It’s a Cascade of 14nm CPUs: AnandTech’s Intel Core i9-10980XE Review
by Dr. Ian Cutress on November 25, 2019 9:00 AM ESTGaming: F1 2018
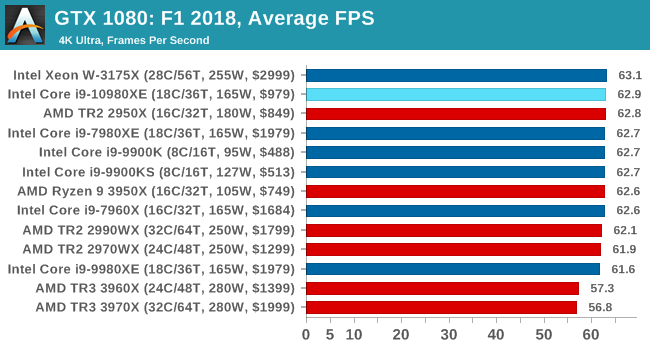
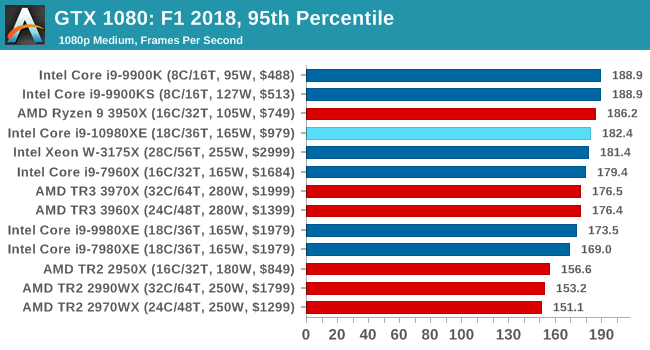
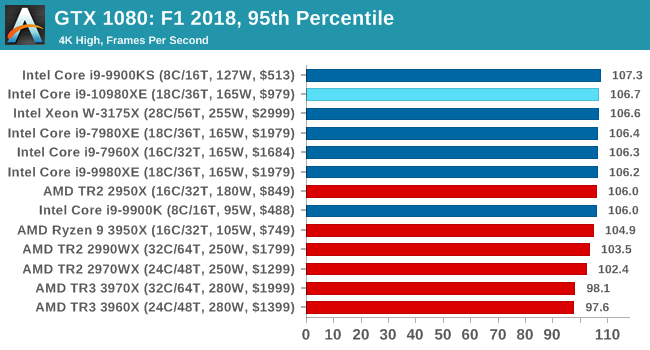
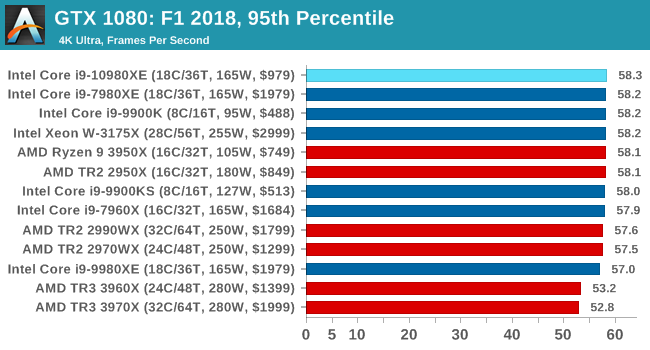
Aside from keeping up-to-date on the Formula One world, F1 2017 added HDR support, which F1 2018 has maintained; otherwise, we should see any newer versions of Codemasters' EGO engine find its way into F1. Graphically demanding in its own right, F1 2018 keeps a useful racing-type graphics workload in our benchmarks.
We use the in-game benchmark, set to run on the Montreal track in the wet, driving as Lewis Hamilton from last place on the grid. Data is taken over a one-lap race.
All of our benchmark results can also be found in our benchmark engine, Bench.
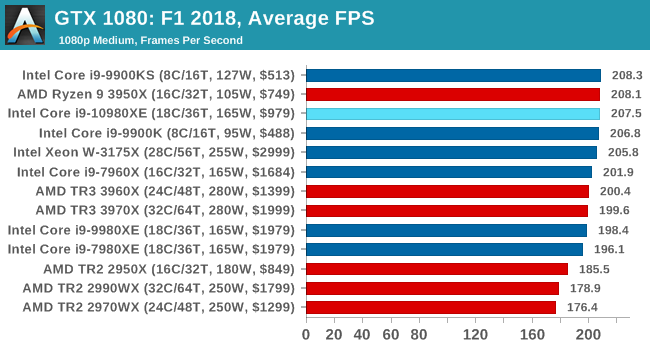
| AnandTech | IGP | Low | Medium | High |
| Average FPS | 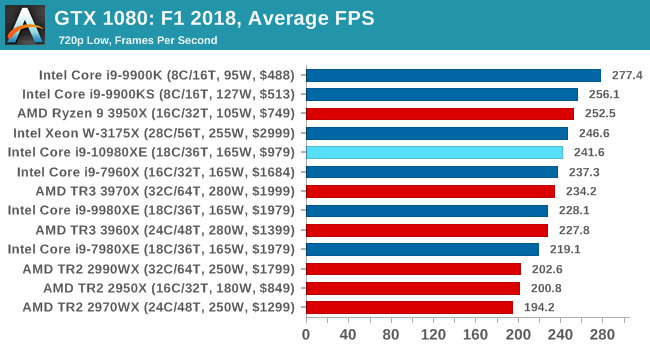 |
 |
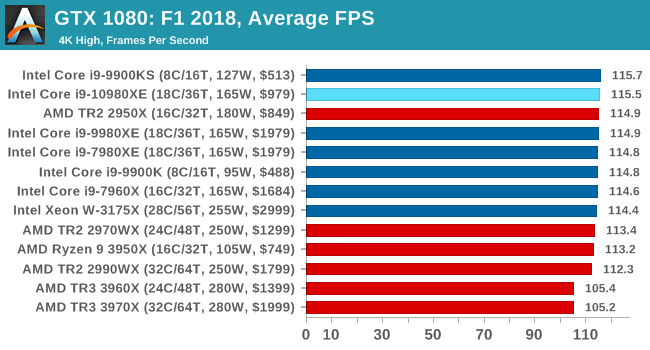 |
 |
| 95th Percentile | 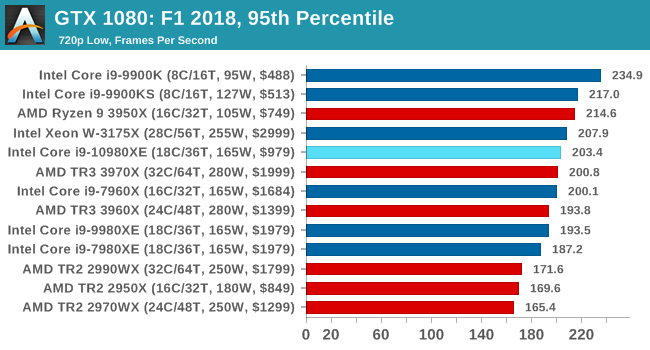 |
 |
 |
 |








79 Comments
View All Comments
Thanny - Wednesday, November 27, 2019 - link
Zen does not support AVX-512 instructions. At all.AVX-512 is not simply AVX-256 (AKA AVX2) scaled up.
Something to consider is that AVX-512 forces Intel chips to run at much slower clock speeds, so if you're mixing workloads, using AVX-512 instructions could easily cause overall performance to drop. It's only in an artificial benchmark situation where it has such a huge advantage.
Everett F Sargent - Monday, November 25, 2019 - link
Obviously, AMD just caught up with Intel's 256-bit AVX2, prior to Ryzen 3 AMD only had 128-bit AVX2 AFAIK. It was the only reason I bought into a cheap Ryzen 3700X Desktop (under $600US complete and prebuilt). To get the same level of AVX support, bitwise.I've been using Intel's Fortran compiler since 1983 (back then it was on a DEC VAX).
So I only do math modeling at 64-bits like forever (going back to 1975), So I am very excited that AVX-512 is now under $1KUS. An immediate 2X speed boost over AVX2 (at least for the stuff I'm doing now).
rahvin - Monday, November 25, 2019 - link
I'd be curious how much the AVX512 is used by people. It seems to be a highly tailored for only big math operations which kinda limits it's practical usage to science/engineering. In addition the power use of the module was massive in the last article I read, to the point that the main CPU throttled when the AVX512 was engaged for more than a few seconds.I'd be really curious what percentage of people buying HEDT are using it, or if it's just a niche feature for science/engineering.
