Hot Chips 31 Keynote Day 1: Dr. Lisa Su, CEO of AMD Live Blog (1:45pm PT)
by Dr. Ian Cutress on August 19, 2019 4:00 PM EST
04:41PM EDT - The keynote for day one at Hot Chips is from Dr. Lisa Su, AMD of CEO. AMD is riding high after successful Ryzen 3000 and 2nd Gen EPYC Rome launches, so it will be interesting to hear what she has to say.
04:41PM EDT - I'm sat down and we should be starting here in a few minutes
04:42PM EDT - The audience suddenly got a lot denser
04:43PM EDT - I'm sitting next to Paul Alcorn from Tom's Hardware. The other usual Hot Chips suspects are in the crowd - Patrick Kennedy, David Schor
04:43PM EDT - I'm sitting next to Paul Alcorn from Tom's Hardware. The other usual Hot Chips suspects are in the crowd - Patrick Kennedy, David Schor
04:47PM EDT - Lisa Su to the stage
04:47PM EDT - AMD is now 50, an age where a company has to reinvent itself
04:48PM EDT - Today we generate a large amount of data. That data has to be processed and analysed. Data is driving the next generation of high performance computing
04:48PM EDT - Hot Chips has had a long time focus on big data and data analytics
04:49PM EDT - Need to do more than Moore's Law, more computation is now necessary
04:49PM EDT - The industry has been driving for high performance compute. Not just AMD
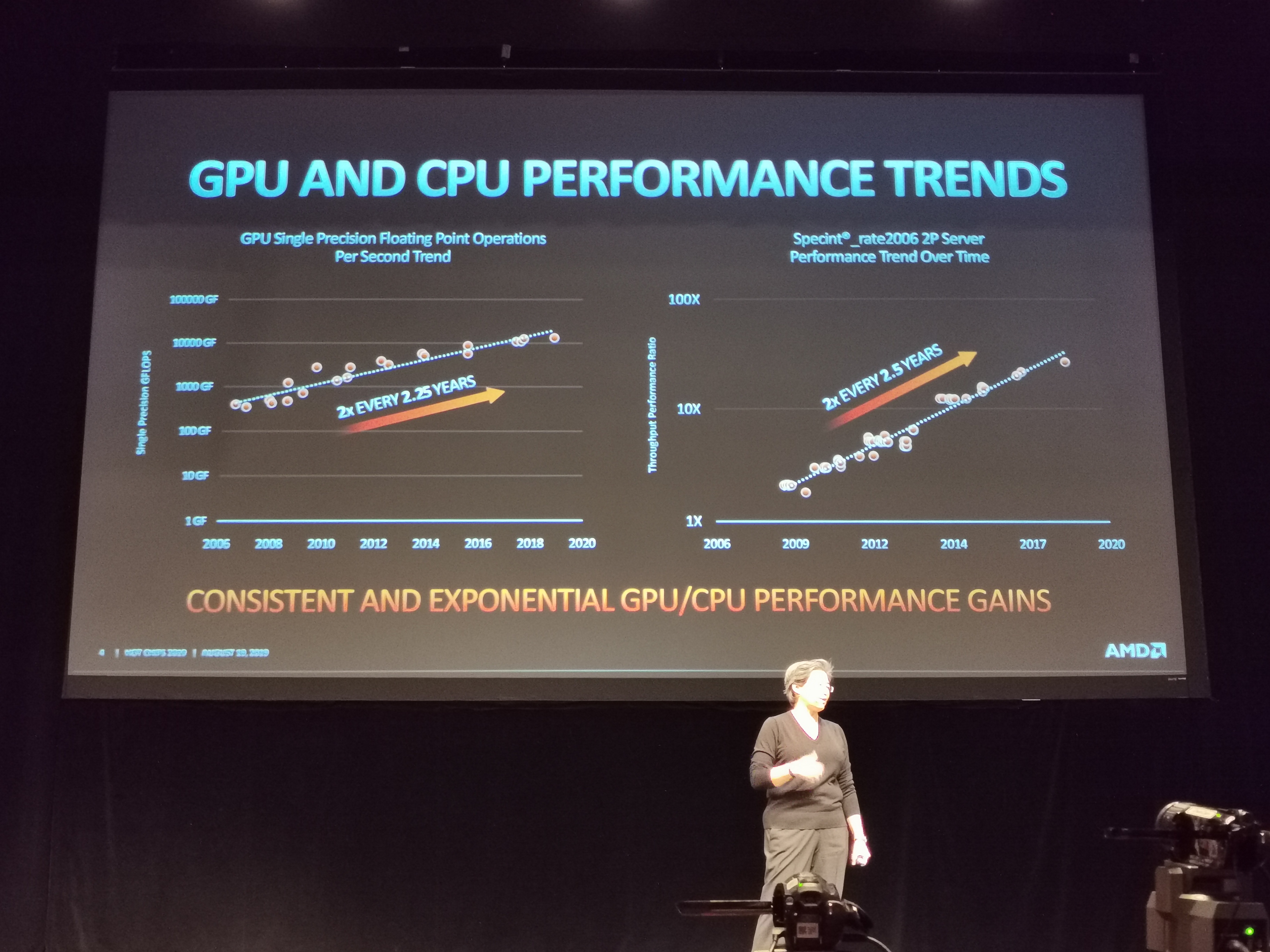
04:50PM EDT - CPU and GPU - doubling perfromance about every 2.5x years. This is the rate and pace of innovation

04:50PM EDT - But density and power efficiency is not improving at the same rate.
04:51PM EDT - Power is becoming the new constraint with the newest generation of products
04:51PM EDT - Need to extend the performance curve
04:51PM EDT - A mix of different of elements to double the perf every 2.5 years:
04:52PM EDT - 40% on process, 8% on additional TDP, 12% on die size. All together are silicon improvements

04:52PM EDT - 17% microarchitecture, 15% on power management, 8% compilers. All of these are non-silicon and architectural

