Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Compiler Setup, GCC vs LLVM
For further performance testing of the systems, we fell back to SPEC2006 and 2017. I wanted to make sure that there’s no heated discussions when it comes to the compilation of the test suites, so carefully investigated the compilers out there, particularly regarding the choice between GCC and LLVM.
Overall, I checked three different compiler setups: A freshly compiled GCC 9.2.0 release, Arm’s Allinea Studio Compiler 20 package which comes with both Arm’s closed source LLVM and Flang variants as well as a pre-compiled version of GCC 9.2.0, and Marvell’s branch of LLVM and Flang.
We had seen quite a push by Arm for us to consider GCC more closely than LLVM, as Arm had admitted that they’ve spent more time upstream optimising GCC than they’ve had for LLVM. Given the much more prevalent use of GCC in cloud and datacentre applications, I did somewhat agree with this given that’s most likely what you’ll see people use in such environments.
I ran some single-threaded tests across the different compiler setups, the compiler flags were straightforward with just a simple -Ofast flag as well as -march/-mcpu=cortex-a76 or =neoverse-n1 (alias) for the Arm compiler setup.
As always, our SPEC results aren't officially submitted results, and thus we have to label them merely as "estimates" for this article. Furthermore, SPEC2006 has been retired in favour of SPEC2017, but I still wanted to put up the figures for historical context, as well as mobile comparisons.
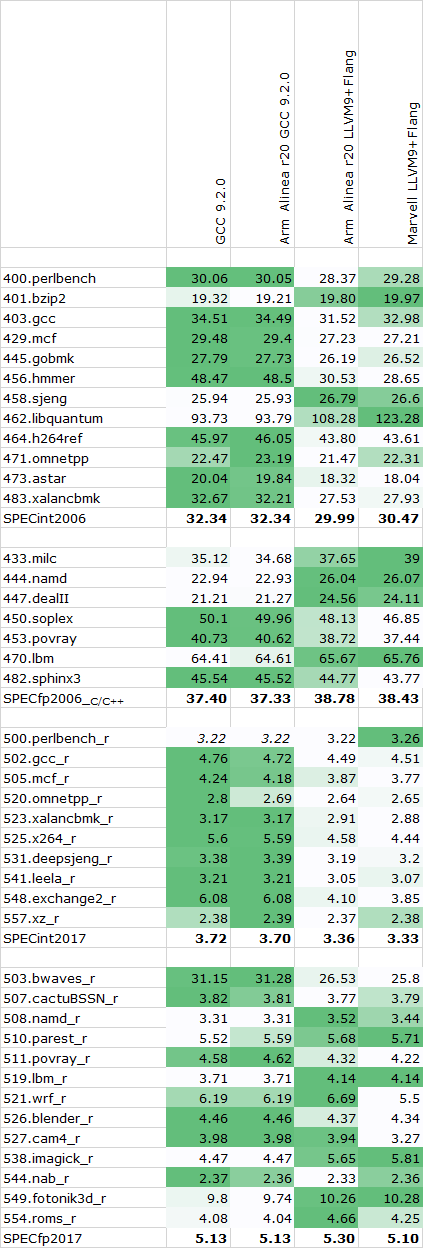
Graviton2 SPEC - Single Threaded - 2.5GHz
The overall results favour GCC in the SPECint workloads, while LLVM seemingly does better in the FP and memory heavy tests. Between the upstream GCC 9.2.0 and Arm’s precompiled version there’s seemingly no performance difference whatsoever, while there is some minor difference between Marvell’s setup and Arm’s branch of LLVM.
I ended up going forward with a clean compile of GCC 9.2.0 both for the Arm as well as x86 systems – meaning we’re using the exact same compiler for both architectures, just with different compile targets.
For x86, we’re again using the simple -Ofast flag for optimisations, and using the corresponding -march/-mtune targets for the EPYC and Intel platforms, meaning zenver1 and skylake-avx512.
Overall, it’s a bit odd to see GCC ahead in that many workloads given that LLVM the is the primary compiler for billions of Arm devices in the mobile space. Arm has said that they’re trying to put more effort into this compiler as seemingly it’s lagging behind GCC in terms of some optimisations.








96 Comments
View All Comments
imaskar - Friday, June 12, 2020 - link
There's a major flaw in the price comparison - why did they take m5n (which has additional network quota) instead of regular m5? It would be $3.07 instead $3.808BlueLikeYou - Tuesday, September 1, 2020 - link
Maybe I'm missing something, but the SPEC numbers seem a little low compared to published results. For example, an Intel Xeon Platinum 8260 scores around 280ish for 48 cores on SPEC INT RATE 2017. This chip is pretty similar to an 8259CL, except that the 8259CL has a slightly higher frequency at 2.5 GHz vs 2.4 GHz for the 8260.The m5n.16xlarge has 32 cores. (32/48) * 280 = 187.67. Your result was 157.36; about 83% of my guess. Granted, performance will probably not scale exactly linearly and there may be a little virtualization overhead, but that drop still seems a little steep.
sgovindan - Friday, June 25, 2021 - link
Hi Andrei,I'm trying to replicate your PMBW bandwidth numbers on the AWS with a C6G instance, but I seem to be getting lower BW estimates - ~170 GB/s for the scalar reads (64-bit) and ~160 GB/s for scalar writes for 64 threads. I've tried both 64GB and 1 GB as the test sizes (the -s and -S parameters of PMBW). Could you confirm the test sizes and/or command-lines used for your results? Thanks.