The Snapdragon 865 Performance Preview: Setting the Stage for Flagship Android 2020
by Andrei Frumusanu on December 16, 2019 7:30 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- 5G
- Cortex A77
- Snapdragon 865
GPU Performance & Power
On the GPU side of things, testing the QRD865 is a bit complicated as we simply didn’t have enough time to run the device through our usual test methodology where we stress both peak as well as sustained performance of the chip. Thus, the results we’re able to present today solely address the peak performance characteristics of the new Adreno 650 GPU.
Disclaimer On Power: As with the CPU results, the GPU power measurements on the QRD865 are not as high confidence as on a commercial device, and the preliminary power and efficiency figures posted below might differ in final devices.
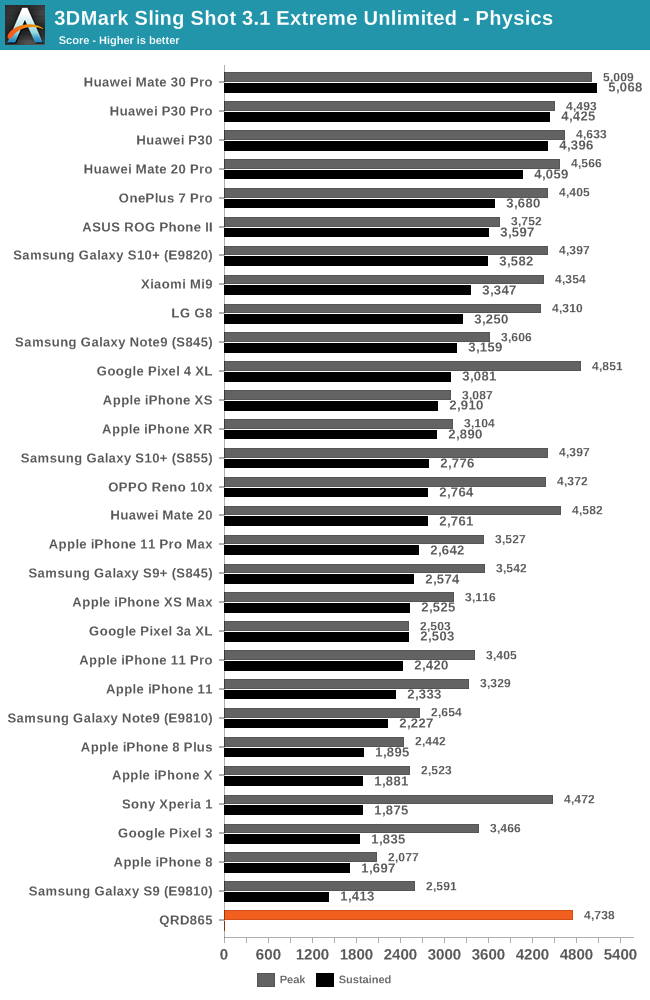
The 3DMark Physics tests is a CPU-bound benchmark within a GPU power constrained scenario. The QRD865 here oddly enough doesn’t showcase major improvements compared to its predecessor, in some cases actually being slightly slower than the Pixel 4 XL and also falling behind the Kirin 990 powered Mate 30 Pro even though the new Snapdragon has a microarchitectural advantage. It seems the A77 does very little in terms of improving the bottlenecks of this test.
