The Intel Xe-LP GPU Architecture Deep Dive: Building Up The Next Generation
by Ryan Smith on August 13, 2020 9:00 AM EST- Posted in
- GPUs
- Intel
- Tiger Lake
- Xe
- Xe-LP
- DG1
- Intel Arch Day 2020
- SG1
Feed the Beast: New L1 Cache & Dual Ring Buses
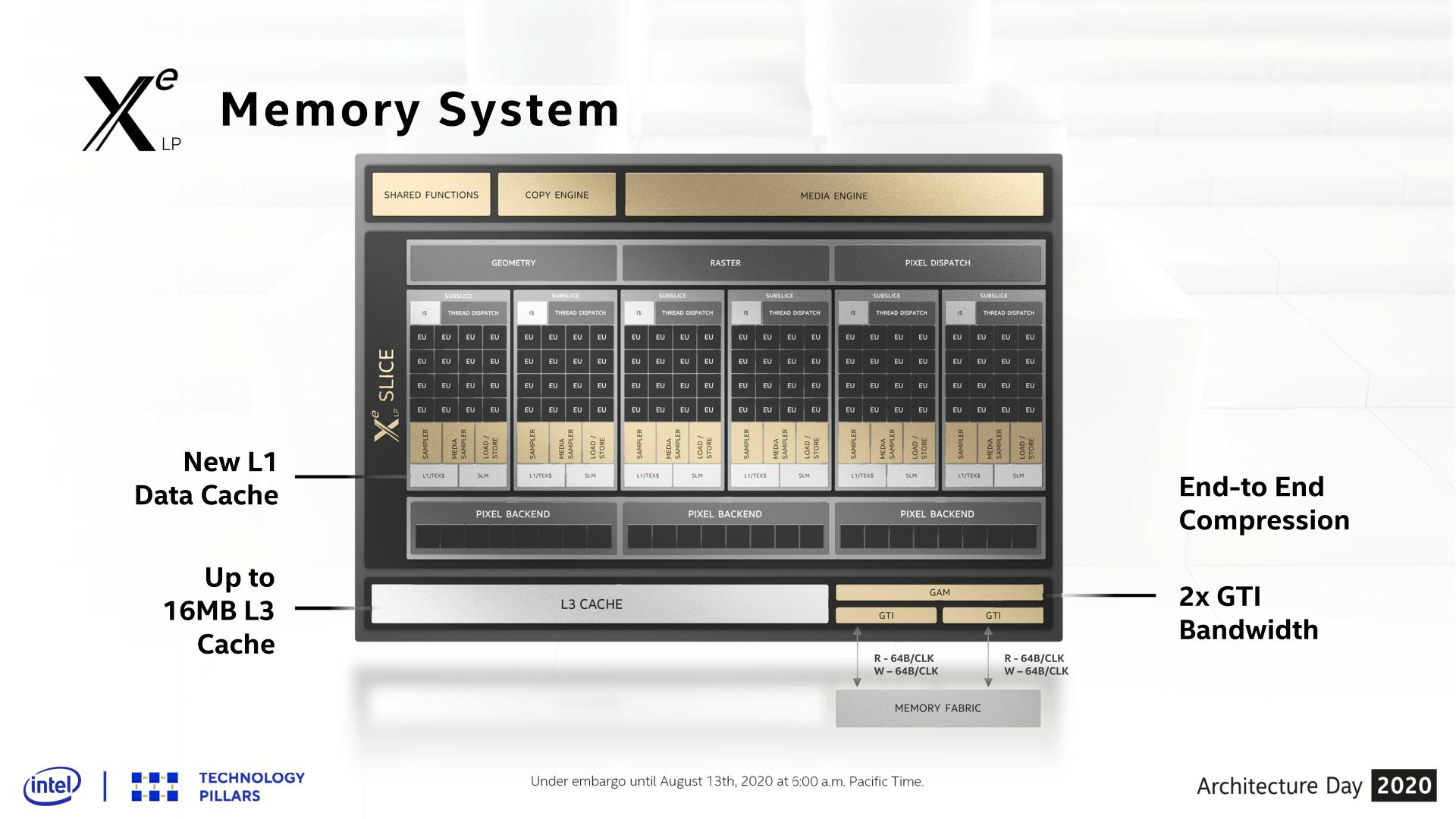
Shifting gears, let’s take a look at the memory subsystem for Xe-LP and how Intel will be feeding the beast that is their new GPU architecture. Among many contemporary firsts for Intel’s GPU architectures, Xe-LP will find itself in the interesting position of straddling the line between an integrated GPU and a discrete GPU. Which is to say that it has to be able to work with both Tiger Lake’s shared IMC, as well as DG1’s own dedicated memory controller.
