorly due to compiler discrepancies, subtract 33% for a more apt comparison figure.
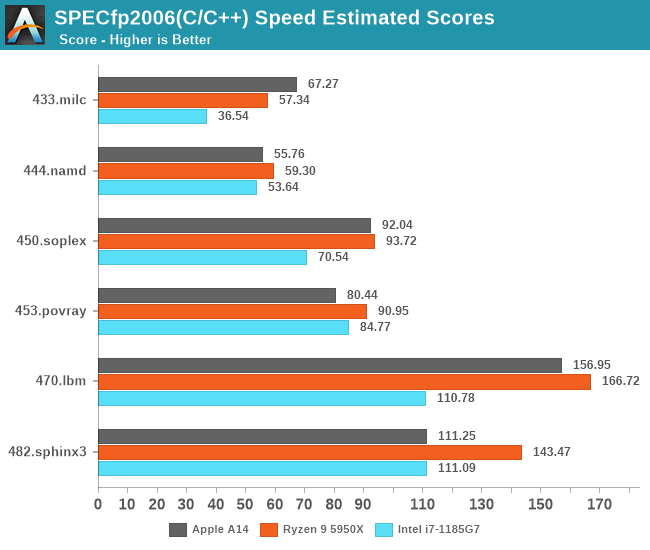
Even in SPECfp which is even more dominated by memory heavy workloads, the A14 not only keeps up, but generally beats the Intel CPU design more often than not. AMD also wouldn’t be looking good if not for the recently released Zen3 design.
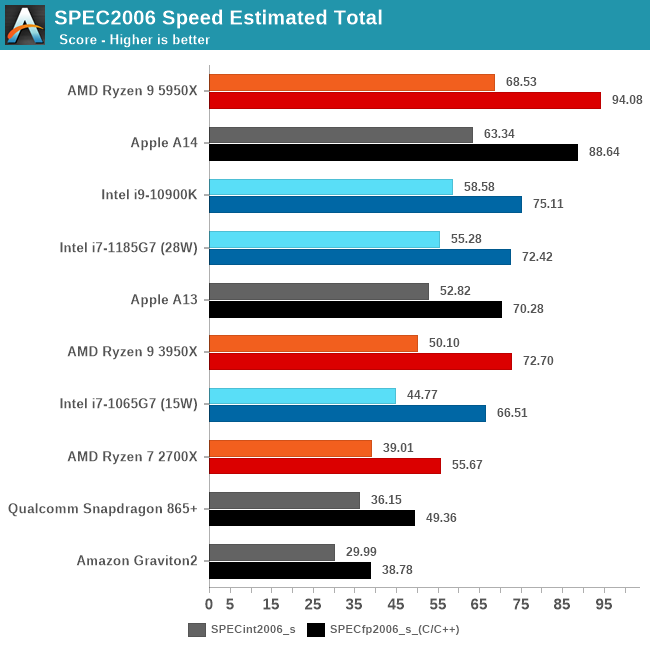
In the overall SPEC2006 chart, the A14 is performing absolutely fantastic, taking the lead in absolute performance only falling short of AMD’s recent Ryzen 5000 series.
The fact that Apple is able to achieve this in a total device power consumption of 5W including the SoC, DRAM, and regulators, versus +21W (1185G7) and 49W (5950X) package power figures, without DRAM or regulation, is absolutely mind-blowing.
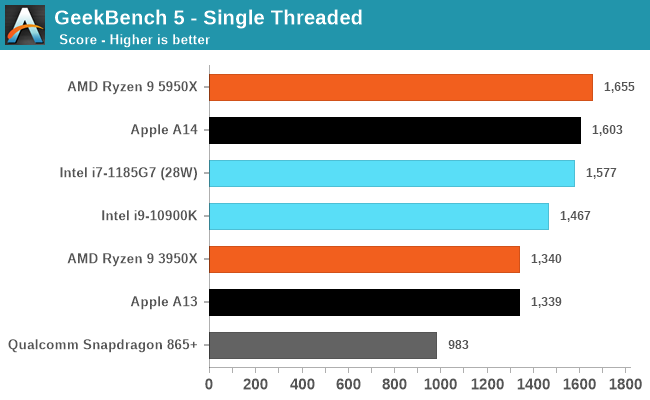
There’s been a lot of criticism about more common benchmark suites such as GeekBench, but frankly I've found these concerns or arguments to be quite unfounded. The only factual differences between workloads in SPEC and workloads in GB5 is that the latter has less outlier tests which are memory-heavy, meaning it’s more of a CPU benchmark whereas SPEC has more tendency towards CPU+DRAM.