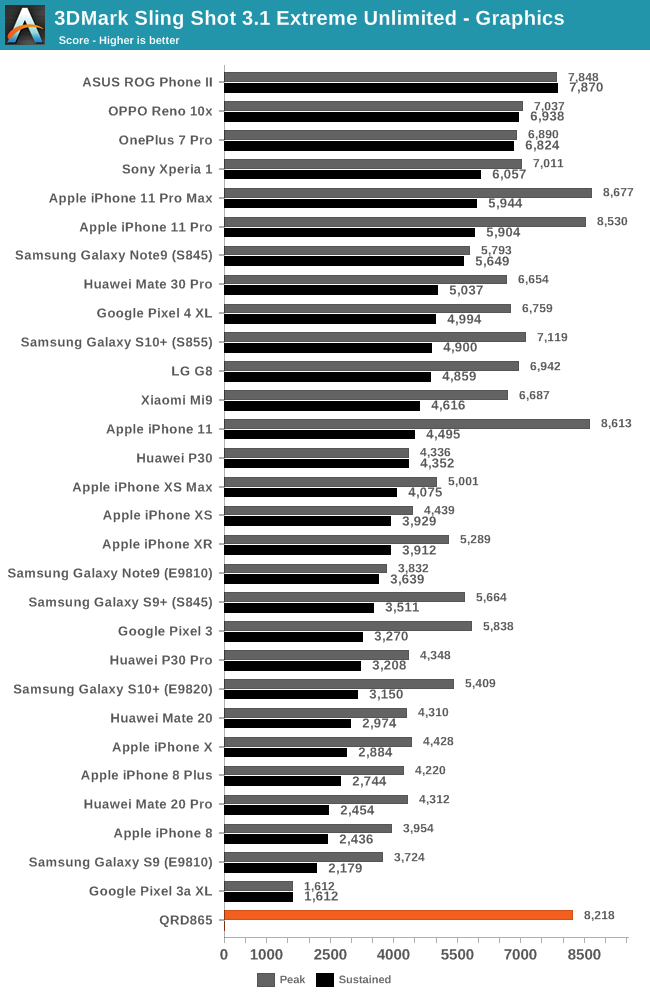
In the 3DMark Graphics test, the QRD865 results are more in line with what we expect of the GPU. Depending on which S855 you compare to, we’re seeing 15-22% improvements in the peak performance.
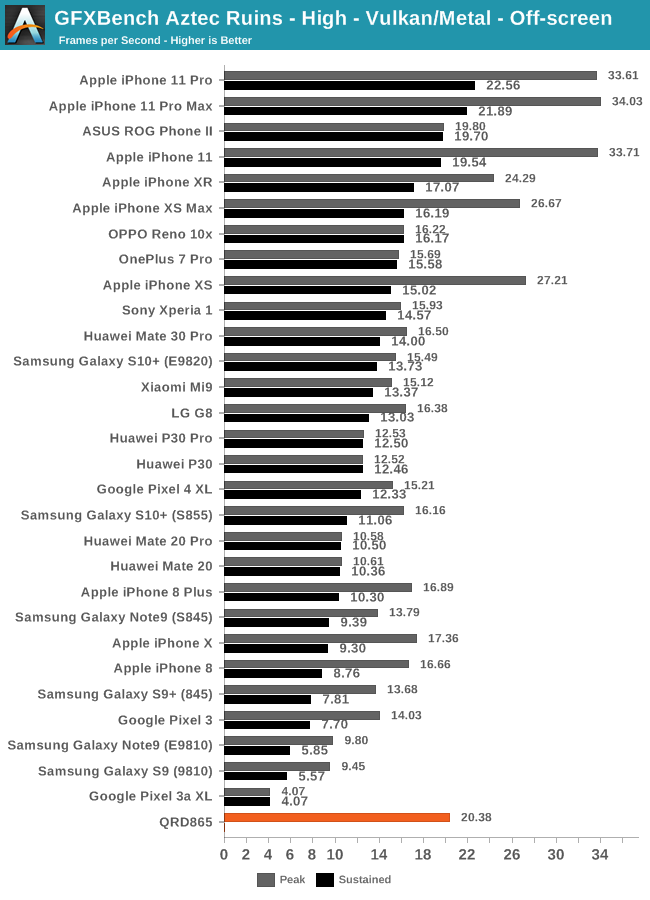
In the GFXBench Aztec High benchmark, the improvement over the Snapdragon 855 is roughly 26%. There’s one apparent issue here when looking at the chart rankings; although there’s an improvement in the peak performance, the end result is that the QRD865 still isn’t able to reach the sustained performance of Apple’s latest A13 phones.