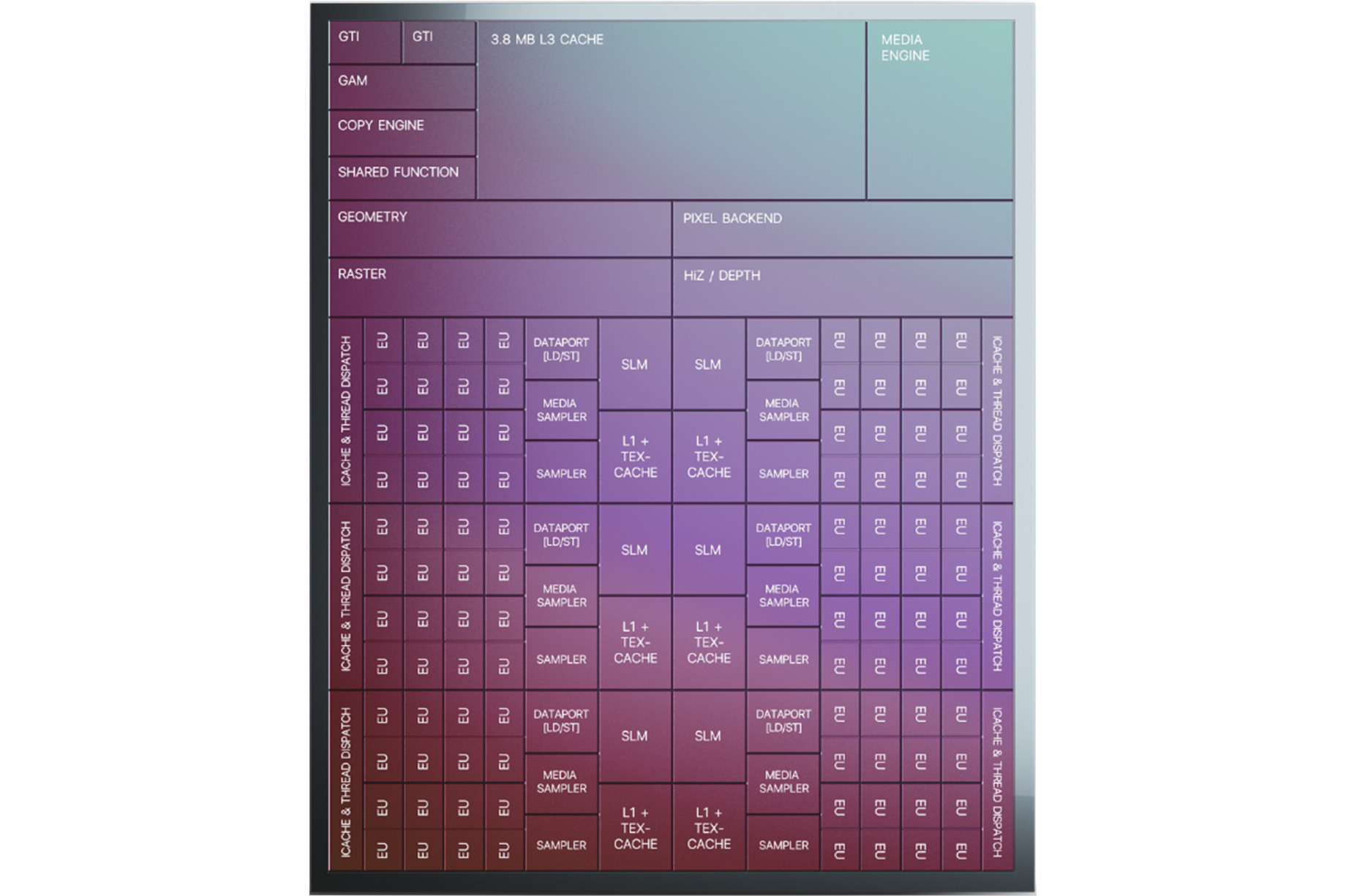
Starting with the subslices, Xe-LP introduces a new combined L1 data and texture cache. Information about this cache is limited, but Intel has confirmed that it’s a 64KB per subslice cache, and that it can be dynamically reconfigured between L1 and texture caching as necessary. According to the company, they added the L1 cache as a result of their workload analysis, and that doing so improved the performance of the load/store pipeline. Unfortunately, it’s not clear how this fits into the bigger picture with Intel’s previous subslice L2 cache, and whether that’s been replaced or still exists and is merely not on these diagrams.

The on-GPU L3 cache (not to be confused with Tiger Lake’s shared Last Level Cache) has also undergone its own upgrades, receiving both a capacity and a bandwidth boost. On the capacity front, the L3 cache can now be as large as 16MB, as opposed to just 3MB on Gen11. That said, based on Intel’s Tiger Lake disclosures, it’s clear that such a large cache isn’t coming to Intel’s SoCs; instead Tiger Lake will ship with a 3.8MB GPU L3 cache. Tiger Lake has its own LLC beyond this, which the GPU can tap into as well, so it doesn’t necessarily need quite such a large cache.
