Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
by Dr. Ian Cutress on September 17, 2019 10:00 AM ESTAMD’s Turbo
With AMD introducing Turbo after Intel, as has often been the case in their history, they've had to live in Intel's world. And this has repercussions for the company.
By the time AMD introduced their first Turbo-enabled processors, everyone in the desktop space ‘knew’ what Turbo meant, because we had gotten used to how Intel did things. For everyone, saying ‘Turbo’ meant only one thing: Intel’s definition of Turbo, which we subconsciously took as the default, and that’s all that mattered. Every time an Intel processor family is released, we ask for the Turbo tables, and life is good and easy.
Enter AMD, and Zen. Despite AMD making it clear that Turbo doesn’t work the same way, the message wasn’t pushed home. AMD had a lot of things to talk about with the new Zen core, and Turbo, while important, wasn’t as important as the core performance messaging. Certain parts of how the increased performance were understood, however the finer points were missed, with users (and press) assuming an Intel like arrangement, especially given that the Zen core layout kind of looks like an Intel core layout if you squint.
What needed to be pushed home was the sense of a finer grained control, and how the Ryzen chips respond and use this control.
When users look at an AMD processor, the company promotes three numbers: a base frequency, a turbo frequency, and the thermal design power (TDP). Sometimes an all-core turbo is provided. These processors do not have any form of turbo tables, and AMD states that the design is not engineered to decrease in frequency (and thus performance) when it detects instructions that could cause hot spots.
It should be made clear at this point that Zen (Ryzen 1000, Ryzen 2000) and Zen2 (Ryzen 3000) act very differently when it comes to turbo.
Turbo in Zen
At a base level, AMD’s Zen turbo was just a step function implementation, with two cores getting the higher turbo speed. However, most cores shipped with features that allowed the CPU to get higher-than-turbo frequencies depending on its power delivery and current delivery limitations.