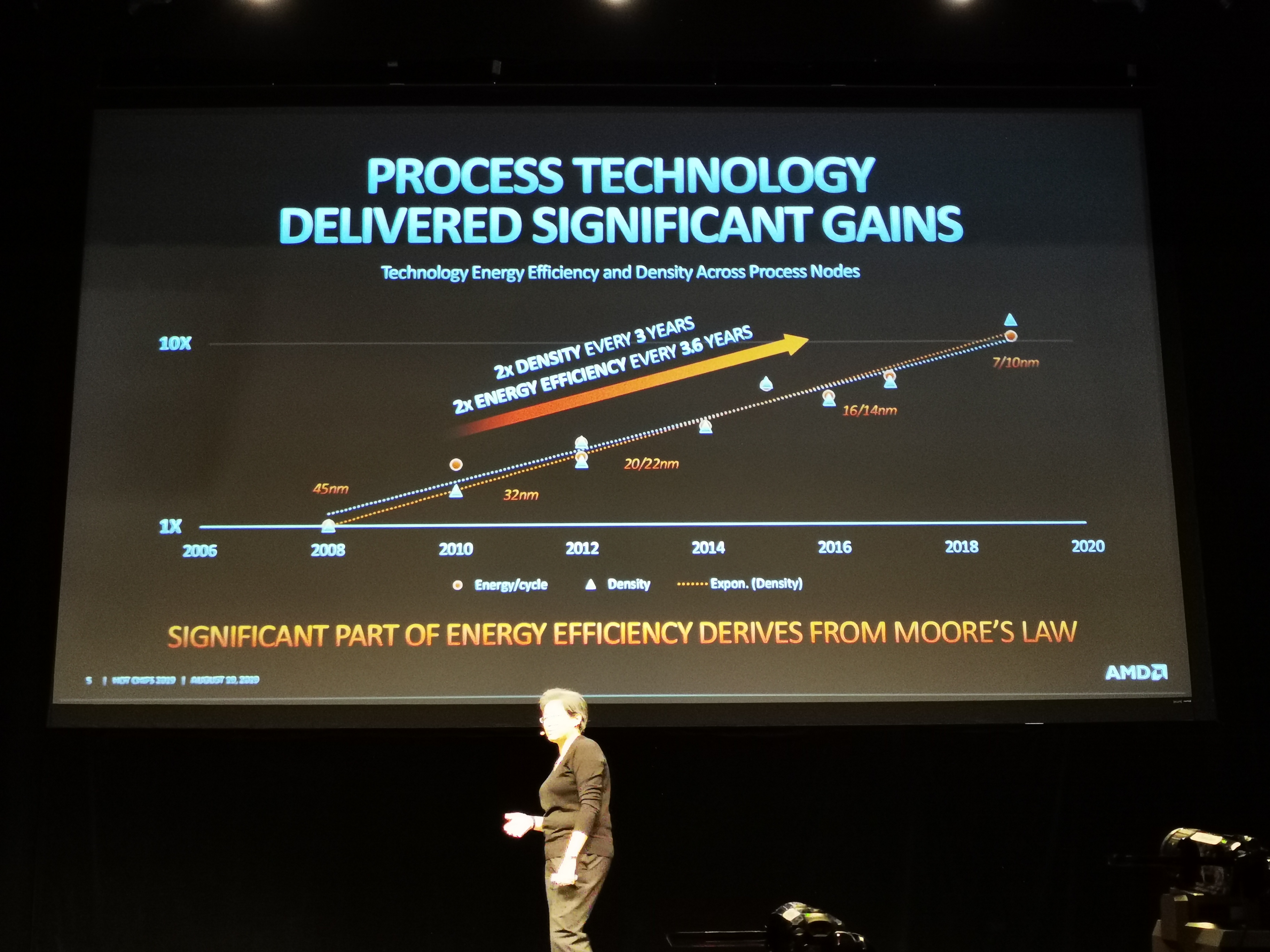
04:53PM EDT - Optimizing hardware and software together
04:53PM EDT - Lots of work to do on every vector

