Next Generation Intel Atom Tremont: Potential L3 Cache
by Dr. Ian Cutress on July 15, 2019 8:00 AM EST
Intel has already disclosed that it will have a next generation Atom core, code named Tremont, which is to appear in products such as the Foveros-based hybrid Lakefield, as well as Snow Ridge designed for 5G deployments. In advance of the launch of the core and the product, it is customary for some documentation and tools to be updated to prepare for it; in this case, one of those updates has disclosed that the Tremont core would contain an L3 cache – a first for one of Intel’s Atom designs.

01.org is an Intel website which hosts all of its open source projects. One of those projects is perfmon, a simple performance monitoring tool that can be used by developers to direct where code may be bottlenecked by either throughput, memory latency, memory bandwidth, TLBs, port allocation, or cache hits/misses. In this case, the profiles for Snow Ridge have been uploaded to the platform, and one of the counters provided includes provisions for L3 cache monitoring. This provision is directly listed under the Tremont heading.

Enabling an L3 cache on Atom does two potential things to Intel’s design: it adds power, but also adds performance. By having an L3, it means that data in the L3 is quicker to access than it would be in memory, however there is an idle power hit by having L3 present. Intel can mitigate this by enabling parts of the L3 to be powered on as needed, but there is always a tradeoff. There can also be a hit to die area, so it will be interesting to see how Intel has changed the microarchitecture of it’s Atom design. There is also no indication if the Tremont L3 cache is an inclusive cache, or a non-inclusive cache, or if it can be pre-fetched into, or if it is shared between cores or done on a per-core basis.
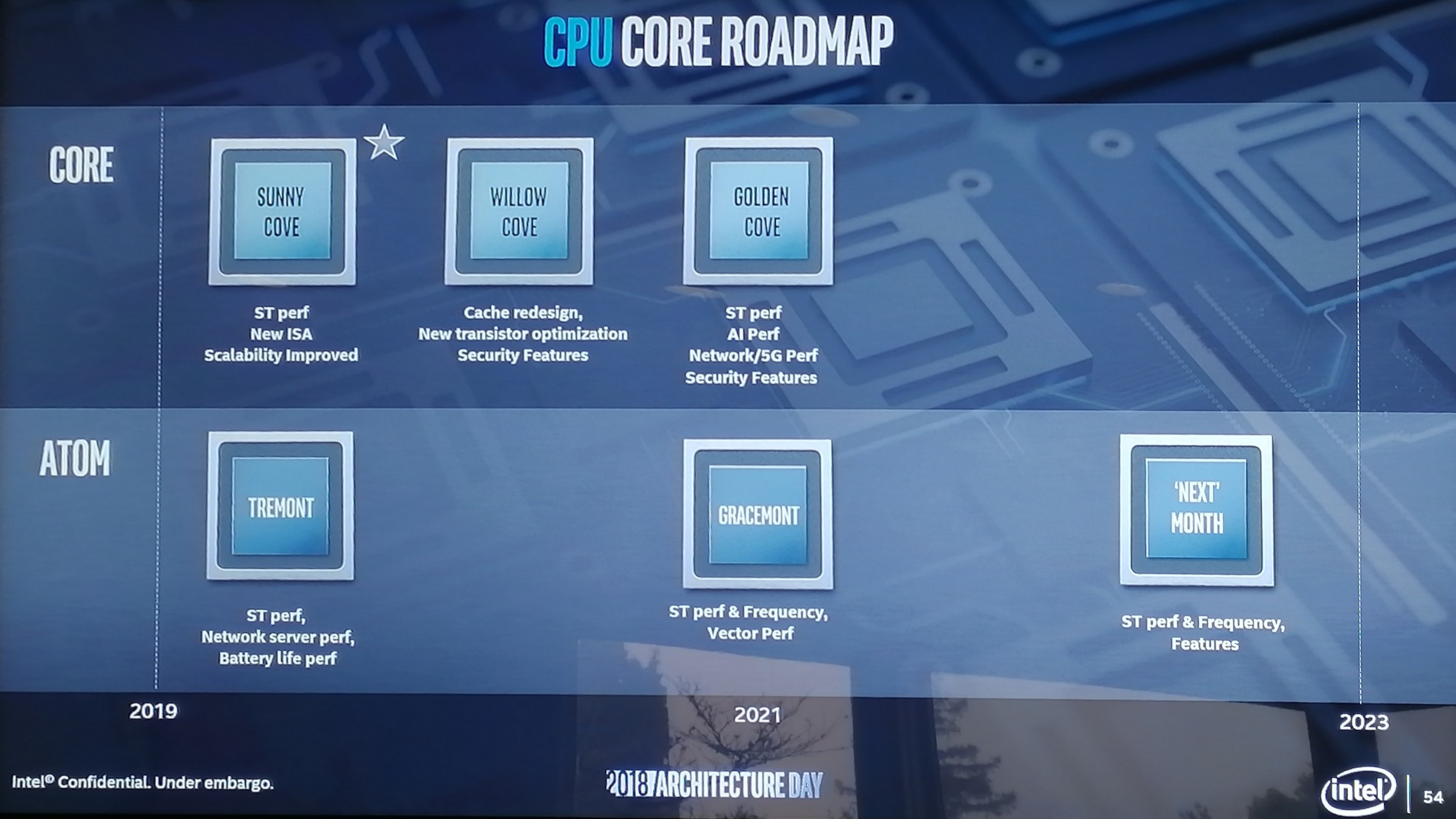
Intel’s Atom roadmap, as disclosed last year at Architecture day, shows that the company is planning several more generations of Atom core, although beyond Tremont we get Gracemont in 2021, and beyond that is ‘increased ST Perf, Frequency, Features’ listed around 2023. In that time, Intel expects to launch Sunny Cove, Willow Cove, and Golden Cove on the Core side.

