The AMD Ryzen 9 3950X Review: 16 Cores on 7nm with PCIe 4.0
by Dr. Ian Cutress on November 14, 2019 9:00 AM ESTCPU Performance: Web and Legacy Tests
While more the focus of low-end and small form factor systems, web-based benchmarks are notoriously difficult to standardize. Modern web browsers are frequently updated, with no recourse to disable those updates, and as such there is difficulty in keeping a common platform. The fast paced nature of browser development means that version numbers (and performance) can change from week to week. Despite this, web tests are often a good measure of user experience: a lot of what most office work is today revolves around web applications, particularly email and office apps, but also interfaces and development environments. Our web tests include some of the industry standard tests, as well as a few popular but older tests.
We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
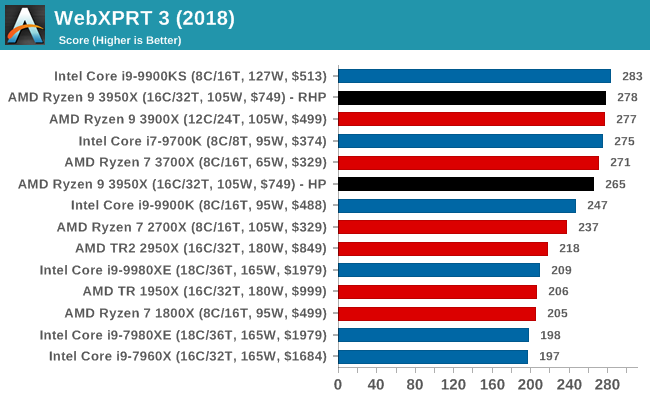
WebXPRT 3: Modern Real-World Web Tasks, including AI
The company behind the XPRT test suites, Principled Technologies, has recently released the latest web-test, and rather than attach a year to the name have just called it ‘3’. This latest test (as we started the suite) has built upon and developed the ethos of previous tests: user interaction, office compute, graph generation, list sorting, HTML5, image manipulation, and even goes as far as some AI testing.
For our benchmark, we run the standard test which goes through the benchmark list seven times and provides a final result. We run this standard test four times, and take an average.
Users can access the WebXPRT test at http://principledtechnologies.com/benchmarkxprt/webxprt/
WebXPRT 2015: HTML5 and Javascript Web UX Testing
The older version of WebXPRT is the 2015 edition, which focuses on a slightly different set of web technologies and frameworks that are in use today. This is still a relevant test, especially for users interacting with not-the-latest web applications in the market, of which there are a lot. Web framework development is often very quick but with high turnover, meaning that frameworks are quickly developed, built-upon, used, and then developers move on to the next, and adjusting an application to a new framework is a difficult arduous task, especially with rapid development cycles. This leaves a lot of applications as ‘fixed-in-time’, and relevant to user experience for many years.
Similar to WebXPRT3, the main benchmark is a sectional run repeated seven times, with a final score. We repeat the whole thing four times, and average those final scores.

Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a accrued test over a series of javascript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics. We report this final score.

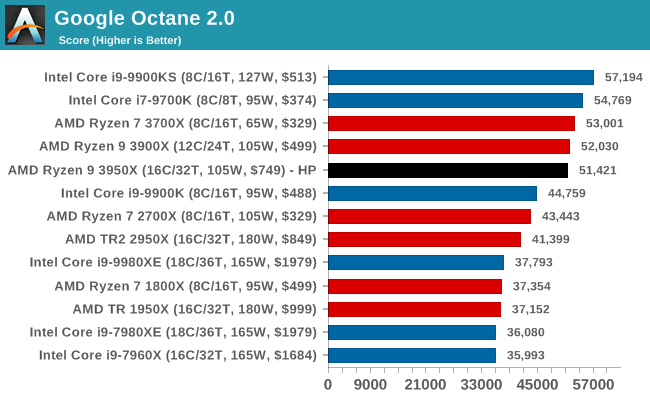
Google Octane 2.0: Core Web Compute
A popular web test for several years, but now no longer being updated, is Octane, developed by Google. Version 2.0 of the test performs the best part of two-dozen compute related tasks, such as regular expressions, cryptography, ray tracing, emulation, and Navier-Stokes physics calculations.
The test gives each sub-test a score and produces a geometric mean of the set as a final result. We run the full benchmark four times, and average the final results.
Mozilla Kraken 1.1: Core Web Compute
Even older than Octane is Kraken, this time developed by Mozilla. This is an older test that does similar computational mechanics, such as audio processing or image filtering. Kraken seems to produce a highly variable result depending on the browser version, as it is a test that is keenly optimized for.
The main benchmark runs through each of the sub-tests ten times and produces an average time to completion for each loop, given in milliseconds. We run the full benchmark four times and take an average of the time taken.