04:53PM EDT - It's getting harder and harder every generation on every vector too
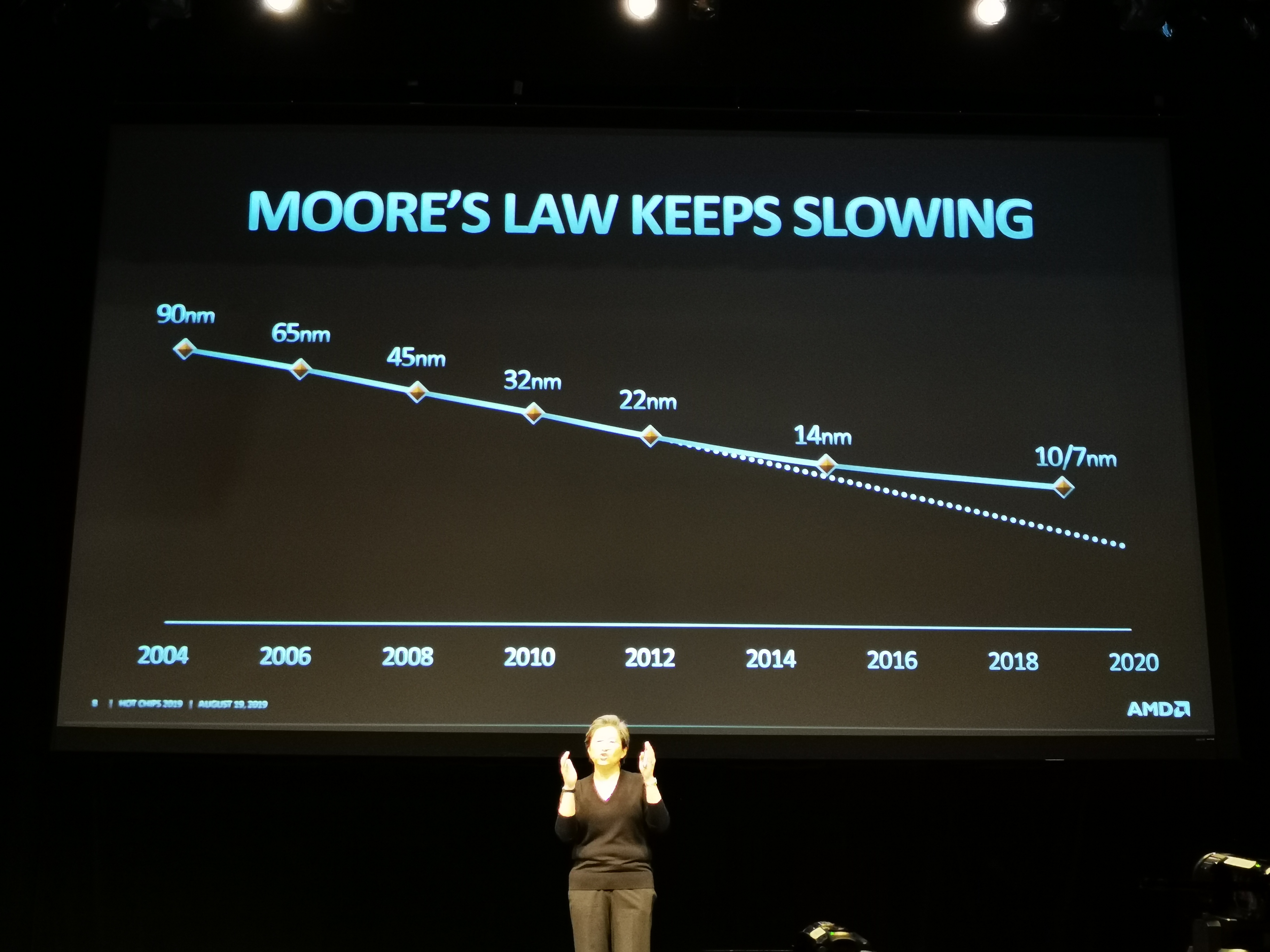
04:53PM EDT - Moore's Law keeps slowing
04:54PM EDT - New process nodes take longer and longer, that reduces some of the cadence gains
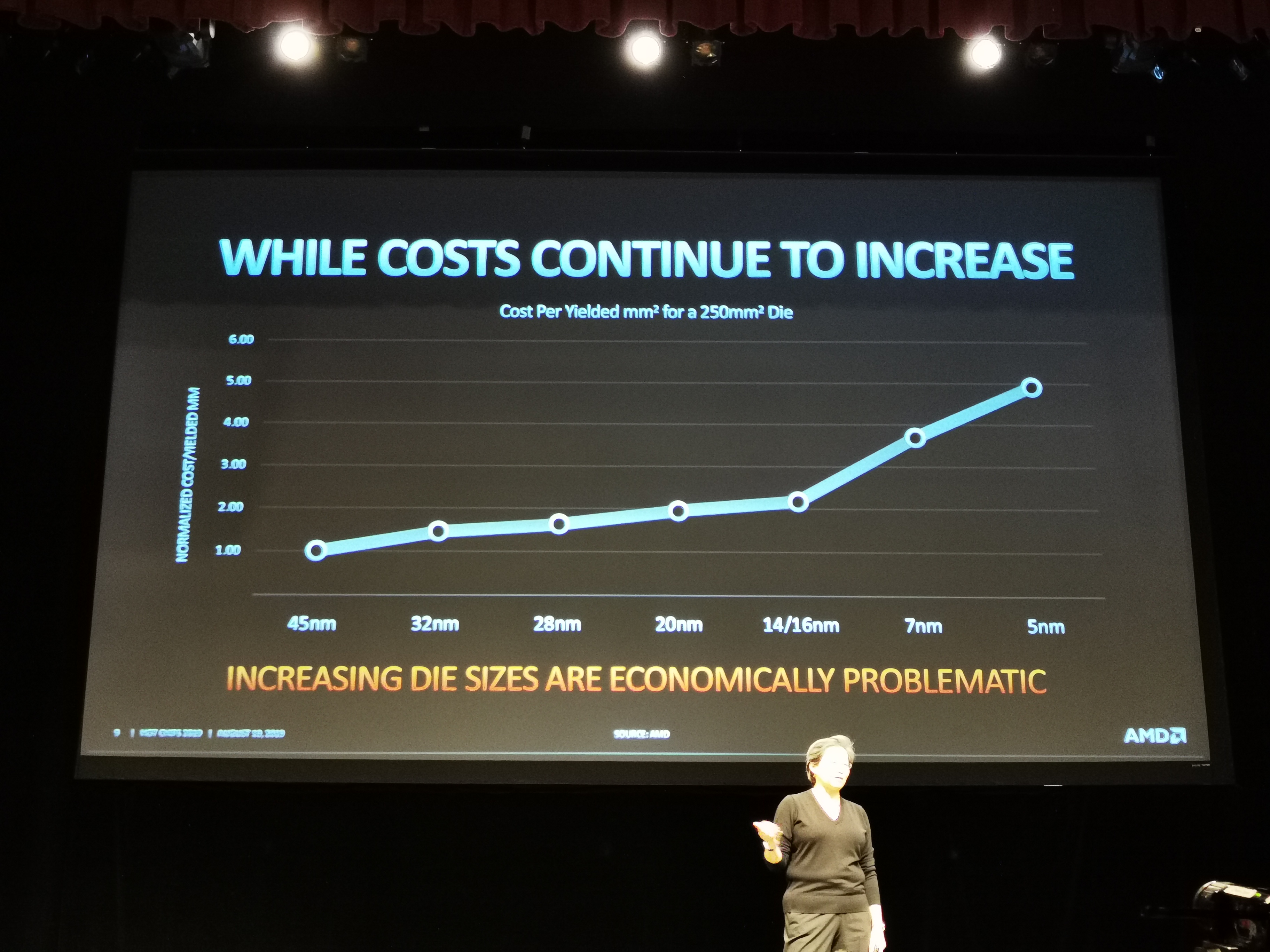
04:54PM EDT - Cost per transistor increases with the newest processes
04:54PM EDT - 7nm is 4x the cost of 45nm
04:55PM EDT - Pushing the envelope with power, +7% YoY
04:56PM EDT - Server power breakdown has changed too
04:56PM EDT - Pure computation of server power is not that big
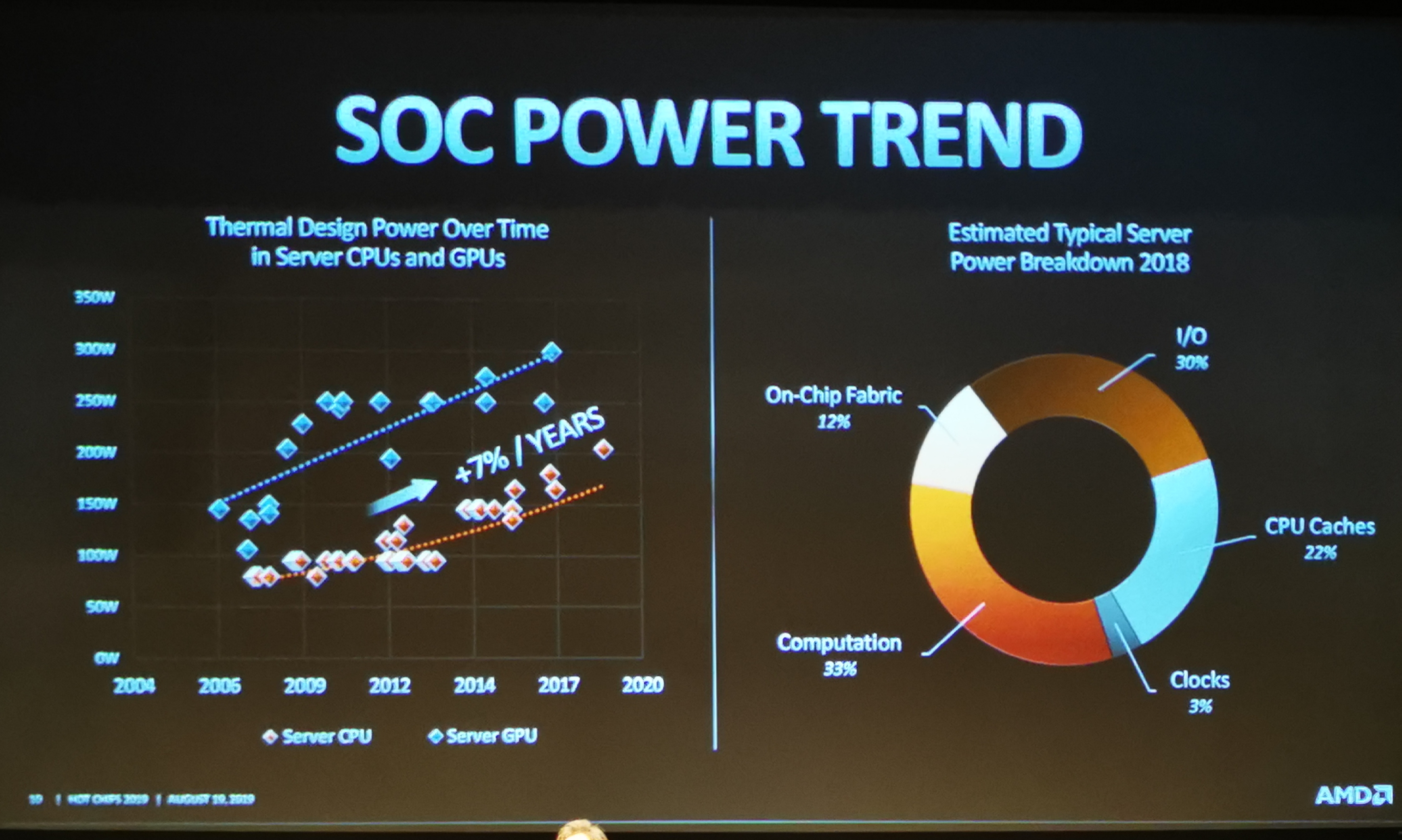
04:56PM EDT - 1/3 overall power on a chip is compute - the rest is die/data/IO
04:56PM EDT - Scaling has changed
04:57PM EDT - Reaching reticle limit of die sizes
04:57PM EDT - Large die sizes are not that efficient for yields and costs
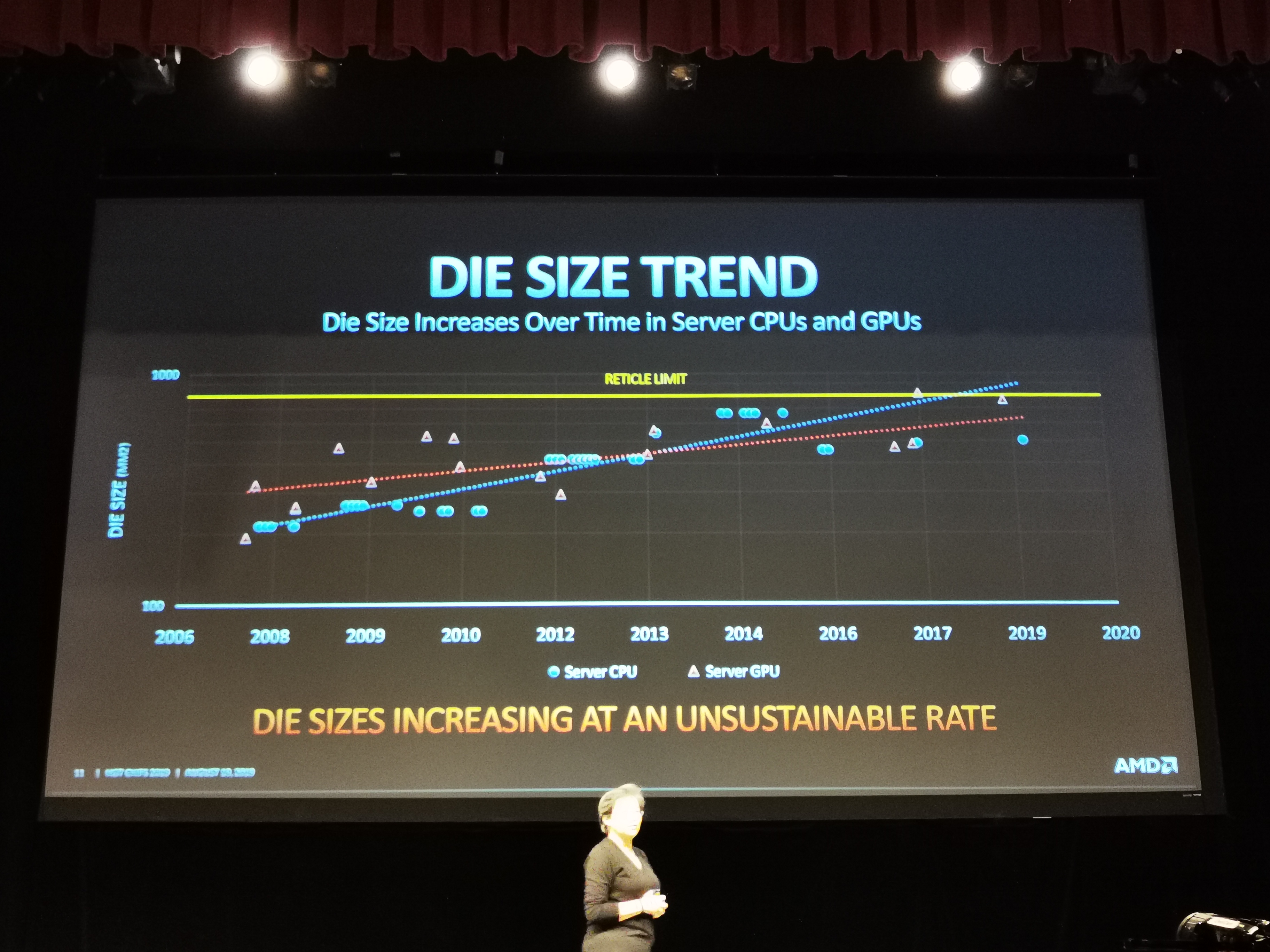
04:57PM EDT - The last 10 years of die size increases will slow down
04:59PM EDT - Ecosystem has to work together
04:59PM EDT - New approaches needed to solve these solutions
04:59PM EDT - AMD can bring the best of the ecosystem together in terms of silicon and software to maintain the trends around high perf computing

