Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Compiler Setup, GCC vs LLVM
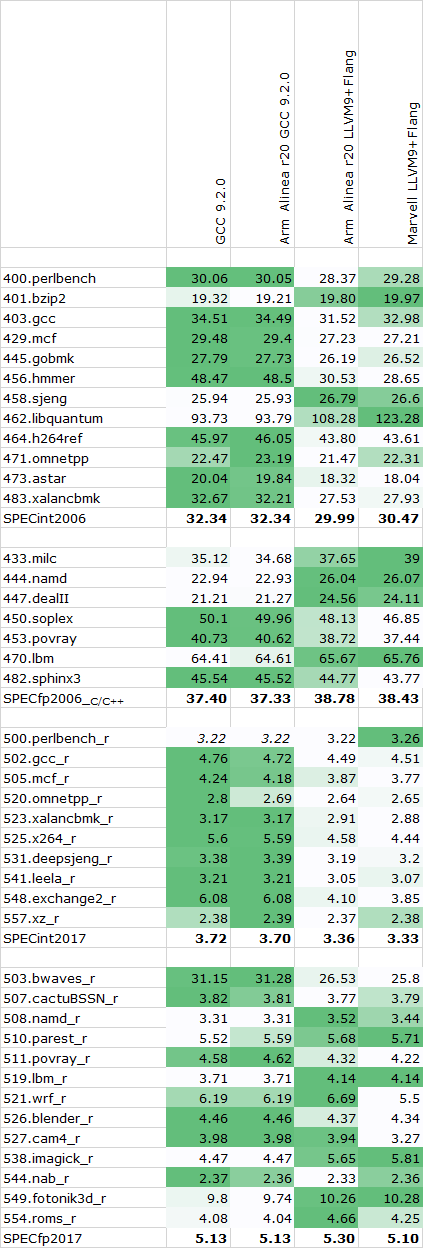
For further performance testing of the systems, we fell back to SPEC2006 and 2017. I wanted to make sure that there’s no heated discussions when it comes to the compilation of the test suites, so carefully investigated the compilers out there, particularly regarding the choice between GCC and LLVM.
Overall, I checked three different compiler setups: A freshly compiled GCC 9.2.0 release, Arm’s Allinea Studio Compiler 20 package which comes with both Arm’s closed source LLVM and Flang variants as well as a pre-compiled version of GCC 9.2.0, and Marvell’s branch of LLVM and Flang.
We had seen quite a push by Arm for us to consider GCC more closely than LLVM, as Arm had admitted that they’ve spent more time upstream optimising GCC than they’ve had for LLVM. Given the much more prevalent use of GCC in cloud and datacentre applications, I did somewhat agree with this given that’s most likely what you’ll see people use in such environments.
I ran some single-threaded tests across the different compiler setups, the compiler flags were straightforward with just a simple -Ofast flag as well as -march/-mcpu=cortex-a76 or =neoverse-n1 (alias) for the Arm compiler setup.
As always, our SPEC results aren't officially submitted results, and thus we have to label them merely as "estimates" for this article. Furthermore, SPEC2006 has been retired in favour of SPEC2017, but I still wanted to put up the figures for historical context, as well as mobile comparisons.
Graviton2 SPEC - Single Threaded - 2.5GHz
The overall results favour GCC in the SPECint workloads, while LLVM seemingly does better in the FP and memory heavy tests. Between the upstream GCC 9.2.0 and Arm’s precompiled version there’s seemingly no performance difference whatsoever, while there is some minor difference between Marvell’s setup and Arm’s branch of LLVM.
I ended up going forward with a clean compile of GCC 9.2.0 both for the Arm as well as x86 systems – meaning we’re using the exact same compiler for both architectures, just with different compile targets.
For x86, we’re again using the simple -Ofast flag for optimisations, and using the corresponding -march/-mtune targets for the EPYC and Intel platforms, meaning zenver1 and skylake-avx512.
Overall, it’s a bit odd to see GCC ahead in that many workloads given that LLVM the is the primary compiler for billions of Arm devices in the mobile space. Arm has said that they’re trying to put more effort into this compiler as seemingly it’s lagging behind GCC in terms of some optimisations.








96 Comments
View All Comments
jbrower - Saturday, July 24, 2021 - link
Well at least you have a troll -- mark of success for authors, heheProDigit - Wednesday, March 11, 2020 - link
110W is very pessimistic, and would make no sense at all, considering that the ryzen 9 3900x uses 105W at 12 cores 24 threads at 4.6Ghz and 7nm, and the 3950 does the same with 4 more cores.Plus, regular arm based (AMLogic) boxes use 3Watt in total under load (that includes CPU+Ethernet+RAM+Emmc) for 4 CPU cores running at 1,9Ghz.
If you ask me, 64 core arm CPUs running at 2Ghz should run at around just over 1 watt per core, making it a 65W tdp chip
Andrei Frumusanu - Wednesday, March 11, 2020 - link
There's 64 PCIe4 lanes and 8 memory controllers in there as well.cdome - Wednesday, March 11, 2020 - link
Quick question. Does Graviton2 have support for SVE2 vector extension? if yes how wide are execution units? thank youAndrei Frumusanu - Wednesday, March 11, 2020 - link
No, there's 2x128b v8 ASIMD/NEON pipes.Soulkeeper - Wednesday, March 11, 2020 - link
What was used to generate the images on page 2 ?ie: https://images.anandtech.com/doci/15578/AMD-Epyc-6...
Is this app/source available to download ?
Thanks
sharath.naik - Wednesday, March 11, 2020 - link
Whats behind the name Annapurna? The name is Indian in origin but the company is Israeli.nijimon - Thursday, March 12, 2020 - link
Judging by the logo it could be referring to the massif in the Himalayas.https://en.wikipedia.org/wiki/Annapurna_Massif
Andy Chow - Thursday, March 12, 2020 - link
"I recently had the time to write a new custom microbenchmark for testing synchronisation latencies of CPU cores, exhibiting some of the cache-coherency as well as physical layouts of current designs."Wow, and what a benchmark that turned out to be. Please consider packaging it and releasing it. Or giving us the code so we can run it. I would really love to run that test on a few of my machines. I am frustrated with current benchmarks on this area also, and you seem to have built the perfect solution.
ballsystemlord - Thursday, March 12, 2020 - link
1 Grammar error:"Overall, it's a bit odd to see GCC ahead in that many workloads given that LLVM the is the primary compiler for billions of Arm devices in the mobile space."
Extra "the":
"Overall, it's a bit odd to see GCC ahead in that many workloads given that LLVM is the primary compiler for billions of Arm devices in the mobile space."