The fact that Apple does well in both workloads is evidence that they have an extremely well-balanced microarchitecture, and that Apple Silicon will be able to scale up to “desktop workloads” in terms of performance without much issue.
Where the Performance Trajectory Finally Intersects
During the release of the A7, people were pretty dismissive of the fact that Apple had called their microarchitecture a desktop-class design. People were also very dismissive of us calling the A11 and A12 reaching near desktop level performance figures a few years back, and today marks an important moment in time for the industry as Apple’s A14 now clearly is able to showcase performance that’s beyond the best that Intel can offer. It’s been a performance trajectory that’s been steadily executing and progressing for years:
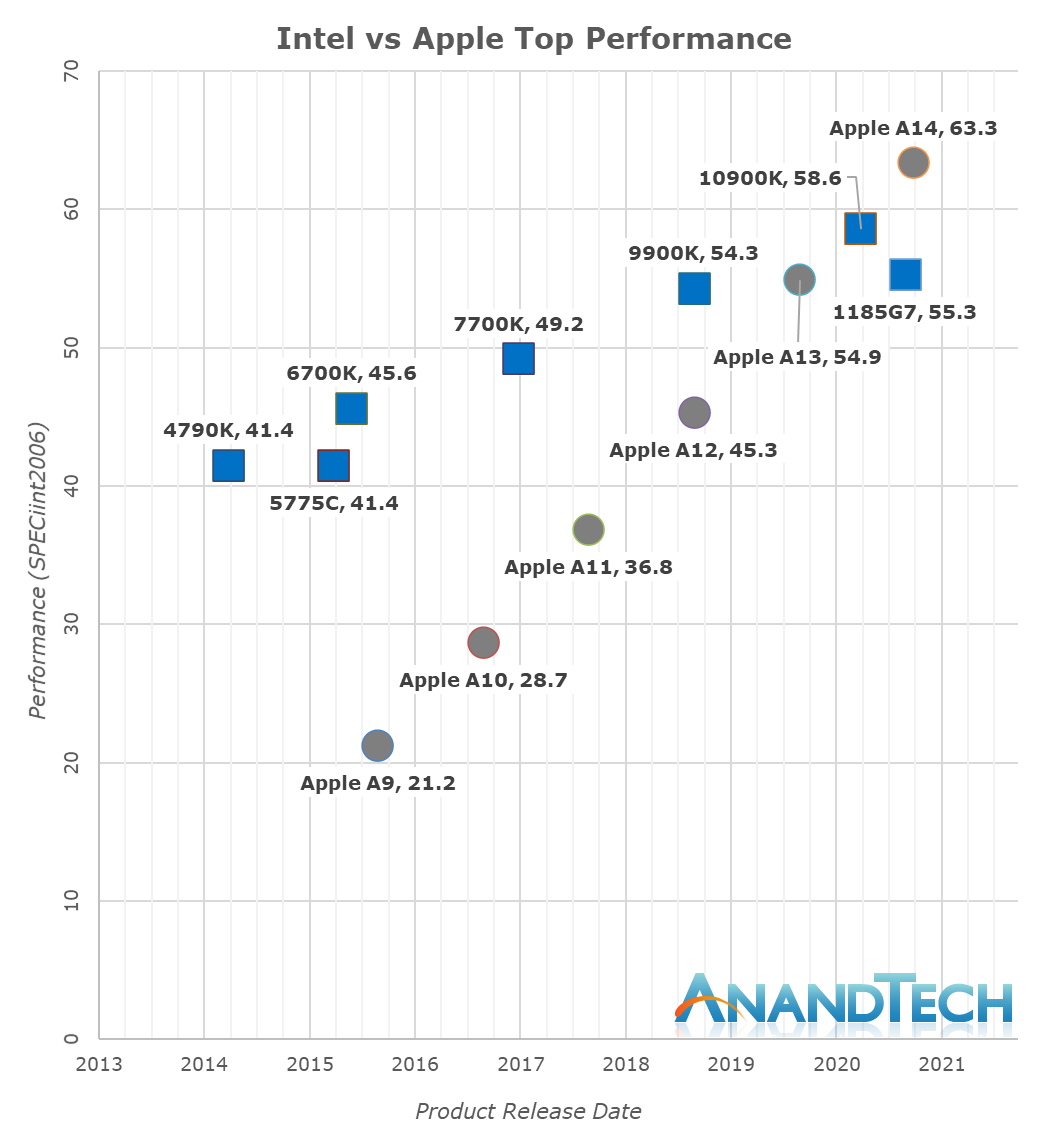
Whilst in the past 5 years Intel has managed to increase their best single-thread performance by about 28%, Apple has managed to improve their designs by 198%, or 2.98x (let’s call it 3x) the performance of the Apple A9 of late 2015.
Apple’s performance trajectory and unquestioned execution over these years is what has made Apple Silicon a reality today. Anybody looking at the absurdness of that graph will realise that there simply was no other choice but for Apple to ditch Intel and x86 in favour of their own in-house microarchitecture – staying par for the course would have meant stagnation and worse consumer products.
Today’s announcements only covered Apple’s laptop-class Apple Silicon, whilst we don’t know the details at time of writing as to what Apple will be presenting, Apple’s enormous power efficiency advantage means that the new chip will be able to offer either vastly increased battery life, and/or, vastly increased performance, compared to the current Intel MacBook line-up.