For DG1, on the other hand, the GPU’s L3 cache is the last caching level, so a larger cache makes practical sense there. To that end I wouldn’t be surprised if that’s exactly what we see on DG1: a 16MB L3 cache. Though Intel has reiterated that this is an architectural presentation and not a product presentation, so it may very well be that they aren’t outfitting any Xe-LP GPUs with a max size L3 cache.
This larger L3 cache is also faster than Gen11’s L3, with Intel doubling the transfer size. Xe-LP’s L3 cache can now transfer 128 bytes/clock, which for a theoretical 1.6GHz chip would give it over 190GB/sec of internal L3 bandwidth. This upgrade is important for feeding the ROPs and other parts of the GPU, and goes hand-in-hand with Intel’s goal to double GPU performance, which means they need to feed the beast a lot more data in the process. Plus this change also keeps the L3 cache aligned with what the new dual ringbus can do.
One of the more enigmatic changes for Tiger Lake, the SoC has added a second, seemingly identical ringbus to the chip, creating a second loop that connects the four CPU cores and the iGPU to the integrated memory controller. As a consequence of this, the iGPU now needs two Graphics Technology Interface (GTI) ports to create the two ringbus stops.
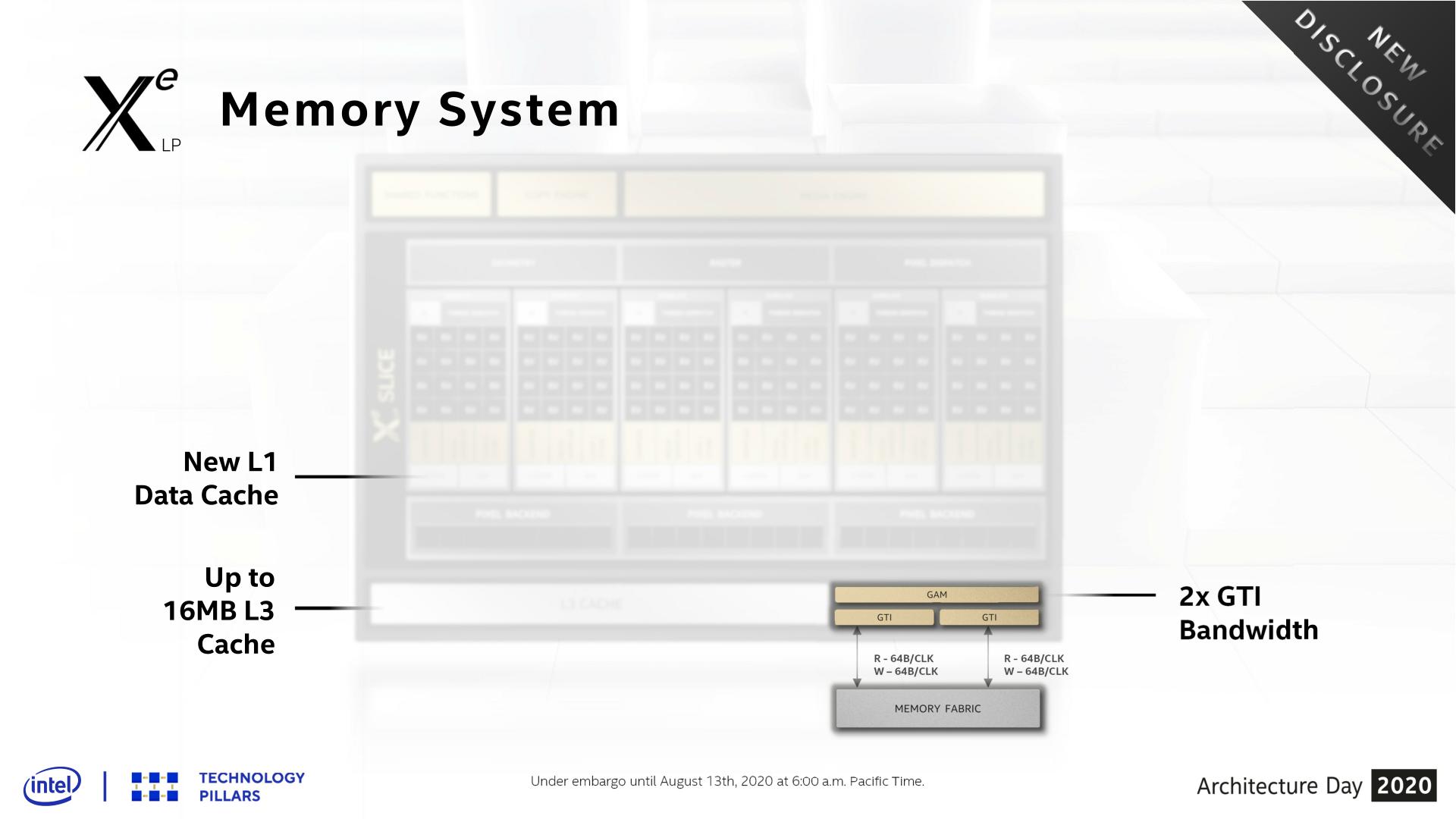
The big benefit of this change is that, all other aspects held equal, this doubles the amount of bandwidth between the GPU and the IMC on Tiger Lake. So instead of only being able to transfer 64B/clock up and down, Xe-LP on Tiger Lake can send two 64B requests (for a total of 128B/clock) using the two ringbuses.