| GFXBench Aztec High Offscreen Power Efficiency (System Active Power) |
||||
| Mfc. Process | FPS | Avg. Power (W) |
Perf/W Efficiency |
|
| iPhone 11 Pro (A13) Warm | N7P | 26.14 | 3.83 | 6.82 fps/W |
| iPhone 11 Pro (A13) Cold / Peak | N7P | 34.00 | 6.21 | 5.47 fps/W |
| iPhone XS (A12) Warm | N7 | 19.32 | 3.81 | 5.07 fps/W |
| iPhone XS (A12) Cold / Peak | N7 | 26.59 | 5.56 | 4.78 fps/W |
| QRD865 (Snapdragon 865) | N7P | 20.38 | 4.58 | 4.44 fps/W |
| Mate 30 Pro (Kirin 990 4G) | N7 | 16.50 | 3.96 | 4.16 fps/W |
| Galaxy 10+ (Snapdragon 855) | N7 | 16.17 | 4.69 | 3.44 fps/W |
| Galaxy 10+ (Exynos 9820) | 8LPP | 15.59 | 4.80 | 3.24 fps/W |
Looking at the estimated power draw of the phone, it indeed does look like Qualcomm has been able to sustain the same power levels as the S855, but the improvements in performance and efficiency here aren’t enough to catch up to either the A12 or A13, with Apple being both ahead in terms of performance, power and efficiency.
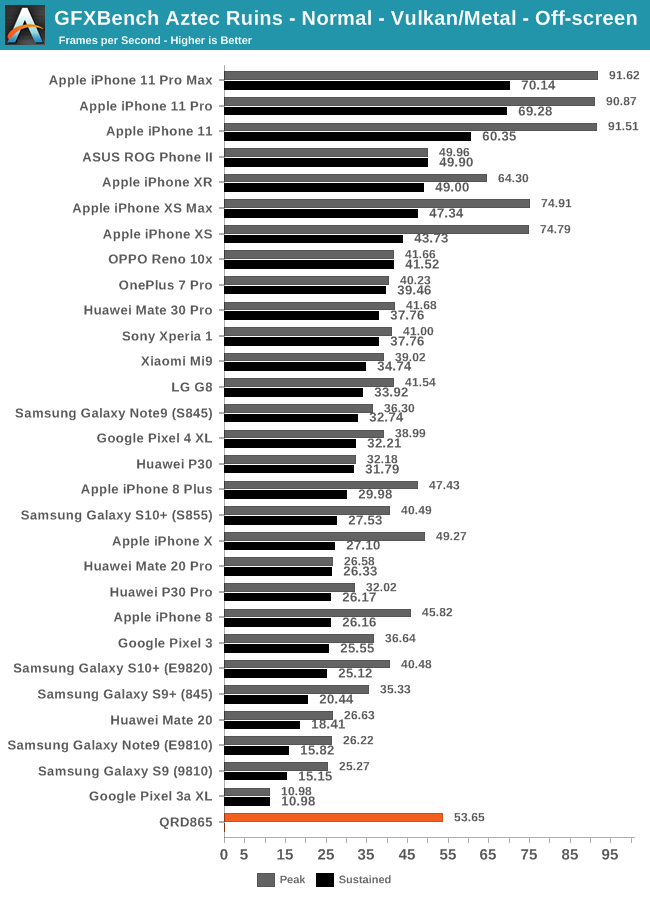
| GFXBench Aztec Normal Offscreen Power Efficiency (System Active Power) |
||||
| Mfc. Process | FPS | Avg. Power (W) |
Perf/W Efficiency |
|
| iPhone 11 Pro (A13) Warm | N7P | 73.27 | 4.07 | 18.00 fps/W |
| iPhone 11 Pro (A13) Cold / Peak | N7P | 91.62 | 6.08 | 15.06 fps/W |
| iPhone XS (A12) Warm | N7 | 55.70 | 3.88 | 14.35 fps/W |
| iPhone XS (A12) Cold / Peak | N7 | 76.00 | 5.59 | 13.59 fps/W |
| QRD865 (Snapdragon 865) | N7P | 53.65 | 4.65 | 11.53 fps/W |
| Mate 30 Pro (Kirin 990 4G) | N7 | 41.68 | 4.01 | 10.39 fps/W |
| Galaxy 10+ (Snapdragon 855) | N7 | 40.63 | 4.14 | 9.81 fps/W |
| Galaxy 10+ (Exynos 9820) | 8LPP | 40.18 | 4.62 | 8.69 fps/W |
We’re seeing a similar scenario in the Normal variant of the Aztec test. Although the performance improvements here do match the promised figures, it’s not enough to catch up to Apple’s two latest SoC generations.
