Apple Announces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14
by Andrei Frumusanu on November 10, 2020 3:00 PM EST- Posted in
- Apple
- Apple A14
- Apple Silicon
- Apple M1
Apple Shooting for the Stars: x86 Incumbents Beware
The previous pages were written ahead of Apple officially announcing the new M1 chip. We already saw the A14 performing outstandingly and outperforming the best that Intel has to offer. The new M1 should perform notably above that.
We come back to a few of Apple’s slides during the presentations as to what to expect in terms of performance and efficiency. Particularly the performance/power curves are the most detail that Apple is sharing at this moment in time:
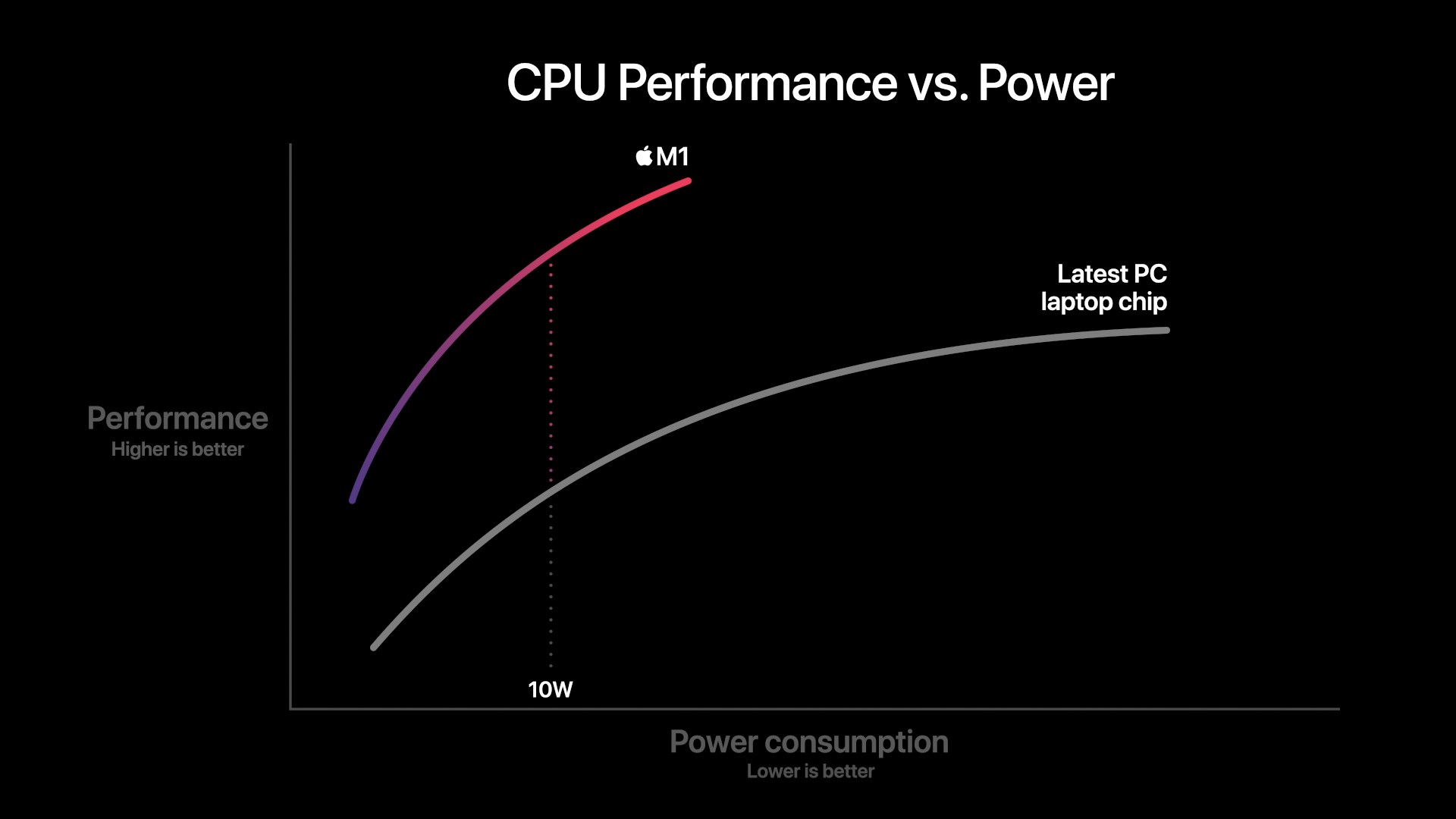
In this graphic, Apple showcases the new M1 chip featuring a CPU power consumption peak of around 18W. The competing PC laptop chip here is peaking at the 35-40W range so certainly these are not single-threaded performance figures, but rather whole-chip multi-threaded performance. We don’t know if this is comparing M1 to an AMD Renoir chip or an Intel ICL or TGL chip, but in both cases the same general verdict applies:
Apple’s usage of a significantly more advanced microarchitecture that offers significant IPC, enabling high performance at low core clocks, allows for significant power efficiency gains versus the incumbent x86 players. The graphic shows that at peak-to-peak, M1 offers around a 40% performance uplift compared to the existing competitive offering, all whilst doing it at 40% of the power consumption.
