Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Compiler Setup, GCC vs LLVM
For further performance testing of the systems, we fell back to SPEC2006 and 2017. I wanted to make sure that there’s no heated discussions when it comes to the compilation of the test suites, so carefully investigated the compilers out there, particularly regarding the choice between GCC and LLVM.
Overall, I checked three different compiler setups: A freshly compiled GCC 9.2.0 release, Arm’s Allinea Studio Compiler 20 package which comes with both Arm’s closed source LLVM and Flang variants as well as a pre-compiled version of GCC 9.2.0, and Marvell’s branch of LLVM and Flang.
We had seen quite a push by Arm for us to consider GCC more closely than LLVM, as Arm had admitted that they’ve spent more time upstream optimising GCC than they’ve had for LLVM. Given the much more prevalent use of GCC in cloud and datacentre applications, I did somewhat agree with this given that’s most likely what you’ll see people use in such environments.
I ran some single-threaded tests across the different compiler setups, the compiler flags were straightforward with just a simple -Ofast flag as well as -march/-mcpu=cortex-a76 or =neoverse-n1 (alias) for the Arm compiler setup.
As always, our SPEC results aren't officially submitted results, and thus we have to label them merely as "estimates" for this article. Furthermore, SPEC2006 has been retired in favour of SPEC2017, but I still wanted to put up the figures for historical context, as well as mobile comparisons.
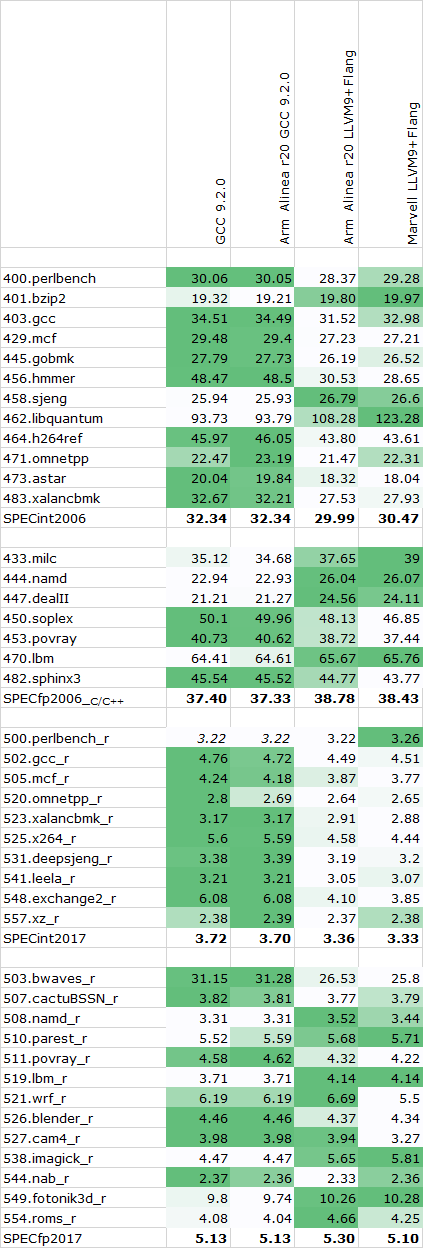
Graviton2 SPEC - Single Threaded - 2.5GHz
The overall results favour GCC in the SPECint workloads, while LLVM seemingly does better in the FP and memory heavy tests. Between the upstream GCC 9.2.0 and Arm’s precompiled version there’s seemingly no performance difference whatsoever, while there is some minor difference between Marvell’s setup and Arm’s branch of LLVM.
I ended up going forward with a clean compile of GCC 9.2.0 both for the Arm as well as x86 systems – meaning we’re using the exact same compiler for both architectures, just with different compile targets.
For x86, we’re again using the simple -Ofast flag for optimisations, and using the corresponding -march/-mtune targets for the EPYC and Intel platforms, meaning zenver1 and skylake-avx512.