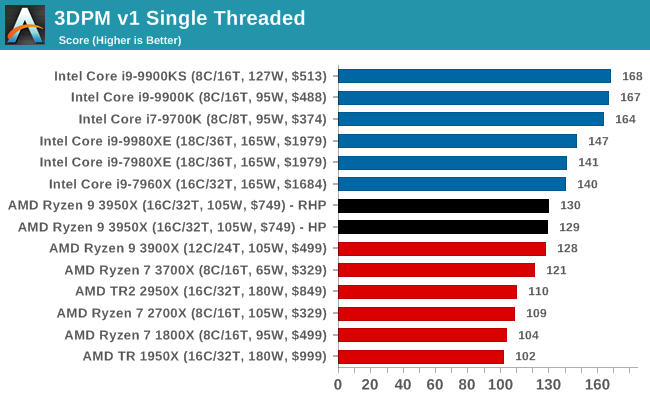
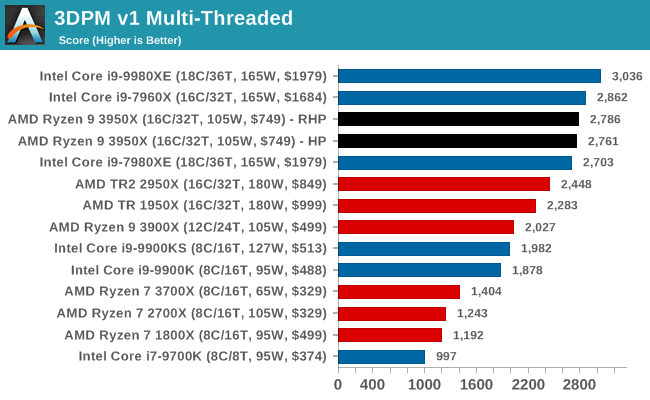
3DPM v1: Naïve Code Variant of 3DPM v2.1
The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes).
In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures.
3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
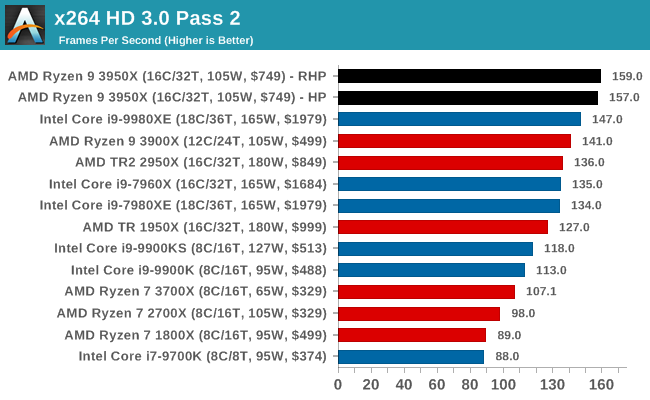
x264 HD 3.0: Older Transcode Test
This transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.

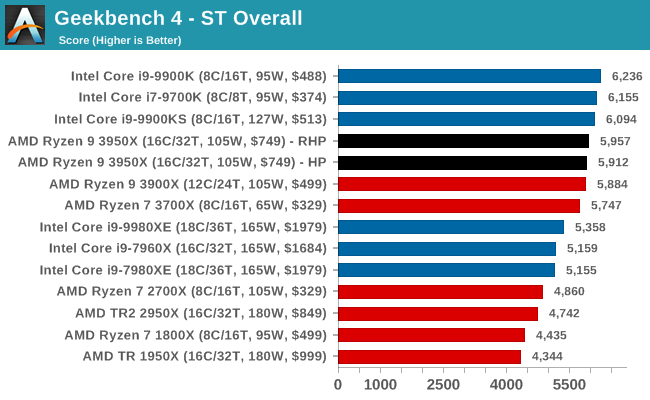
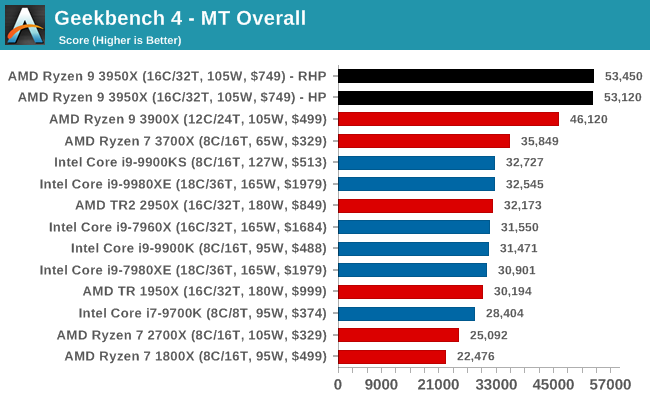
GeekBench4: Synthetics
A common tool for cross-platform testing between mobile, PC, and Mac, GeekBench 4 is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We record the main subtest scores (Crypto, Integer, Floating Point, Memory) in our benchmark database, but for the review we post the overall single and multi-threaded results.