Apple’s comparison of random performance points is to be criticised, however the 10W measurement point where Apple claims 2.5x the performance does make some sense, as this is the nominal TDP of the chips used in the Intel-based MacBook Air. Again, it’s thanks to the power efficiency characteristics that Apple has been able to achieve in the mobile space that the M1 is promised to showcase such large gains – it certainly matches our A14 data.
Don't forget about the GPU
Today we mostly covered the CPU side of things as that’s where the unprecedented industry shift is happening. However, we shouldn’t forget about the GPU, as the new M1 represents Apple’s first-time introduction of their custom designs into the Mac space.
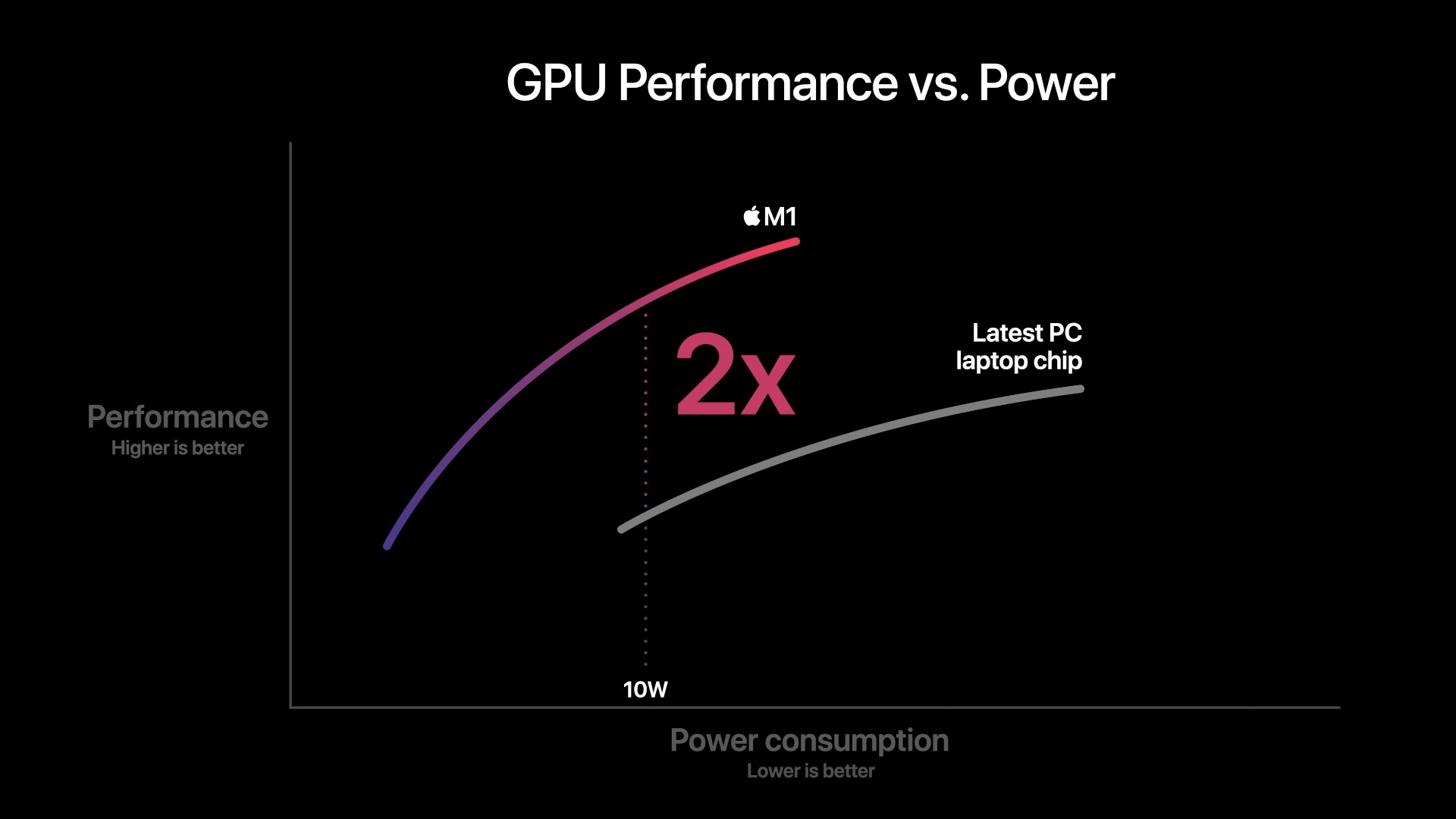
Apple’s performance and power efficiency claims here are really lacking context as we have no idea what their comparison point is. I won’t try to theorise here as there’s just too many variables at play, and we don’t know enough details.
What we do know is that in the mobile space, Apple is absolutely leading the pack in terms of performance and power efficiency. The last time we tested the A12Z the design was more than able to compete and beat integrated graphics designs. But since then we’ve seen more significant jumps from both AMD and Intel.
Performance Leadership?
Apple claims the M1 to be the fastest CPU in the world. Given our data on the A14, beating all of Intel’s designs, and just falling short of AMD’s newest Zen3 chips – a higher clocked Firestorm above 3GHz, the 50% larger L2 cache, and an unleashed TDP, we can certainly believe Apple and the M1 to be able to achieve that claim.
This moment has been brewing for years now, and the new Apple Silicon is both shocking, but also very much expected. In the coming weeks we’ll be trying to get our hands on the new hardware and verify Apple’s claims.
Intel has stagnated itself out of the market, and has lost a major customer today. AMD has shown lots of progress lately, however it’ll be incredibly hard to catch up to Apple’s power efficiency. If Apple’s performance trajectory continues at this pace, the x86 performance crown might never be regained.








644 Comments