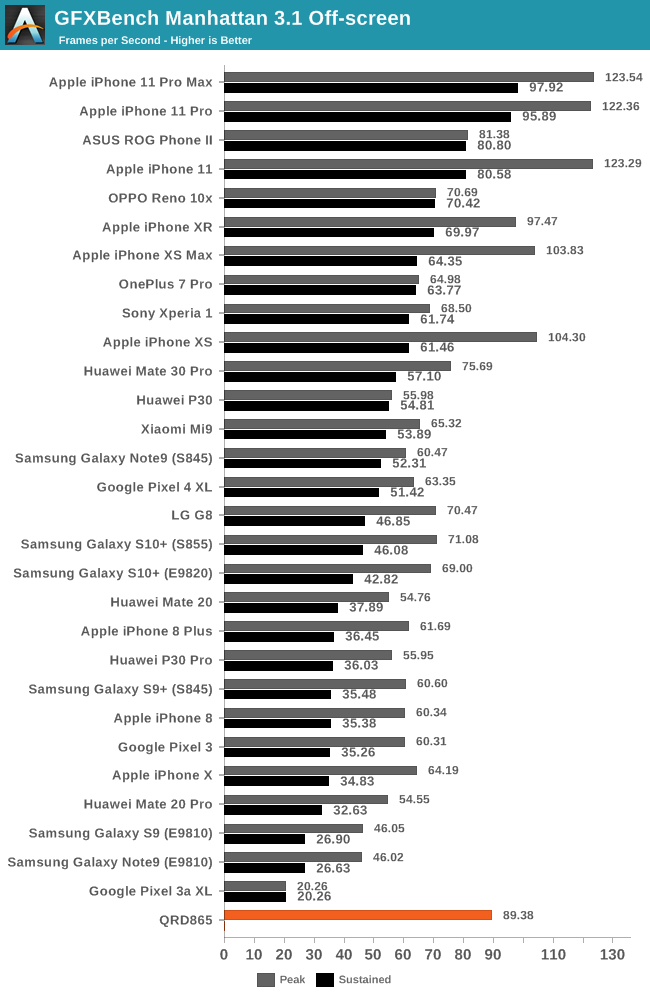
| GFXBench Manhattan 3.1 Offscreen Power Efficiency (System Active Power) |
||||
| Mfc. Process | FPS | Avg. Power (W) |
Perf/W Efficiency |
|
| iPhone 11 Pro (A13) Warm | N7P | 100.58 | 4.21 | 23.89 fps/W |
| iPhone 11 Pro (A13) Cold / Peak | N7P | 123.54 | 6.04 | 20.45 fps/W |
| iPhone XS (A12) Warm | N7 | 76.51 | 3.79 | 20.18 fps/W |
| iPhone XS (A12) Cold / Peak | N7 | 103.83 | 5.98 | 17.36 fps/W |
| QRD865 (Snapdragon 865) | N7P | 89.38 | 5.17 | 17.28 fps/W |
| Mate 30 Pro (Kirin 990 4G) | N7 | 75.69 | 5.04 | 15.01 fps/W |
| Galaxy 10+ (Snapdragon 855) | N7 | 70.67 | 4.88 | 14.46 fps/W |
| Galaxy 10+ (Exynos 9820) | 8LPP | 68.87 | 5.10 | 13.48 fps/W |
| Galaxy S9+ (Snapdragon 845) | 10LPP | 61.16 | 5.01 | 11.99 fps/W |
| Mate 20 Pro (Kirin 980) | N7 | 54.54 | 4.57 | 11.93 fps/W |
| Galaxy S9 (Exynos 9810) | 10LPP | 46.04 | 4.08 | 11.28 fps/W |
| Galaxy S8 (Snapdragon 835) | 10LPE | 38.90 | 3.79 | 10.26 fps/W |
| Galaxy S8 (Exynos 8895) | 10LPE | 42.49 | 7.35 | 5.78 fps/W |
Even on the more traditional tests such as Manhattan 3.1, although again the Adreno 650 is able to showcase good improvements this generation, it seems that Qualcomm didn’t aim quite high enough.