206 Comments
View All Comments
Drazick - Sunday, November 17, 2019 - link
The DDR Technology is orthogonal.I want Quad and the latest memory available.
guyr - Friday, December 20, 2019 - link
Anything is possible, of course. 5 years ago, who would have predicted 16 cores in a consumer-oriented CPU? However, neither Intel nor AMD has made any moves beyond 2 memory channels in the consumer space. The demand is simply not there to justify the increase in complexity and price. In the professional space, more channels are easily justified and the target market doesn't hesitate to pay the higher prices. So, it's all driven by what the market will bear.alufan - Saturday, November 16, 2019 - link
weird intel launches its chip a couple of weeks ago and it stayed upfront and main story for over a week, AMD launches what is in effect the best CPU ever tested by this site and it lasts a few Days before being pushed aside for another intel article am sure the intention by the reporters is to be fair and unbiased however I can see how the commercial motives of the site are being manipulated looks like intels up to its old tricks again, the thread ripper article lasted even less time but no chips have been tested(or at least released) yet which I guess makes sensepenev91 - Sunday, November 17, 2019 - link
Just ignore everything Intel/AMD related on Anandtech. There's been an obvious bias for years.Atom2 - Saturday, November 16, 2019 - link
There has never been a situation as big as this one, where the bench software was benchmarked more than the hardware. Comprehensive overview of historic software development? Whatever the reason, it seems that keeping back AVX512 to only select few CPUs, was an unfortunate decision by Intel, which only contributed to the situation. Yes, you know, if you compile your code with compiler from 1998 and ignore all the guidelines how to write fast code ... Voila... For some reason however, nobody tries to run 20 year old CPU code on GPU though.chrkv - Monday, November 18, 2019 - link
Second page "On the Ryzen High Performance power plan, our sustained single core frequency dropped to 4450 MHz" - I believe just "the High Performance" should be here.Page 4 "Despite 5.0 GHz all-core turbo being on the 9900K" - should be "9900KS".
Irata - Tuesday, November 19, 2019 - link
Quick question: Are any of your benchmarks affected by the Mathlab issue (Ryzen are crippled because a poor code path is used due to a vendor ID check for "genuine Intel" )?twotwotwo - Tuesday, November 19, 2019 - link
Intel's had these consumer-platform-based "entry-level Xeons" (once E3, now E) for a while. Despite some obvious limits, and that there are other low-end server options, enough folks want 'em to seed an ecosystem of rackmount and blade servers from Supermicro, Dell, etc.Anyway, the "pro" (ECC/management enabled) variant of Ryzen seems like a great fit for that. 16 cores and 24 PCIe 4 lanes are probably more useful for little servers than for most desktop users. It's also more balanced than the 8/16C EPYCs; it's cool they have 128 lanes and tons of memory channels, but it takes very specific applications to use them all with that few cores (caching?). Ideally the lesser I/O and lower TDPs also help make denser/cheaper boxes, and the consumer-ish clocks pay off for some things.
The biggest argument against is that the entry-level server market is probably shrinking anyway as users rent tiny slices of huge boxes from cloud providers instead. It also probably doesn't have the best margins. So maybe you could release a competitive product there and still not make all that much off it.
halfflat - Thursday, November 21, 2019 - link
Very curious about the AVX512 vs AVX2 results for 3dPM. It's really unusual to see even a 2x performance increase going from AVX2 to AVX512 on the same architecture, given that running AVX512 instructions will lower the clock.The non-AVX versions, I'm presuming, are utilizing SSE2.
The i9-9900K gets a factor of 2 increase going from SSE2 to AVX2, which is pretty much what one would expect with twice as many fp operations per instruction. But the i9-7960X performance with AVX512 is *ten times* improved over SSE2, when the vector is only four times as wide and the cores will be running at a lower clock speed.
Is there some particular AVX512-only operation that is determining this huge performance gap? Some further analysis of these results would be very interesting.
AIV - Wednesday, November 27, 2019 - link
Somebody posted that it's caused by 64 bit integer multiplies, which are supported in AVX512, but not in AVX2 and thus fallback to scalar operations.