04:59PM EDT - Silicon advances
05:00PM EDT - AMD has being going above the industry trend in IPC

05:00PM EDT - AMD's goal is to stay above the industry trend line
05:01PM EDT - Every generation there is low hanging fruit to optimize for. We always do this

05:02PM EDT - 2nd Gen EPYC has 15-23% IPC uplift
05:02PM EDT - Better CPU, better bandwidth, better interconnect bandwidths, help MT workloads in different ways to ST workloads
05:02PM EDT - Also, multi-chip architectures
05:03PM EDT - You can keep doing monolithic chips, but you end up being limited on performance
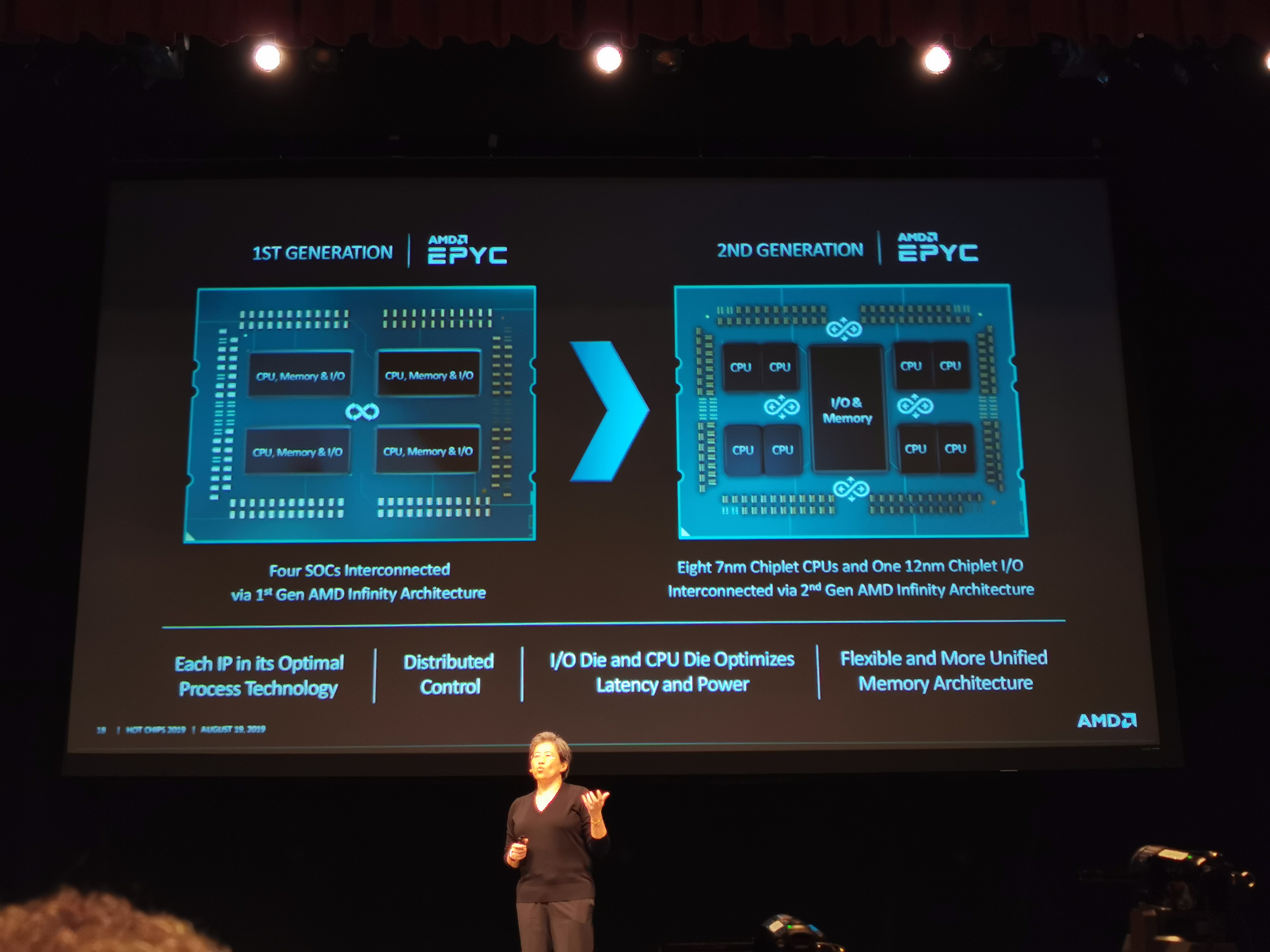
05:03PM EDT - More performance at a lower cost point from a multi-chip design. Smaller die, higher yields, better binning
05:04PM EDT - Optimizing the right transistor for the right technology
05:04PM EDT - Logic was the most valuable, done in 7nm, but the IO/mem which didn't scale as well, were done in 12nm
05:04PM EDT - Each IP is in its optimal process technology
05:04PM EDT - Gives plenty of flexibility
05:05PM EDT - "You will see this in high performance workstations"
05:05PM EDT - = Threadripper !
05:06PM EDT - System Advances
05:07PM EDT - The mroe you know about the application, the better you can optimize the system and silicon
05:07PM EDT - The whole system has to be optimized. CPUs, GPUs, FPGA/Accelerators, High Speed Interconnects