You may remember this graph from the Ryzen 7 1800X launch:
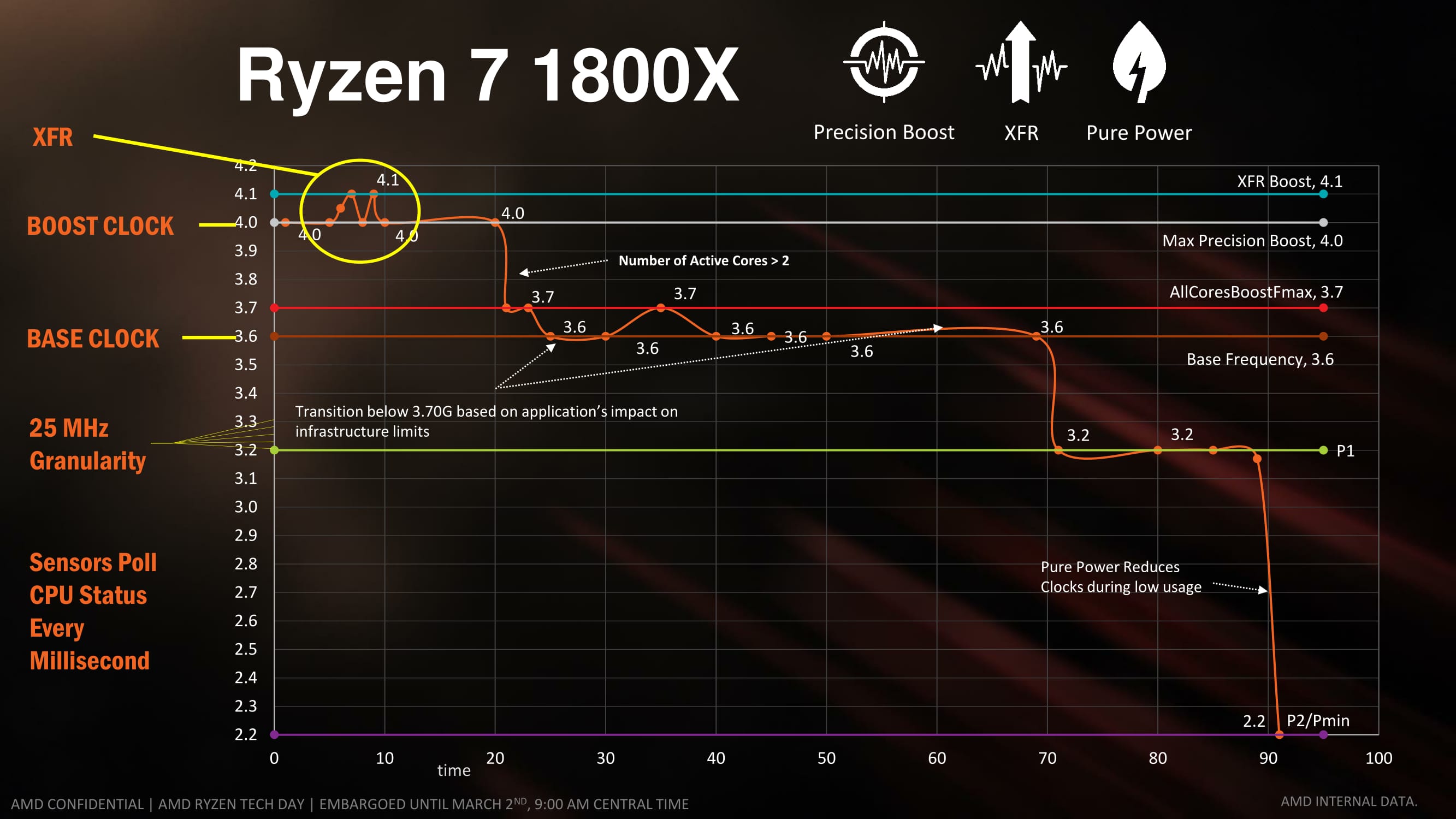
For Zen processors, AMD enabled a 0.25x multiplier increment, which allows the CPU to jump up in 25 MHz steps, rather than 100 MHz. This bit was easy to understand: it meant more flexibility in what the frequency could be at any given time. AMD also announced XFR, or ‘eXtreme Frequency Range’, which meant that with sufficient cooling and power headroom, the CPU could perform better than the rated turbo frequency in the box. Users that had access to a better cooling solution, or had lower ambient temperatures, would expect to see better frequencies, and better performance.
So the Ryzen 7 1800X was a CPU with a 3.6 GHz base frequency and a 4.0 GHz turbo frequency, which it achieves when 2 or fewer cores are active. If possible, the CPU will use the (now depreciated in later models) eXtended Frequency Range feature to go beyond 4.1 GHz if the conditions are correct (thermals, power, current). When more than two cores are active, the CPU drops down to its all-core boost, 3.7 GHz, and may transition down to 3.6 GHz depending on the conditions (thermals, power, current).
Turbo in Zen+, then Zen2
AMD dropped XFR from its marketing materials, tying it all under Precision Boost. Ultimately the boost function of the processor relied on three new metrics, alongside the regular thermal and total power consumption guidelines:
PPT: Socket Power Capacity
TDC: Sustained VRM Capacity
EDC: Peak/Transient VRM Capacity
In order to get the highest turbo frequencies, users would have to score big on all three metrics, as well as cooling, to stop one being a bottleneck. The end result promised by AMD was an aggressive voltage/frequency curve that would ride the limit of the hardware, right up to the TDP listed on the box.
This means we saw a much tighter turbo boost algorithm compared to Zen. Both Zen+ and Zen2 then moved to this boost algorithm that was designed to offer a lot more frequency opportunities in mixed workloads. This was known as Precision Boost 2.