View All Comments
mdriftmeyer - Thursday, November 12, 2020 - link
Logic Pro Xvais - Thursday, November 12, 2020 - link
Great article until it reached the benchmark against x86 part.I am amazed how something can claim to be a benchmark and yet leave out what is being measured, what are the criteria, are the results adjusted for power, etc.
Here are some quotes from the article and why they seem to be a biased towards Apple, bordering on fanboyism:
"x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4) that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions"
And who ever said wider is always better, especially in two different instruction sets? Comparing apples to melons here...
"On the ARM side of things, Samsung’s designs had been 6-wide from the M3 onwards, whilst Arm’s own Cortex cores had been steadily going wider with each generation, currently 4-wide in currently available silicon"
Based on that alone would you conclude Exynos is some miracle of CPU design and it somehow comes anywhere close to the performance of a full blown desktop enthusiast grade CPU? Sure hope not.
"outstanding lode/store:
To not surprise, this is also again deeper than any other microarchitecture on the market. Interesting comparisons are AMD’s Zen3 at 44/64 loads & stores, and Intel’s Sunny Cove at 128/72. "
Again comparing different things and drawing conclusions like it's a linear scale. AMD's load/stores are significantly less than Intel's and yes AMD Zen3 CPUs outperform Intel counterparts across the board. I'd say biased as hell...
"AMD also wouldn’t be looking good if not for the recently released Zen3 design."
So comparing yet unreleased core to the latest already available from the competition and somehow the competition is in a bad place as "only" it's latest product is better? Come on...
"The fact that Apple is able to achieve this in a total device power consumption of 5W including the SoC, DRAM, and regulators, versus +21W (1185G7) and 49W (5950X) package power figures, without DRAM or regulation, is absolutely mind-blowing."
I am really interested where those power package figures come from, specifically for the 5950X. AMD's site lists it as 105W TDP. How were the 49W measured?
