It’s a Cascade of 14nm CPUs: AnandTech’s Intel Core i9-10980XE Review
by Dr. Ian Cutress on November 25, 2019 9:00 AM ESTCPU Performance: System Tests
Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3D model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.

We saw a slight regression here with the 10980XE, which may be down to some of the security updates given that this benchmark tests loading a program which can involve user mode changes.
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
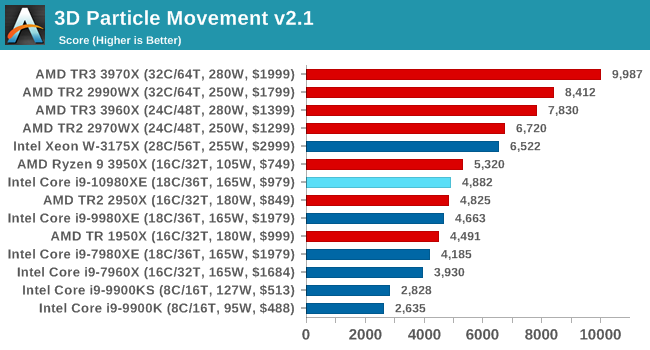
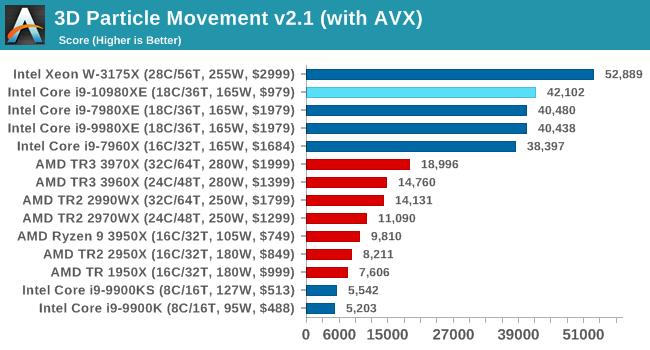
The extra frequency shows a bit here in MT mode, but otherwise equal performance to the 9980XE.
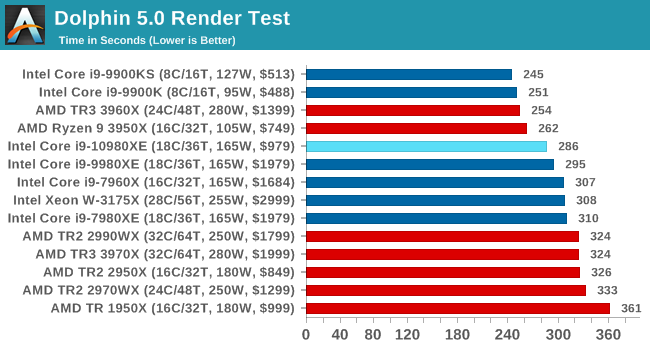
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/
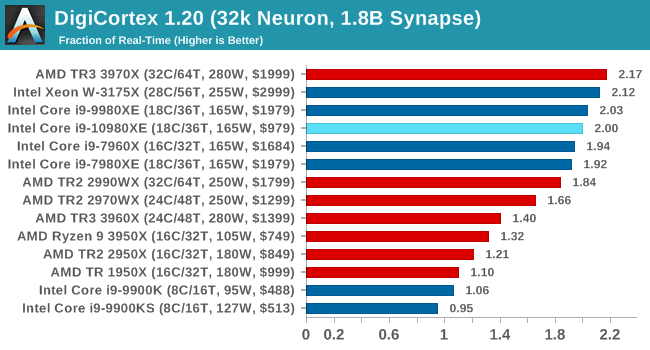
DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.
Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
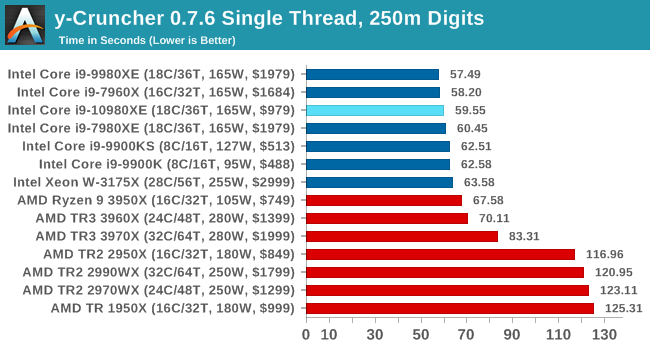
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

The 10980XE here becomes the fastest Intel CPU we've tested on Photoscal, with a sizeable uplift over the 9980XE. This is likely due to the faster memory.