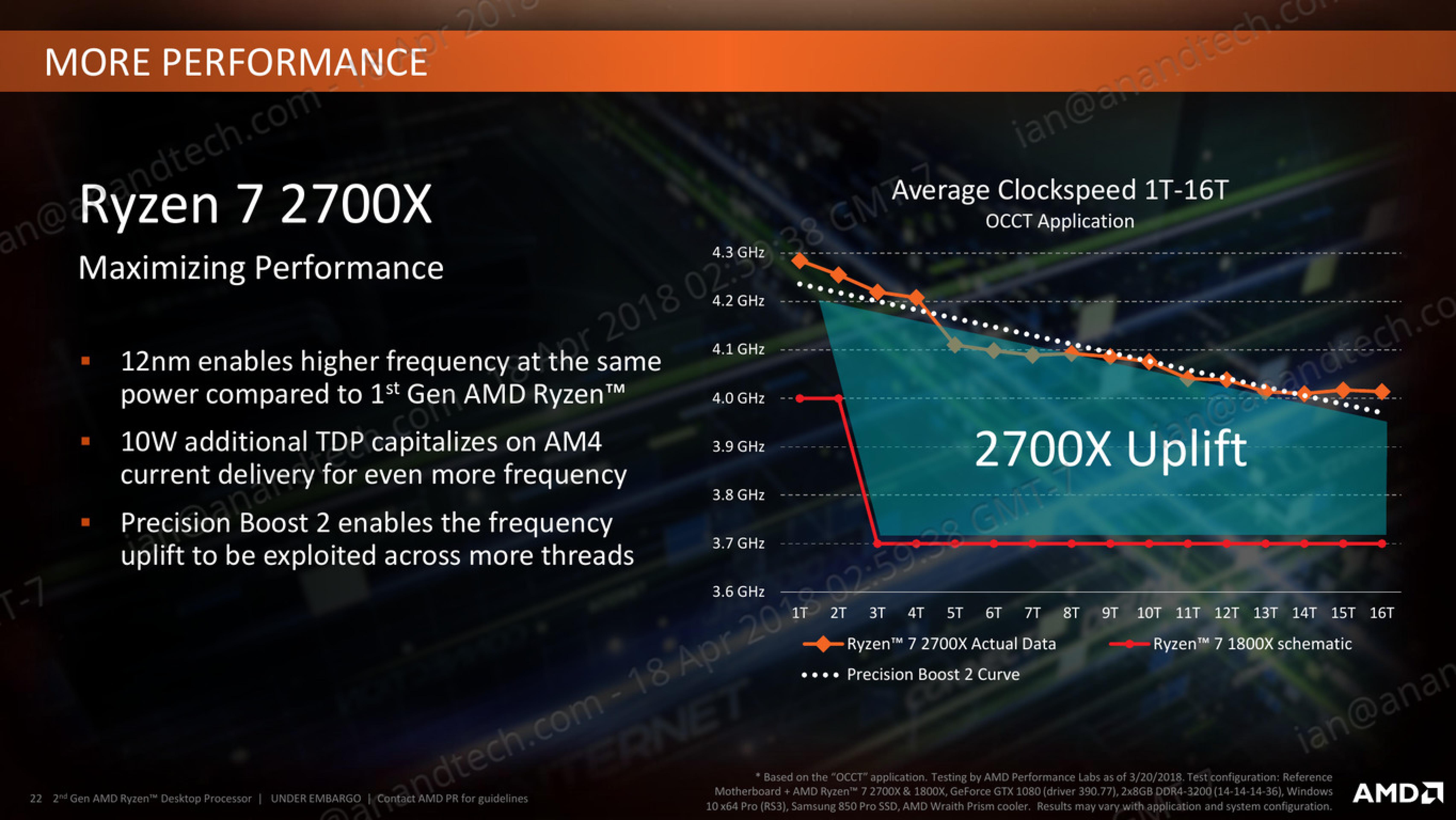
In this algorithm, we saw more than a simple step function beyond two threads, and depending on the specific chip performance as well as the environment the chip was in, the non-linear curve would react to the conditions and the workload to match hit the total power consumption of the chip as listed. The benefit of this was more performance in mixed workloads, in exchange for a tighter power consumption and frequency algorithm.
Move forward to Zen2, and one of the biggest differences for Zen2 is how the CPUs are binned. Since Zen, AMD’s own Ryzen Master software had been listing ‘best cores’ for each chip – for every Ryzen CPU, it would tell the user which cores had performed best based on internal testing, and were predicted to have this best voltage frequency curve. AMD took this a step further, and with the new 7nm process, in order to get the best frequencies out of every chip, it would perform binning per core, and only one core was required to reach the rated turbo speed.