05:07PM EDT - Pick the best compute for the best application
05:08PM EDT - Each workload has different ratios of CPU/GPU
05:08PM EDT - All of it still needs to connect properly, no matter the ratio
05:08PM EDT - You need the right interconnect
05:08PM EDT - Requires innovation
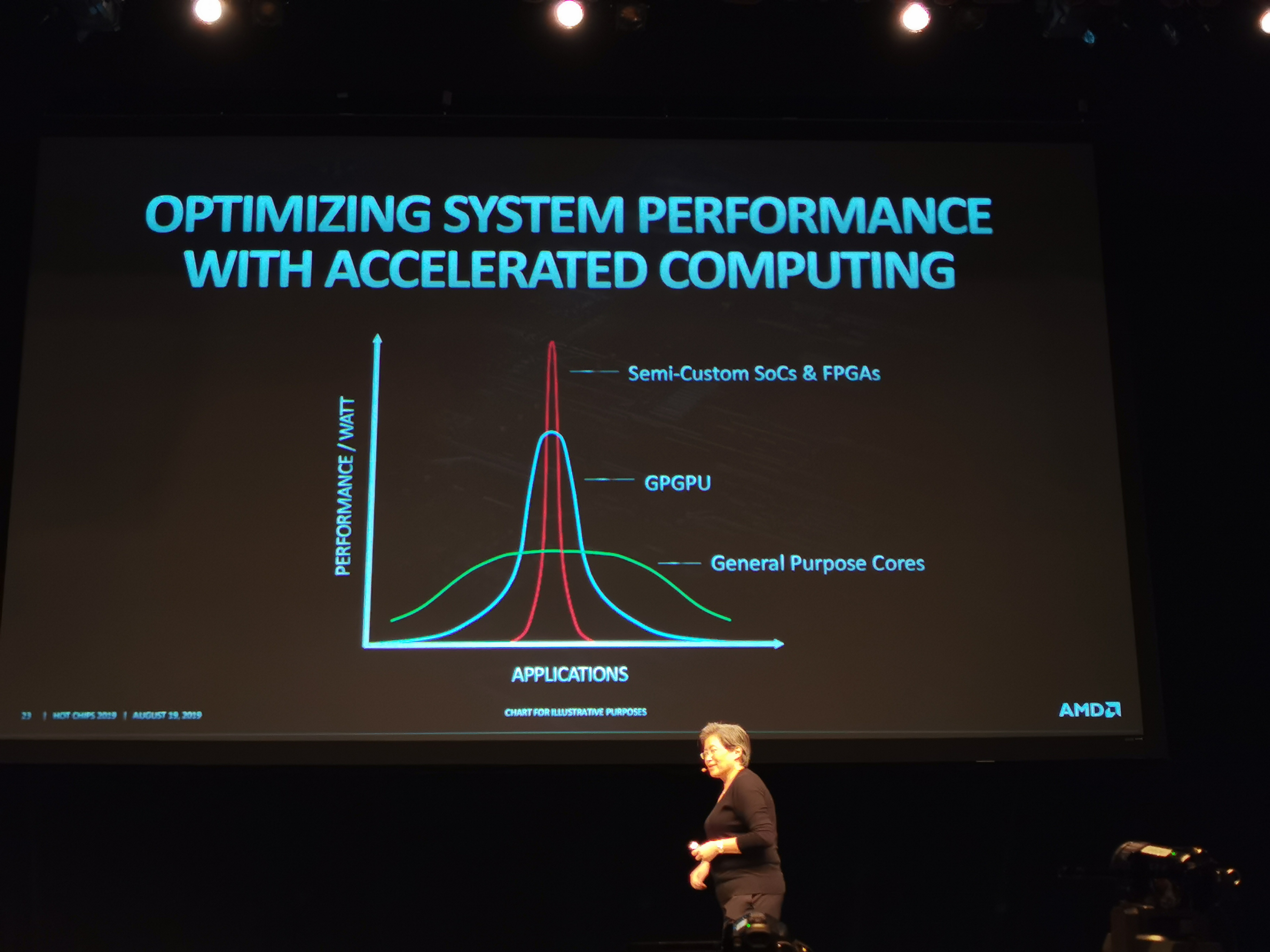
05:09PM EDT - Optimize for the problem based on the hardware
05:10PM EDT - Connecting GPUs with IF
05:10PM EDT - CPU to GPU is PCIe 4.0
05:10PM EDT - These are the elements of an accelerated platform

05:11PM EDT - System needs to be as programmable as possible to get the most out of the silicon
05:11PM EDT - Scale up and Scale out with hardware, and AMD believes in an open source environment on the software

05:12PM EDT - Hardware and Software co-optimization to get the best performance
05:12PM EDT - Workloads of the Future
05:13PM EDT - Supercomputers are the best manifestation of all these technologies
05:13PM EDT - How to push the envelope with computing to enable a solution to a series of problems
05:13PM EDT - A recent explosion of HPC
05:13PM EDT - Commercial applications and Consumer Applications
05:14PM EDT - Traditional HPC and new Machine Learning methods are being mixed very quickly because they share many of the same compute requirement characteristics
05:14PM EDT - Problems that lend themselves to parallelism