TEAMSWITCHER - Tuesday, November 26, 2019 - link
If you don't need AVX512 you probably don't need or even want a desktop computer. Not when you can get an 8-core/16-thread MacBook Pro. Desktops are mostly built for show and playing games. Most real work is getting done on laptops.Everett F Sargent - Tuesday, November 26, 2019 - link
LOL, that's so 2019.Where I am from it's smartwatches all the way down.
Queue Four Yorkshiremen.
AIV - Tuesday, November 26, 2019 - link
Video processing and image processing can also benefit from AVX512. Many AI algorithms can benefit from AVX512. Problem for Intel is that in many cases where AVX512 gives good speedup, GPU would be even better choice. Also software support for AVX512 is lacking.Everett F Sargent - Tuesday, November 26, 2019 - link
Not so!https://software.intel.com/en-us/parallel-studio-x...
It compiles and runs on both Intel and AMD. Full AVX-512 support on AVX-512 hardware.
You have to go full Volta to get true FP64, otherwise desktop GPU's are real FP64 dogs!
AIV - Wednesday, November 27, 2019 - link
There are tools and compilers for software developers, but not so much end user software actually use them. FP64 is mostly required only in science/engineering category. Image/video/ai processing is usually just fine with lower precision. I'd add that also GPUs only have small (<=32GB) RAM while intel/amd CPUs can have hundreds of GB or more. Some datasets do not fit into a GPU. AVX512 still has its niche, but it's getting smaller.thetrashcanisfull - Monday, November 25, 2019 - link
I asked about this a couple of months ago. Apparently the 3DPM2 code uses a lot of 64b integer multiplies; the AVX2 instruction set doesn't include packed 64b integer mul instructions - those were added with AVX512, along with some other integer and bit manipulation stuff. This means that any CPU without AVX512 is stuck using scalar 64b muls, which on modern microarchitectures only have a throughput of 1/clock. IIRC the Skylake-X core and derivatives have two pipes capable of packed 64b muls, for a total throughput of 16/clock.I do wish AnandTech would make this a little more clear in their articles though; it is not at all obvious that the 3DPM2 is more of a mixed FP/Integer workload, which is not something I would normally expect from a scientific simulation.
I also think that the testing methodology on this benchmark is a little odd - each algorithm is run for 20 seconds, with a 10 second pause in between? I would expect simulations to run quite a bit longer than that, and the nature of turbo on CPUs means that steady-state and burst performance might diverge significantly.
Dolda2000 - Monday, November 25, 2019 - link
Thanks a lot, that does explain much.