So for example, here is a six-core Ryzen 5 3600X, with a base frequency of 3.8 GHz and a turbo frequency of 4.4 GHz. By binning tightly to the silicon maximums (for a given voltage), AMD was able to extract more performance on specific cores. If AMD had followed Intel’s binning strategy relating to turbo here, we would see a chip that would only be 4.2 GHz or 4.1 GHz maximum turbo – by going close to the chip limits for the given voltage, AMD is arguably offering more turbo functionality and ultimately more immediate performance.
There is one thing to note here though, which was the point of Paul’s article. In order to achieve maximum performance in a given workload, AMD had to adjust the Windows CPPC scheduler in order to assign a workload to the best core. By identifying the best cores on a chip, it meant that when a single threaded workload needed the best speed, it could be assigned to the best core (in our theoretical chip above that would be Core 2).
Note that with an Intel binning strategy, as the binning does not go to the per-core limits but rather relies on per-chip limits, it doesn’t matter what core the work is assigned to: this is the benefit of a homogeneous turbo binning design, and ultimately makes the scheduler algorithm in the operating system very simple. With AMD’s solution, that single best core is frequency scheduled that work, and as such the software stack in place needs to know the operation of the CPU and how to assign work to that specific core.
Does this make any difference to the casual user? No. For anyone just getting on with their daily activities, it makes absolutely zero difference. While the platform exposes the best cores, you need to be able to use tools to see it, and unless you uninstall the driver stack or micromanage where threads are allocated, you can’t really modify it. For casual users, and for gamers, it makes no difference to their workflow.
This binning strategy however does affect casual overclockers looking to get more frequency – based on AMD’s binning, there isn’t much headroom. All-core overclocks don’t really work in this scenario, because the chip is so close to the voltage/frequency curve already. This is why we’re not seeing great all-core overclocks on most Ryzen 3000 series CPUs. In order to get the best overall system overclocks this time around, users are going to have to play with each core one-by-one, which makes the whole process time consuming.
A small note about Precision Boost Overdrive (PBO) here. AMD introduced PBO in Zen and Zen+, and given the binning strategy on those chips, along with the mature 14/12nm process, users with the right thermal environment and right motherboards could extract another 100-200 MHz from the chip without doing much more than flicking a switch in the Ryzen Master software. Because of the new binning strategy – and despite what some of AMD's poorly executed marketing material has been saying – PBO hasn't been having the same effect, and users are seeing little-to-no benefit. This isn’t because PBO is failing, it’s because the CPU out of the box is already near its peak limits, and AMD’s metrics from manufacturing state that the CPU has a lifespan that AMD is happy with despite being near silicon limits. It ends up being a win-win, although people wanting more performance from overclocking aren’t going to get it – because they already have some of the best performance that piece of silicon has to offer.
The other point of assigning workloads to a specific core does revolve around lifespan. Typically over time, silicon is prone to electromigration, where electrons over time will slowly adjust the position of the silicon atoms inside the chip. Adjusting atom positioning typically leads to higher resistance paths, requiring more voltage over time to drive the same frequency, but which also leads to more electromigration. It’s a vicious cycle.
With electromigration, there are two solutions. One is to set the frequency and voltage of the processor low enough that over the expected age of the CPU it won’t ever become an issue, as it happens at such a slow rate – alternatively set the voltage high enough that it won’t become an issue over the lifetime. The second solution is to monitor the effect of electromigration as the core is used over months and years, then adjust the voltage upwards to compensate. This requires a greater level of detection and management inside the CPU, and is arguably a more difficult problem.
What AMD does in Ryzen 3000 is the second solution. The first solution results in lower-than-ideal performance, and so the second solution allows AMD to ride the voltage/frequency limits of a given core. The upshot of this is that AMD also knows (through TSMC’s reporting) how long each chip or each core is expected to last, and the results in their eyes are very positive, even with a single core getting the majority of the traffic. For users that are worried about this, the question is, do you trust AMD?