Overall, it’s a bit odd to see GCC ahead in that many workloads given that LLVM the is the primary compiler for billions of Arm devices in the mobile space. Arm has said that they’re trying to put more effort into this compiler as seemingly it’s lagging behind GCC in terms of some optimisations.








96 Comments
View All Comments
notladca - Tuesday, March 10, 2020 - link
I would love to know if the product line has split within Annapurna. In other words whether Graviton2 has, like previous Annapurna SoCs, some interesting support around storage and networking for use in future Nitro. It's possible Amazon has some behind the scenes work going on with CCIX for future machines. For example integrating their Inferentia chip more closely with the SoC.Given the core count, it'd also be interesting to compare ML inference acceleration via fp16 and int8 dot product instructions per core vs use of GPU or Inferentia.
coder543 - Tuesday, March 10, 2020 - link
One small bit of feedback: with that CPU topology chart, the coloration seems a little off. A difference of +/- 1 yields very different shades of red and orange, but the same difference on the green side of the spectrum yields no discernible difference in color? Personally, I think all of the 200 +/- 5 values in the first topology chart should be an almost uniform sea of orange/red. The important thing is the 150 difference in latency, not the +/- 1 latency, and the noise in the colors distracts the reader from the primary distinction. A lower signal to noise ratio.Also: what is the unit? nanoseconds? microseconds? milliseconds? I can’t figure it out, and it’s not labeled as far as I can tell.
Andrei Frumusanu - Tuesday, March 10, 2020 - link
Nanoseconds, I'll add a remark.sing_electric - Tuesday, March 10, 2020 - link
My tin hat is telling me to be suspicious of Amazon's pricing here. When shopping for cloud computing, perf/$ becomes VERY alluring, but I have to wonder if Amazon is willing to let its Gravitron servers be a "loss leader," artificially lowering prices to get market share until Arm on server is well-established - before then raising prices to something closer to a economically sustainable number.Andrei Frumusanu - Tuesday, March 10, 2020 - link
Vertical integration is powerful. Amazon can share profits and margins division wide, not having to pay overhead to AMD/Intel.sing_electric - Tuesday, March 10, 2020 - link
True, but then Amazon has to pay for the ARM license and 100% of the development/production costs. I would be very surprised if they managed to *make money* on the 1st couple Graviton generations (especially if you factor in having to buy Annapurna), since you'd need to say "of the $X generated by Graviton metal, $Y would have been spent on EC2 anyways, meaning $Z is our actual gain," and that's... probably too much to ask at this stage.rahvin - Tuesday, March 10, 2020 - link
The costs you mention are nothing compared to what they pay right now with Intel or AMD with they 50% margins on top of the actual cost. IMO this initiative was born out of Intel's price increases from 2010 to now. By vertically integrating they have full control over the price structure and they have very good data on what kind of workloads are running so they can tailor the design.IMO it was just a question of time until Amazon tried to vertically integrate this like they've done with shipping and lots of other stuff. Bezos is following the Robber Barron growth model.
dotjaz - Wednesday, March 11, 2020 - link
Huh? AMD has a gross margin of 40%, true. But keep in mind AWS has a operating margin of 30%, that mean AWS has a even higher gross margin than AMD, comparable to AMD's server department.Do you know what that means? For $1 of expenditure in to chip manufacturing, AWS expects to earn as much as AMD does. And since AWS don't have the volume as far as chip goes, their gross margin for chip investment will be lower, therefore not worth the investment if the decision is purely financial.
But yes, the other point stands, AWS have better control of costing (with more leverage as well) and performance.
Wilco1 - Wednesday, March 11, 2020 - link
For every $1 worth of silicon you could pay AMD $1.50, pay Intel $2 or pay TSMC $1 plus $0.20 internal development costs. Which works out best you think?extide - Friday, March 13, 2020 - link
It's not that simple. AMD and Intel can spread those development costs over vastly more processors. I mean we'll never know how it truly breaks down -- but I'd imagine Amazon has figure this all out and this will be pretty profitable for them.