I've read other articles from Andrei which have been technical, detailed and specific marvels, but this one misses the mark by a long shot in the benchmarks and conclusion parts.
Bluetooth - Thursday, November 12, 2020 - link
They don’t have an actual M1 to test as they say in the artcle. The M1 will be available on the 24th.GeoffreyA - Thursday, November 12, 2020 - link
I think it would be instructive to remember the Pentium 4, which had a lot of "fast" terms for its time: hyper-pipelined this, double pumped ALUs, quad pumped that; but we all know the result. The proof of the pudding is in the eating, or in the field of CPUs, performance, power, and silicon area.AMD and Intel have settled down to 4- and 5-wide decode as the best trade-offs for their designs. They could make it 8-wide tomorrow, but it's likely no use, and would cause disaster from a power point of view.* If Apple wishes to go for wide, good for them, but the CPU will be judged not on "I've got this and that," but on what its final merits.
Personally, I think it's better engineering to produce a good result with fewer ingredients. Compare Z3's somewhat conservative out-of-order structures to Sunny Cove's, but beating it.
When the M1 is on an equal benchmark field with 5 nm x86, then we'll see whether it's got the goods or not.
* Decoding takes up a lot of power in x86, that's why the micro-op cache is so effective (removing fetch and pre/decode). In x86, decoding can't be done in parallel, owing to the varying instruction lengths: one has to determine first how long one instruction is before knowing where the next one starts, whereas in fixed-length ISAs, like ARM, it can be done in parallel: length being fixed, we know where each instruction starts.
Joe Guide - Thursday, November 12, 2020 - link
The benchmarks are coming out, and it looks like the pudding is quite tasty. But you have a good point. When in 2025 or 2026 Intel or AMD releases their newest 5 nm x86, you will be proven to be prophetic that the new Intel chip resoundingly beats the base M1 chip from 5 years ago.GeoffreyA - Thursday, November 12, 2020 - link
That line about the M1 and 5 nm is silly on my part, I'll admit. Sometimes we write things and regret it later. Also, if you look at my comment from the other day, you'll see the first thing I did was acknowledge Apple's impressive work on this CPU. The part about the Pentium 4 and the pudding wasn't in response to the A14's performance, but this whole debate running through the comments about wide vs. narrow, and so I meant, "Wide, narrow, doesn't mean anything. What matters is the final performance."I think what I've been trying to say, quite feebly, through the comments is: "Yes, the A14 has excellent performance/watt, and am shocked how 5W can go up against 105W Ryzen. But, fanboy comment it may be, I'm confident AMD and Intel (or AMD at any rate) can improve their stuff and beat Apple."
Joe Guide - Thursday, November 12, 2020 - link
I see this as glass half full. There was been far too much complacency in the CPU development over the last decade. If it take Apple to kick the industry in the butt, well then, how is that bad.Moore's Law has awoke after a deep slumber and it is hungry and angry. Run Intel. Run for your life.
GeoffreyA - Friday, November 13, 2020 - link
Agreed, when AMD was struggling, Intel's improvements were quite meagre (Sandy Bridge excepted). Much credit must be given to AMD though. Their execution of the past few years has been brilliant.chlamchowder - Friday, November 13, 2020 - link
In x86, decoding is very much done in parallel. That's how you get 3/4/5-wide decoders. The brute force method is to tentatively start decoding at every byte. Alternatively, you mark instruction boundaries in the instruction cache (Goldmont/Tremont do this, as well as older AMD CPUs like Phenom).GeoffreyA - Saturday, November 14, 2020 - link
Thanks for that. I'm only a layman in all this, so I don't know the exact details. I did suspect there was some sort of trick going on to decode more than one at a time. Marking instructions boundaries in the cache is quite interesting because it ought to tone down, or even eliminate, x86's variable length troubles. Didn't know about Tremont and Goldmont, but I was reading that the Pentium MMX, as well as K8 to Bulldozer, perhaps K7 too, used this trick.My question is, do you think AMD and Intel could re-introduce it (while keeping the micro-op cache as well)? Is it effective or does it take too much effort itself? I ask because if it's worth it, it could help x86's length problem quite a bit, and that's something which excites me, under this current climate of ARM. However, judging from the results, it didn't aid the Athlon, Phenom, and Bulldozer that drastically, and AMD abandoned it in Zen, going for a micro-op cache instead, so that knocks down my hopes a bit.