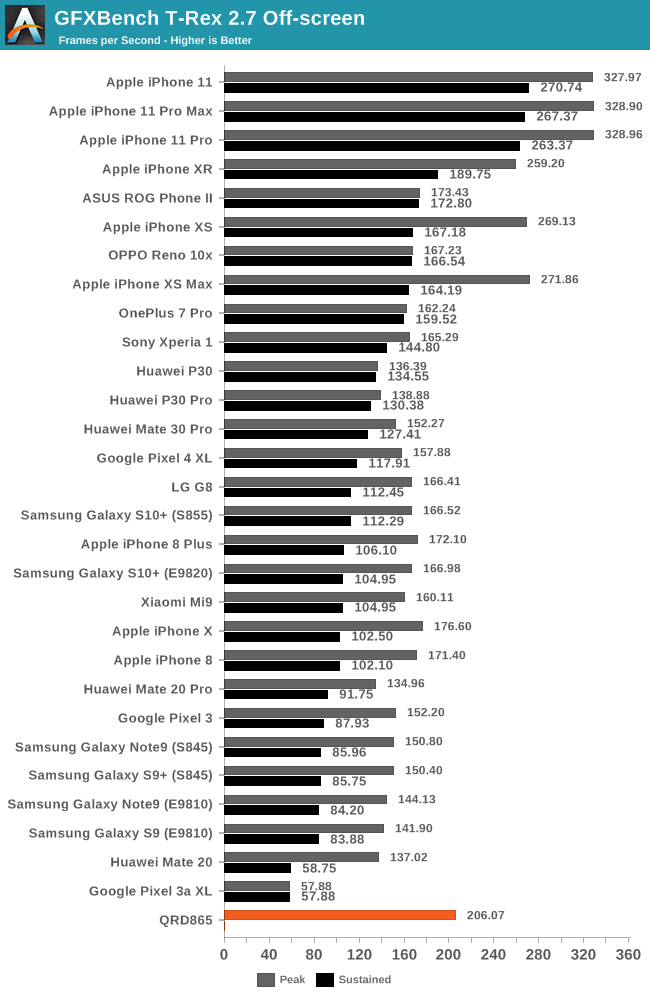
| GFXBench T-Rex Offscreen Power Efficiency (System Active Power) |
||||
| Mfc. Process | FPS | Avg. Power (W) |
Perf/W Efficiency |
|
| iPhone 11 Pro (A13) Warm | N7P | 289.03 | 4.78 | 60.46 fps/W |
| iPhone 11 Pro (A13) Cold / Peak | N7P | 328.90 | 5.93 | 55.46 fps/W |
| iPhone XS (A12) Warm | N7 | 197.80 | 3.95 | 50.07 fps/W |
| iPhone XS (A12) Cold / Peak | N7 | 271.86 | 6.10 | 44.56 fps/W |
| QRD865 (Snapdragon 865) | N7P | 206.07 | 4.70 | 43.84 fps/W |
| Galaxy 10+ (Snapdragon 855) | N7 | 167.16 | 4.10 | 40.70 fps/W |
| Mate 30 Pro (Kirin 990 4G) | N7 | 152.27 | 4.34 | 35.08 fps/W |
| Galaxy S9+ (Snapdragon 845) | 10LPP | 150.40 | 4.42 | 34.00 fps/W |
| Galaxy 10+ (Exynos 9820) | 8LPP | 166.00 | 4.96 | 33.40fps/W |
| Galaxy S9 (Exynos 9810) | 10LPP | 141.91 | 4.34 | 32.67 fps/W |
| Galaxy S8 (Snapdragon 835) | 10LPE | 108.20 | 3.45 | 31.31 fps/W |
| Mate 20 Pro (Kirin 980) | N7 | 135.75 | 4.64 | 29.25 fps/W |
| Galaxy S8 (Exynos 8895) | 10LPE | 121.00 | 5.86 | 20.65 fps/W |
Lastly, the T-Rex benchmark which is the least compute heavy workload tested here, and mostly is bottlenecked by texture and fillrate throughput, sees a 23% increase for the Snapdragon 865.