Apple has claimed that they will completely transition their whole consumer line-up to Apple Silicon within two years, which is an indicator that we’ll be seeing a high-TDP many-core design to power a future Mac Pro. If the company is able to continue on their current performance trajectory, it will look extremely impressive.








644 Comments
View All Comments
Just_Looking - Sunday, November 15, 2020 - link
What happened to "There is no denying that SPEC CPU2006 was never one of our favorite benchmarks in the Professional IT section of AnandTech."hlovatt - Sunday, November 15, 2020 - link
Looks like M1 is very fast even using Rosetta to translate x86 code:https://www.macrumors.com/2020/11/15/m1-chip-emula...
Appears to take a 30% hit, but that still makes it very fast.
realbabilu - Monday, November 16, 2020 - link
Auckland got it first.Benchmark cinebench 23 Multi 7566
https://mobile.twitter.com/mnloona48_/status/13284...
Joe Guide - Monday, November 16, 2020 - link
Wow. Single score is quite impressive as well for a no fan low end chip.GeoffreyA - Tuesday, November 17, 2020 - link
Impressive, yes, but still behind Tiger Lake (1165G7).hlovatt - Monday, November 16, 2020 - link
Looks like the GPU is good too:https://forums.macrumors.com/threads/m1-chip-beats...
magfal - Tuesday, November 17, 2020 - link
The SLC cache on the die shot scares me a bit. Is that NAND in the CPU?Could it be a potential endurance issue where the chip dies in some years?
Oxford Guy - Sunday, December 6, 2020 - link
NAND in a CPU is a great idea. Forensics will celebrate.Makste - Wednesday, November 18, 2020 - link
I never was interested in apple devices, but now things r getting interesting with this M1 chip. It's just the same way no one was expecting the coming covid-19 and then suddenly everybody turned their attention to it to try and find a cure 🤭wrbst - Wednesday, November 18, 2020 - link
@Andrei Frumusanu, when we will see comparison between Microsoft SQ2 vs Apple M1 ?