05:15PM EDT - Newer problems are requiring much more compute
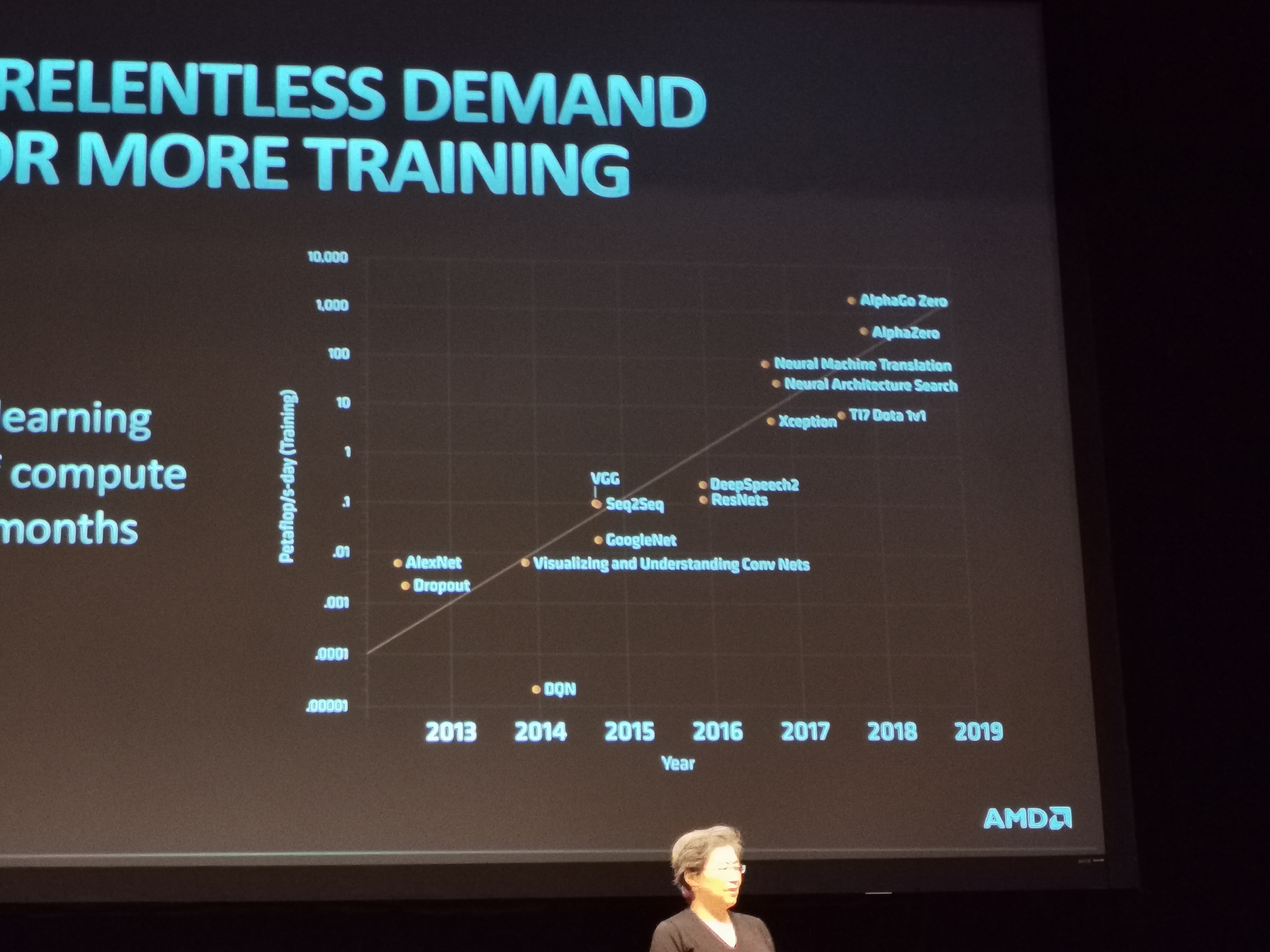
05:15PM EDT - For the most advanced algorithms, doubling of compute requirements every 3-4 months (Intel says the same)
05:16PM EDT - You either optimize for efficiency, or build out the compute. In reality, you do a bit of both
05:16PM EDT - Normal TOP500 top supercomputer is faster than general compute: 2x every 1.2 years.#
05:17PM EDT - But recently, the rate of progress is slowing
05:17PM EDT - Top machine in the TOP500 list in last 8 years hasn't grown as fast
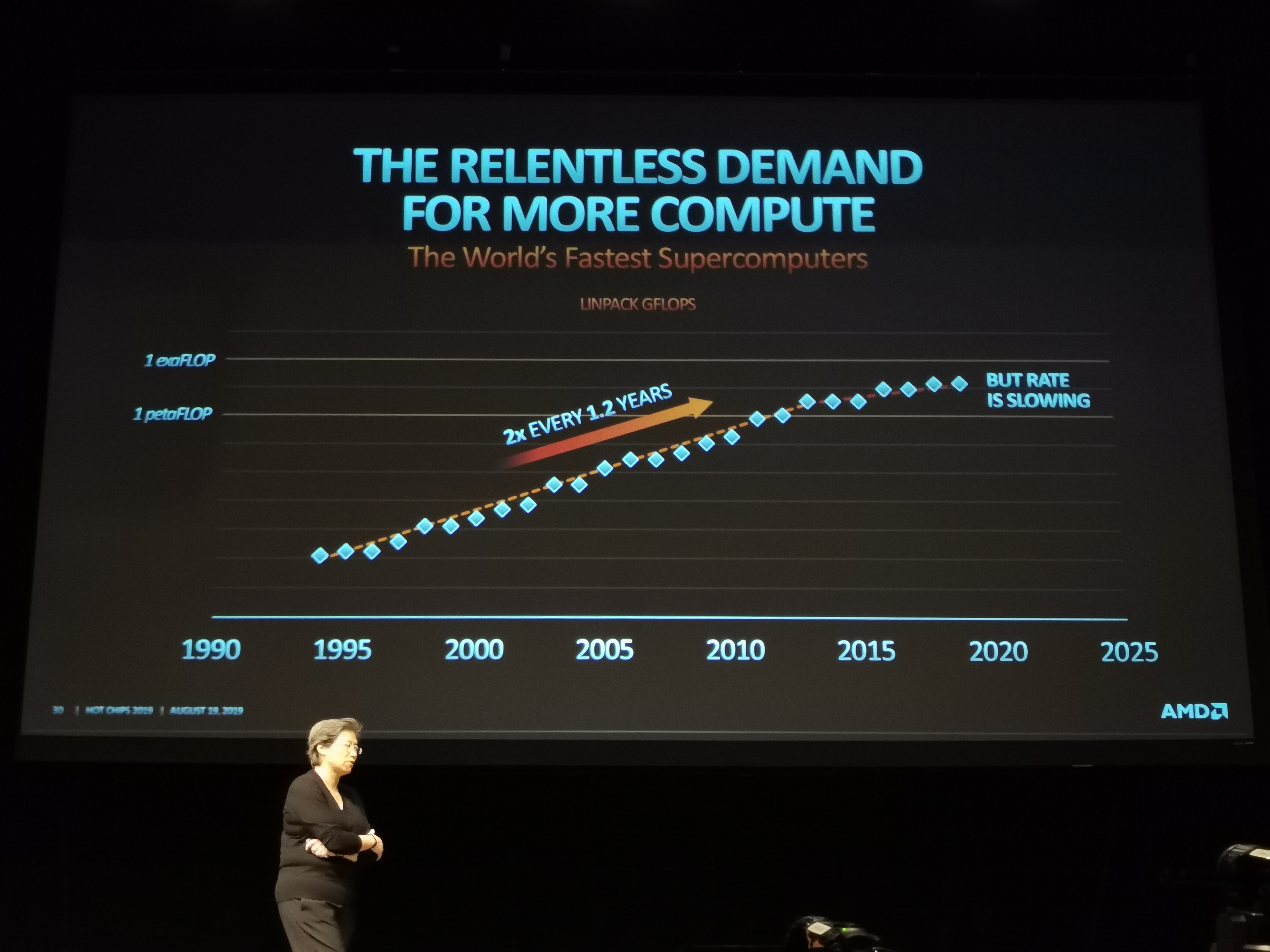