Overall GPU Conclusion – Good Improvements – Competitively Not Enough
Overall, we were able to verify the Snapdragon 865’s performance improvements and Qualcomm’s 25% claims seem to be largely accurate. The issue is that this doesn’t seem to be enough to keep up with the large improvements that Apple has been able to showcase over the last two generations.
During the chipset’s launch, Qualcomm was eager to mention that their product is able to showcase better long-term sustained performance than a competitor which “throttles within minutes”. While we don’t have confirmation as to whom exactly they were referring to, the data and narrative here only matches Apple’s device behaviour. Whilst we weren’t able to test the sustained performance of the QRD865 today, it unfortunately doesn’t really matter for Qualcomm as the Snapdragon 865 and Adreno 650’s peak performance falls in at a lower level than Apple’s A13 sustained performance.
Apple isn’t the only one Qualcomm has to worry about; the 25% performance increases this generation are within reach of Arm’s Mali-G77. In theory, Samsung’s Exynos 990 should be able to catch up with the Snapdragon 865. Qualcomm had been regarded as the mobile GPU leader over the last few years, but it’s clear that development has slowed down quite a lot recently, and the Adreno family has lost its crown.








178 Comments
View All Comments
Bulat Ziganshin - Monday, December 16, 2019 - link
The Spec2006 tables show that A13 has performance similar to x86 desktop chips, which may be considered as revolution. Can you please add frequencies of the chips (both x86 and Apple) too, at least some estimations? Also, what are the memory configs (freq/CAS/...)? It will be also interesting to see x86 chips in individual SPEC benchmarks so we can analyze what are the weak and string points of Apple architecture.Andrei Frumusanu - Monday, December 16, 2019 - link
The Apple chips are running near their peak frequencies, with some subtests being slightly throttled due to power. The 9900K was at 5GHz, the 3950X at 4.6-4.65GHz, 3200CL16 on the desktop parts.I added the detailed overview over all chips; here's it again: https://images.anandtech.com/doci/15207/SPEC2006_o...
unclevagz - Monday, December 16, 2019 - link
It would be nice if some contemporary x86 laptop chips could be added to that list (Ryzen/Ice Lake/Coffee Lake...) just for ease of comparison between ARM and x86 mobile chips.sam_ - Monday, December 16, 2019 - link
Any strong reason for these tests being compiled with -mcpu=cortex-a53 on Android/Linux?One might expect for SoCs with 8.2 on all cores there may be some uplift from at least targeting cortex-a55, if not cortex-a75?
When you're expecting to run on a big core, forcing the compiler to target a in-order core which can only execute one ASIMD instruction per cycle seems likely to restrict the perf (unrolling insufficiently etc.). Certainly seems a bit unfair for aarch64 vs. x64 comparison, and probably makes the apple SoCs look better too (assuming XCode isn't targeting a LITTLE core by default). It also likely makes newer bigger cores look worse than they should vs. older cores with smaller OoO windows.