Given that at this juncture the iGPU has become the largest consumer of bandwidth on an Intel SoC, I strongly suspect that the second ringbus has been added primarily for the iGPU’s benefit. Unfortunately this isn’t something we can directly math out, as the ringbus having its own clock domain complicates matters a bit, so it’s not clear if 1 ringbus can even match the memory bandwidth of a Tiger Lake chip with LPDDR5-5200. But even if it can, the an even higher performing GPU like Xe-LP is no doubt putting a good deal of pressure on Intel’s SoC memory subsystem.
Meanwhile this also gives us a very strong hint that DG1 will utilize a 128-bit memory bus for its dedicated VRAM. The 2x64B backend could very easily be hooked up to a 128-bit memory controller, instead of the two 64B ringbuses. This would also ensure that DG1 gets as much or more memory bandwidth than Tiger Lake – and with the bonus of not having to share it with other parts of the system.
Finally, even with the significant bandwidth improvements underneath, Intel has also been working to reduce their bandwidth consumption. Xe-LP ships with updated versions of their color and depth compression algorithms, which although Intel isn’t providing specific figures for it, any improvements here will directly translate into reduced memory traffic. Meanwhile the company is also extending this compression functionality to the media and display interfaces, which means that image data can stay compressed whenever it’s being moved between the graphics engine, the media engine, and the display.








33 Comments
View All Comments
regsEx - Thursday, August 13, 2020 - link
HPG will use EM cores for ray tracing?Mr Perfect - Thursday, August 13, 2020 - link
"On the capacity front, the L3 cache can now be as large as 16MB"I apologize for being off topic, but I just had a surreal moment realizing that this piddly little iGPU can have the same amount of L3 cache as my Voodoo 3 had video ram. How far we've come.
Brane2 - Thursday, August 13, 2020 - link
As usual, no useful info.They'll make a GPU that looks every bit like... GPU.
What a shocker.
Who knew ?
GreenReaper - Thursday, August 13, 2020 - link
"As a result, integer throughput has also doubled: Xe-LP can put away 8 INT32 ops or 32 INT16 ops per clock cycle, up from 4 and 16 respectively on Gen11." -- but the graph says 4 and 8 respectively on Gen11. (The following line also appears odd as a result.)Ryan Smith - Thursday, August 13, 2020 - link
Thanks! That was meant to be 16 ops for Gen11 in the table.neogodless - Thursday, August 13, 2020 - link
> from reviews of Ice Lake and Ryzen 3000 “Renoir” laptops,It is my understanding that the Renoir codename refers to what are commercially Ryzen 4000 mobile APUs, like the 4700U, 4800H and 4900HS.
FullmetalTitan - Thursday, August 13, 2020 - link
In addition to groaning at the joke at the end of page 1, I find the timing to be perfect as I just last night got my partner to start watching the Stargate seriesValantar - Friday, August 14, 2020 - link
As always here on AT, an absolutely excellent article, distilling a pile of complex information down to something both understandable and interesting. I'm definitely looking forward to seeing how Tiger Lake's Xe iGPU performs, and the DG1 too. I doubt their drivers will be up to par for a few years, but a third contender should be good for the GPU market (though with a clear incumbent leader there's always a chance of the small fish eating each other rather than taking chunks out of the bigger one). Looking forward to the next few years of GPUs, this is bound to be interesting!onewingedangel - Friday, August 14, 2020 - link
The approach taken with DG1 seems a little odd. It's too similar to the iGPU by itself, just with more power/thermal headroom and less memory contention.Unless it works in concert with the IGP, you'd think it better to either remove the iGPU from the CPU entirely (significantly reducing die size) and package DG1 with the CPU die when a more powerful GPU is not going to be used, or to add a HBM controller to the CPU and make the addition of a HBM die the graphics upgrade option when the Base iGPU is not quite enough.
Digidi - Friday, August 14, 2020 - link
Nice article! The Fron end look huge. 2 Rasterizer for only 700 Shaders is a massive Change.