05:17PM EDT - AMD's goal is to use significant innovation to get that curve back on track
05:18PM EDT - Example of HPC workload with 4 GPUs
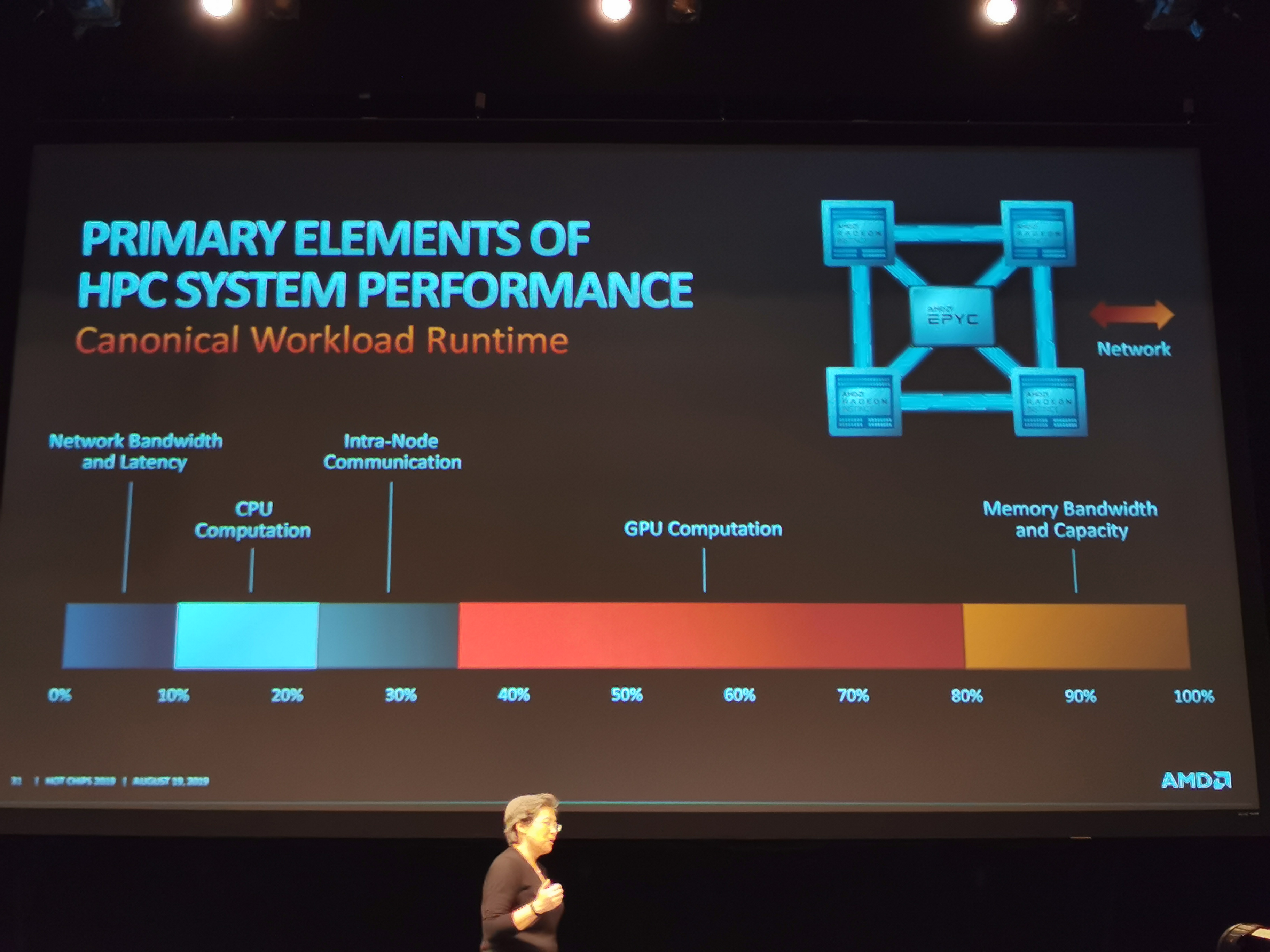
05:19PM EDT - Differnet workloads have different requirements
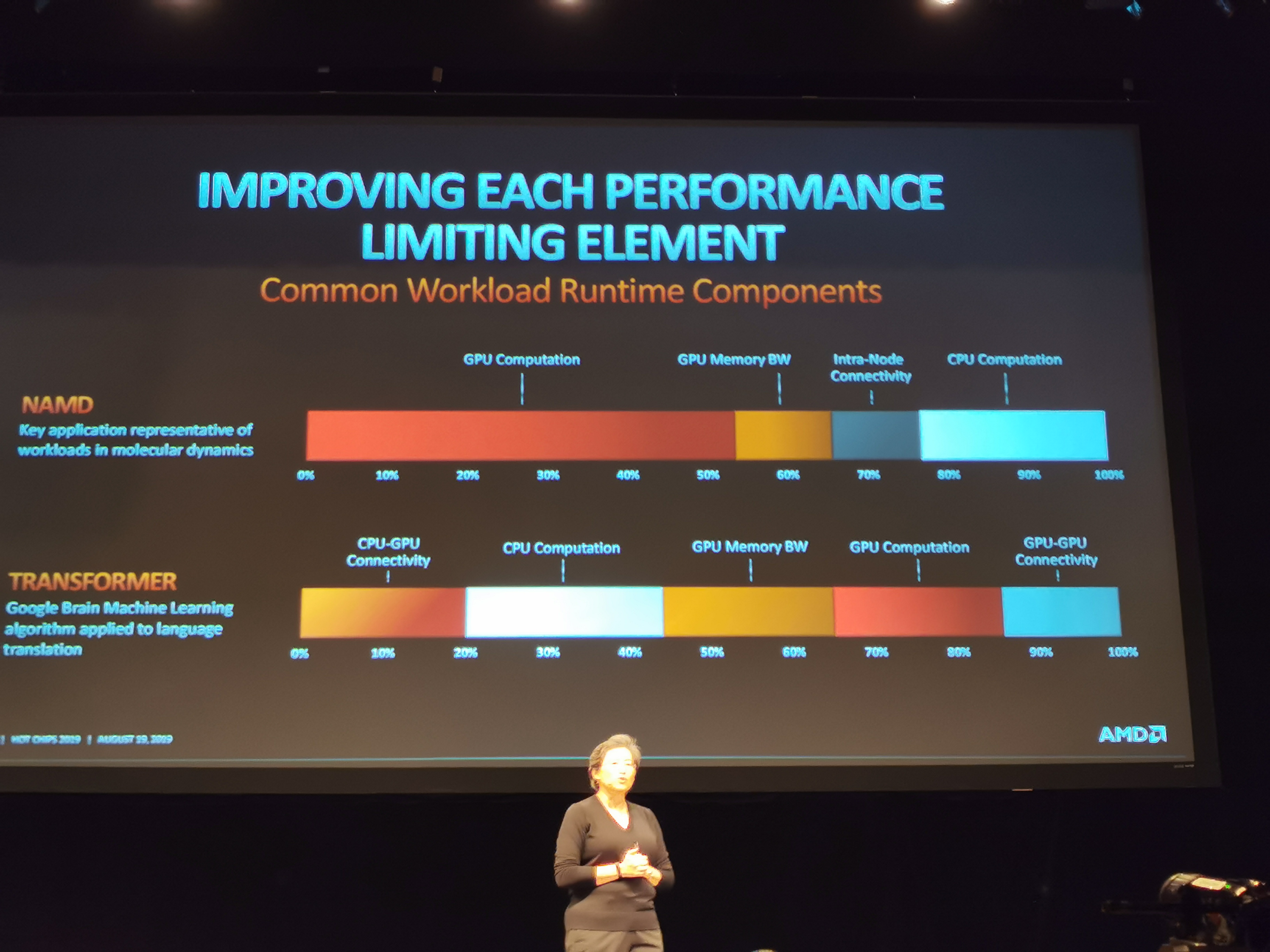
05:19PM EDT - NAMD is GPU accelerated. Transformer (natural language processing) is more balanced between CPU/GPU/Interconnect
05:19PM EDT - There's not one way to speed up all of these workloads - old workloads and new workloads
05:20PM EDT - Not only compute, but memory and connectivity
05:20PM EDT - Matrix math on GPUs
05:20PM EDT - Improvement in GPU FLOPS/Watt