79 Comments
View All Comments
Thanny - Wednesday, November 27, 2019 - link
Zen does not support AVX-512 instructions. At all.AVX-512 is not simply AVX-256 (AKA AVX2) scaled up.
Something to consider is that AVX-512 forces Intel chips to run at much slower clock speeds, so if you're mixing workloads, using AVX-512 instructions could easily cause overall performance to drop. It's only in an artificial benchmark situation where it has such a huge advantage.
Everett F Sargent - Monday, November 25, 2019 - link
Obviously, AMD just caught up with Intel's 256-bit AVX2, prior to Ryzen 3 AMD only had 128-bit AVX2 AFAIK. It was the only reason I bought into a cheap Ryzen 3700X Desktop (under $600US complete and prebuilt). To get the same level of AVX support, bitwise.I've been using Intel's Fortran compiler since 1983 (back then it was on a DEC VAX).
So I only do math modeling at 64-bits like forever (going back to 1975), So I am very excited that AVX-512 is now under $1KUS. An immediate 2X speed boost over AVX2 (at least for the stuff I'm doing now).
rahvin - Monday, November 25, 2019 - link
I'd be curious how much the AVX512 is used by people. It seems to be a highly tailored for only big math operations which kinda limits it's practical usage to science/engineering. In addition the power use of the module was massive in the last article I read, to the point that the main CPU throttled when the AVX512 was engaged for more than a few seconds.I'd be really curious what percentage of people buying HEDT are using it, or if it's just a niche feature for science/engineering.
TEAMSWITCHER - Tuesday, November 26, 2019 - link
If you don't need AVX512 you probably don't need or even want a desktop computer. Not when you can get an 8-core/16-thread MacBook Pro. Desktops are mostly built for show and playing games. Most real work is getting done on laptops.Everett F Sargent - Tuesday, November 26, 2019 - link
LOL, that's so 2019.Where I am from it's smartwatches all the way down.
Queue Four Yorkshiremen.
AIV - Tuesday, November 26, 2019 - link
Video processing and image processing can also benefit from AVX512. Many AI algorithms can benefit from AVX512. Problem for Intel is that in many cases where AVX512 gives good speedup, GPU would be even better choice. Also software support for AVX512 is lacking.Everett F Sargent - Tuesday, November 26, 2019 - link
Not so!https://software.intel.com/en-us/parallel-studio-x...
It compiles and runs on both Intel and AMD. Full AVX-512 support on AVX-512 hardware.
You have to go full Volta to get true FP64, otherwise desktop GPU's are real FP64 dogs!
AIV - Wednesday, November 27, 2019 - link
There are tools and compilers for software developers, but not so much end user software actually use them. FP64 is mostly required only in science/engineering category. Image/video/ai processing is usually just fine with lower precision. I'd add that also GPUs only have small (<=32GB) RAM while intel/amd CPUs can have hundreds of GB or more. Some datasets do not fit into a GPU. AVX512 still has its niche, but it's getting smaller.thetrashcanisfull - Monday, November 25, 2019 - link
I asked about this a couple of months ago. Apparently the 3DPM2 code uses a lot of 64b integer multiplies; the AVX2 instruction set doesn't include packed 64b integer mul instructions - those were added with AVX512, along with some other integer and bit manipulation stuff. This means that any CPU without AVX512 is stuck using scalar 64b muls, which on modern microarchitectures only have a throughput of 1/clock. IIRC the Skylake-X core and derivatives have two pipes capable of packed 64b muls, for a total throughput of 16/clock.I do wish AnandTech would make this a little more clear in their articles though; it is not at all obvious that the 3DPM2 is more of a mixed FP/Integer workload, which is not something I would normally expect from a scientific simulation.
I also think that the testing methodology on this benchmark is a little odd - each algorithm is run for 20 seconds, with a 10 second pause in between? I would expect simulations to run quite a bit longer than that, and the nature of turbo on CPUs means that steady-state and burst performance might diverge significantly.
Dolda2000 - Monday, November 25, 2019 - link
Thanks a lot, that does explain much.