Also, to point out, Intel could use this method of binning by core. There’s nothing stopping them. It all depends on how comfortable the company is with its manufacturing process aligning with the expected longevity. To a certain extent, Intel already kind of does this with its Turbo Boost Max 3.0 processors, given that they specify specific cores to go beyond the Turbo Boost 2.0 frequency – and these cores get all the priority programs to run at a higher frequency and would experience the same electromigration worries that users might have by running the priority core more often. There difference between the two companies is that AMD has essentially applied this idea chip-wide and through its product stack, while Intel has not, potentially leaving out-of-the-box performance on the table.








144 Comments
View All Comments
Korguz - Thursday, September 19, 2019 - link
so i guess you are ok with intel marketing their chips to only use the watts they state, but under real usage, they can, specially when overclocked, they can use MUCH more ??Cooe - Tuesday, March 23, 2021 - link
It doesn't say "4.7GHz Turbo" it says "Max 4.7GHz Turbo". Aka "UP TO!". It's not AMD's fault if "Average Joe" literally doesn't know how to read...Oliseo - Wednesday, September 18, 2019 - link
Also, if YOU have to write a multi page highly technical article on why AMD is right and all the customers are wrong, then you're just a fanboy who doesn't give a **** about the customer.We get enough of this in the comments with people in the media joining in to make excuses for large multinationals at the expense of the average consumer.
Shame on you!
eva02langley - Wednesday, September 18, 2019 - link
Here, these people will escort you to your new home, the asylum... cheers and enjoy you stray jacket...Calabros - Wednesday, September 18, 2019 - link
This the funniest First World Problem I've seen in 2019.regsEx - Wednesday, September 18, 2019 - link
I can't find any reference in CFL documentation that PL1 is for base clocks. It doesn't seem to have any correlation.edzieba - Wednesday, September 18, 2019 - link
Sounds like the "Intel Performance Maximizer" is exploring and characterising the frequency-space above the all-core turbo clock. That could be done at the factory to provide faster out-of-the-box performance, but would either introduce chip-to-chip variation is stock (rather than OC) performance, or create even more SKU bins. And people already throw a wobbler over he number of SKUs Intel produce (even though 90% of those are not a consideration unless you order direct from them in $multimillion batches).samboy - Wednesday, September 18, 2019 - link
My biggest concern is for the 3950x.This has the highest Turbo specification of all the processors; which was a good selling point when I first saw the specifications
However, it is becoming clear that the all-core base clock speed specification is more important. Particularly given that the 3900x seems to take the least "advantage" of Turbo out of all the current chips.
Comparing the specifications of 3950x to 3900x we see a 300MHZ drop off on base core speed; in exchange for an extra 100MHZ in boost - which seems somewhat questionable now.
A 50% increase in cost for an extra 4 cores and likely slower throughput for tasks that use 12 or less cores (which covers almost everything that is run in practice today) this doesn't look like particularly good value. My untested assumption is that the 300MHZ less in base speed is the more important number and will translate to slower throughput.
I'll wait for the reviews for the 3950x; but I expect that I'll be leaning for the 3900x for the second system I need to build.
oleyska - Wednesday, September 18, 2019 - link
3900X boosts higher than any other ryzen chip out today.I think 3950X will be faster than 3900X, on ryzen amount of cores doesn't matter at all.
Have a ryzen 1700? it isn't at all limited in comparison to a 1600 and on average seems to hit higher frequencies and it's absolutely true for 3000 series, even More so!
ajlueke - Thursday, September 19, 2019 - link
"A 50% increase in cost for an extra 4 cores and likely slower throughput for tasks that use 12 or less cores (which covers almost everything that is run in practice today) this doesn't look like particularly good value."The 3950X will almost certainly be faster than the 3900X in just about every scenario. If you consider the way the two chiplet CPUs are binned, they have one fast chiplet (CCD) and one that is not nearly as fast.
In the 3900X these CCDs are 6 cores each, while they are 8 cores in the 3950X. Which means in an 8 thread workload, the 3950X can do that entire workload on the "better" CCD0, which should have a better frequency/voltage curve. The 3900X will have to dip into 2 cores on CCD1. The 12 core workload is a similar story, the overall frequency/voltage curve will be better on the 3950X because it is boosting more "better" binned cores than the 3900X with the same power envelop.