05:20PM EDT - That's going to continue to be innovated upon
05:21PM EDT - Connectivity is also increasing, but not as fast as CPU compute
05:21PM EDT - This needs more work

05:21PM EDT - Connectivity to accelerators is a hot topic
05:22PM EDT - Memory bandwidth is also increasing, but memory bw over time isn't quite keeping up
05:22PM EDT - This needs to be improved too
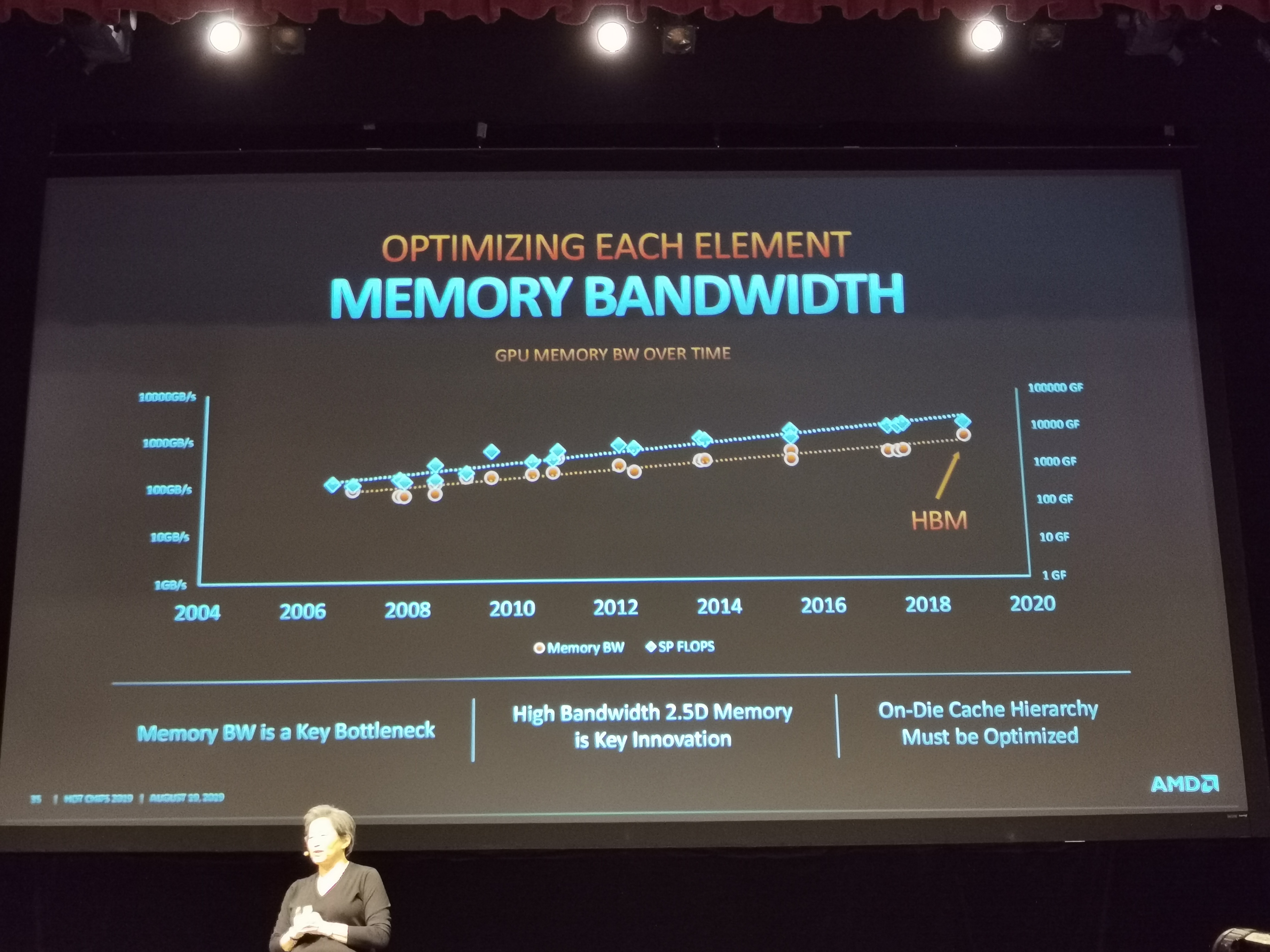
05:22PM EDT - Memory BW is a key bottleneck
05:22PM EDT - 2.5D HBM is a key innovation
05:22PM EDT - on-die cache hierarchy must be optimized on GPUs
05:22PM EDT - Other integration methods will help extend this memory BW curve over time
05:23PM EDT - Powering the exascale era
05:23PM EDT - Frontier will have EPYC CPUs and Radeon Instinct GPUs to deliver >1.5 exaflops

05:23PM EDT - Highly optimized CPU, GPU, interconnect
05:23PM EDT - working with Cray for node-to-node
05:23PM EDT - Creating a leadership system
05:24PM EDT - Important for traditional HPC applications as well as AI and ML
05:24PM EDT - Coming 2021
05:24PM EDT - Frontier will change the TOP500 curve
05:25PM EDT - How to push the envelope in computing on every element of the HPC system
05:25PM EDT - These technologies might be designed for the high end HPC systems, these technologies filter down to commercial systems and next gen CPU/GPU
05:25PM EDT - Computational efficiency has a knock on effect
05:25PM EDT - High Performance Computing is one of the most exciting areas of the market today
05:26PM EDT - Working on foundational IP elements
05:26PM EDT - CPU/GPU
05:26PM EDT - Working on interconnects, system optimization, software

05:26PM EDT - If we know what the application is doing, can develop better silicon
05:26PM EDT - Exponential curves look nice, and there are plenty of smart people in the industry to keep pushing
05:27PM EDT - Q&A time with Lisa
05:29PM EDT - Q: What is the next step for AMD against things like the TPU in AI? A: There is tremendous innovation in the industry. Lots of companies doing purpose built ASICs for specific applications. Over time, these things will narrow. Lots of lots new ideas, and the ideas that are most sustainable will shine through. AMD's goal is to optimize each element. That includes CPU/GPu/Interconnect. That may include purpose built accelerators. But what is important to AMD is to connect the ecosystem together, connect to AMD's CPUs and GPUs. We believe not any one company will have the best ideas. The more we can drive standards, the better we will be for AI.
05:30PM EDT - Q: Any plans for any speicfic AI accelerators? A: You will see as a large player in AI. Our desire to pick the winning solution - there will be many solutions - the importance is that we're putting more and more purpose built accelerators on our silicon as part as that. Whether we do our own accelerators will depend how the industry evolves. But the CPU/GPU/interconnect strategy is to move forward.
05:32PM EDT - Q: Do you see thermal as a limit? A: Yes, for sure. Thermal is a big driver. If you look at the amount of power management that our newer generation of processors do, the sophistication of our algorithms, all of that is really important. We also look how to best thermal characteristic across the chip as uniform as possible. No question that this is a huge part of the optimization, we tend to believe there are some limitations, but a tremendous amount of sophistication on these processors and every square mm is optimized.
05:34PM EDT - Q: Neural computing, quantum computing. Do you see this time of paradigm will also recreate the RISC vs CISC argument? A: I think we can all say we have at least a 30 year job, so I'm not worried :) Quantum computing is very interesting, and who will get there first. We're still at the early stages of these focused problem architectures, unlikely one will become the next general purpose architectures. There is so much energy today about optimizing general prupose compute, and these things have to intercept at some point, but it's still very early in that time frame.
05:35PM EDT - Q: GPu-to-GPU comms? Is Crossfire coming back? A: We love gamers and we always talk about gamers. I would say that GPU performance will continue to go forward at a fast pace. To be honest, the software is going faster than the hardware, I would say that Crossfire isn't a significant focus. GPUs can do a lot in the consumer space.
05:40PM EDT - Q: How is AMD approaching the workstation market? How does that pertain to threadripper? A: We love the workstation market, and yes there will be a next generation of Threadripper. Q: Can you say when? A: If I said soon, is that enough? Q: No? A: How about within a year? Q: Can you say if 2019? A: How about this - you will hear more about Threadripper in 2019.
05:46PM EDT - That's a wrap!








20 Comments
View All Comments