I get not wanting to target compilation to every CPU individually, but would be interesting to know how much of an effect this has; perhaps this could contribute to the expected IPC gains for FP not being achieved?
Andrei Frumusanu - Monday, December 16, 2019 - link
The tuning models only have very minor impact on the performance results. Whilst using the respective models for each µarch can give another 1-1.5% boost in some tests, as an overall average across all micro-architectures I found that giving the A53 model results in the highest performance. This is compared to not supplying any model at all, or using the common A57 model.The A55 model just points to the A53 scheduling model, so they're the same.
sam_ - Monday, December 16, 2019 - link
Hmm, I took a look at LLVM and the scheduling model is indeed the same for A53 and A55, but A55 should enable instruction generation for the various extensions introduced since v8.0. I can believe that for spec 2006 8.1 atomics/SQRDMLAH/fp16/dot product/etc. instructions don't get generated.It looks like not much attention has been paid to tweaking the LLVM backend for more recent big cores than A57, beyond getting the features right for instruction generation, so I can believe cortex-a53 still ends up within a couple of percent of more specific tuning. Probably means there's more work to be done on LLVM.
If it is easy to test I think it would be interesting to try cortex-a57, or maybe exynos-m4 tuning on a77 because these targets do seem to unroll more aggressively than other cortex-X targets with the current LLVM backend.
I made a toy example on godbolt: https://godbolt.org/z/8i9U5- , though for this particular loop I think a77 would have the vector integer MLA unit saturated with unroll by 2 (and is probably memory bound!), still the other targets would seem more predisposed to exposing instruction level parallelism.
Andrei Frumusanu - Tuesday, December 17, 2019 - link
I pointed out to Arm that there's not much optimisations going on in terms of the models, but they said that they're not putting a lot of effort into that, and instead trying to optimise the general Arm64 target.I tested the A57 targets in the past, I'll have a look again on things like the M4 tuning over the coming months as I finally get to port SPEC2017.
Quantumz0d - Monday, December 16, 2019 - link
Sigh another comment on the x86 vs A series. Why dont people understand running an x86 code on ARM will have a massive impact in performance ? How do people think a fanless BGA processor with sub 10W design beat an x86 in realworld just because it has Muh Benchwarrior ? There are so many possible workloads from SIMD, HT/SMT, ALU.Having scalability is also the key. Look at x86 AMD and Intel how they do it by making a Large Wafer and having multi SKUs with LGA/PGA (AM4) sockets allowing for maximum robustness.
ARM is all about efficiency and economical bandwidth and it won't scale like x86 for all workloads. If you add AVX its dead. And Freq scaling with HT/SMT. Add the TSMC N7 which is only fit for mobile SoCs. Ryzen don't scale much into clocks because of this limitation.
ARM is always Custom if you see as per Vendor. Its bad. Look at MediaTek trash no GPL policy. Huawei as well. Except QcommCAF and Exynos. Its a shame that TI OMAP left.
Andrei Frumusanu - Monday, December 16, 2019 - link
> Why dont people understand running an x86 code on ARM will have a massive impact in performance ?Nobody even mentioned anything regarding this, you're going off on a nonsensical rant yet again. For once, please keep the comments section level-headed.
Quantumz0d - Monday, December 16, 2019 - link
What ? Its a genuine point. ARM based 8c processors Windows machines like Surface Pro X can only emulate 32bit x86 code. 64bit isnt here and running both emulation will have am impact (slow) That's what I mean. They need native code to run and rival.Rant ? Benches = Realworld right. How come a user is able to see an OP7 Pro breeze through and not lag and offer shitty performance vs an iPhone ? I saw with my own OP3 downclocked on Sultan ROM due to the high clockspeed bug on 82x platform not just me, So many other users. GB score and benches do not only mean performance esp in ARM arena.
Except for bragging rights, This is pure Whiteknighting.