Lakefield
The first public device with Tremont inside is expected to be the Core/Atom hybrid Lakefield processor, which uses Intel’s new Foveros stacking technology. We know that this design will have one Sunny Cove core and pair it with four Tremont cores. Intel expects chip production of Lakefield for consumer use by the end of the year.
Related Reading
- Intel's Architecture Day 2018: The Future of Core, Intel GPUs, 10nm, and Hybrid x86
- Intel Lists New Atom Core: Tremont to Come After Goldmont Plus
- Intel’s Keynote at CES 2019: 10nm, Ice Lake, Lakefield, Snow Ridge, Cascade Lake
- Intel's Interconnected Future: Combining Chiplets, EMIB, and Foveros
Source: InstLatX64, 01.org








66 Comments
View All Comments
name99 - Monday, July 15, 2019 - link
big.LITTLE is not just yet cores, it was a very specific IMPLEMENTATION of that idea. And it wasn’t a great implementation. Which is why even ARM has ditched it, replaced with DynamIQ...You’ll get more out of tech sites if you distinguish
- the commenters who know what they are talking about from the idiots
- exactly WHAT is being criticized when (knowledgeable) commenters criticize something. Knowledgeable criticism usually accepts some aspect of an idea is valuable, while also pointing out other parts that are problematic.
Jorgp2 - Monday, July 15, 2019 - link
I feel like low power cores are more exciting in general, since you have to balance performance with power.mode_13h - Monday, July 15, 2019 - link
No, please leave the cats dead and buried!If Intel adds AVX to their atom cores (as the slides suggest they will), I wonder how much area advantage they'll still hold over Zen. If it's only like a factor of 2, then I'd rather have one Zen2 cores with HT than 2 Atom-derived cores.
IntelUser2000 - Tuesday, July 16, 2019 - link
Big.Little like setups have existed as an idea for future compute in academia for a long time.It was actually the former head of Intel Labs, Justin Rattner, that showed the idea to the public back in 2005. It was called "Platform 2015".
Had 10nm not been so ambitious(they go as far as admit this in their recent presentation) we might have really seen such setups in 2015-2016.
konbala - Monday, July 15, 2019 - link
ARM's x86 emulation is so good now it is ridiculous, can the new nano lineup beat it? Its efficiency gonna be life or death determining for x86 I think.HStewart - Monday, July 15, 2019 - link
I thought for second this was April 1st, this sounds like a April Fools joke believing x86 emulation.mode_13h - Monday, July 15, 2019 - link
Emulation done right is like just-in-time recompilation. There's always a performance penalty vs. fully recompiled code, but it can get pretty close.HStewart - Monday, July 15, 2019 - link
Big difference between ARM and x86 based cpu is simple RISC vs CISC which by definition means more RISC instructions are required for single CISC instruction. But fortunately for most applications is they are likely a simple set of instructions. They might be ok for most application but more complex application uses higher level instructions. I am curious if application designed to work with AVX or higher other instruction. I would think anything that uses Machine language would have difficultly. But like something with .NET could be made portable in both architexture quite easy. In fact a .NET interpreted library could made in native ARM,Wilco1 - Tuesday, July 16, 2019 - link
.NET already compiles to native Arm of course! It's only old x86 applications that need translation. And the performance of the translated code is not all that important for Windows applications which spend much of their time in native Windows libraries.Microsoft demonstrated good Windows performance on a 2 year old Arm SoC (https://www.youtube.com/watch?v=PaSmZzo3Y_c), and performance has doubled since then. Cortex-A77 will be out in a few months and is about 3 times faster. Emulation is more than fast enough.
Zoolook13 - Friday, July 19, 2019 - link
Emulation done right is keeping the recompiled native binaries, speeding up the application the more you run it until it's completely native, like DEC's FX!32.A similar approach with todays compiler technology and processing power and largely similar dev librarys on many platforms could yield you close to native speed at the cost of a larger storage footprint, but the compiled code part of an application is much less today, GUI resources etc is a much larger part of the footprint today than back then.