Examining Intel's Ice Lake Processors: Taking a Bite of the Sunny Cove Microarchitecture
by Dr. Ian Cutress on July 30, 2019 9:30 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Microarchitecture
- Ice Lake
- Project Athena
- Sunny Cove
- Gen11
Sunny Cove Microarchitecture: Going Deeper and Wider
Ice Lake falls under Intel’s ‘10th Gen Core’ family, and is based around the latest iteration of the ‘Core’ microarchitecture, which initially debuted over a decade ago and has received plenty of key critical enhancements and extra features along the way. Over the years we’ve seen improved prefetchers, smarter branch predictors, adjusted cache sizes and capabilities, deeper and wider execution, micro-op caches, accelerated calculation logic, and lower power operation, all designed to increase the instruction throughput, decrease cache misses, and improve power efficiency.
When Intel designs a new generation of Core, it tends to go in a lot of things: mobile CPUs, desktops, servers, sometimes embedded, new communications technologies, and plenty of other custom silicon besides. As a result, it has to scale, from low-end to high-end. One of Intel’s new Chief Architects, Jim Keller, says that Intel has a ‘milliwatt-to-megawatt’ strategy when it comes to product design, and it’s the Core microarchitecture that is currently bringing in the big $$$ to fund a lot of the R&D.
Before we go into the new Sunny Cove core, I should preface the explanations with a little warning. Intel’s previous microarchitecture update and design, Skylake, is Intel’s most profitable design ever. Part of that reason is that it has been around the block for four generations of products. Intel hasn’t changed the core in that time, for almost four years. At this point, we’ve been yearning for something that actually has changes. So please forgive a little excitement when covering a few of the more mundane updates.
Sunny Cove Front End
Despite the instruction entry point into the core being at the front-end. Intel didn’t say too much about Sunny Cove in this respect. Typically Intel keeps the details of its prefetchers and branch predictors secret, although CPU Architect Ronak Singhal did state that it is by-and-large similar to the Skylake design. Ronak has said that the branch predictor has increased accuracy, and that the average/effective load latency has decreased, and by and large the front-end of the CPU has been optimized for client (read consumers/end-users), rather than servers, which Skylake was. The internal structures of the branch predictor unit and prefetcher are larger according to Intel, which should help improve accuracy.
The L1 instruction cache is still a 32 KiB 8-way design, and there are still five decoders in play. These decoders are split as one complex decoder and four simple decoders, and they can supply up to five micro-ops per cycle. There’s nothing drastically new in terms of op fusion we are told, just the general expected improvements, plus additional support for the new AVX-512 instructions.

The micro-op cache gets an update here, from 1.5k entries to 2.25k entries. This is the first time that Intel has increased the micro-op cache size since Haswell, but it should be noted that the competition also has micro-op caches (ARM has 1.5k, AMD has 2k for Zen, 4k for Zen 2), and so refinement in this area is going to be critical. The micro-op cache can supply six micro-ops to the queue per cycle.
Overall, six micro-ops can be fed between the decoders/cache/direct micro-code per cycle. That is split between up to six per cycle from the cache, up to 5 from the decoders, and up to 4 from direct microcode (which gets fed through the complex decoder.
Out-of-Order Window
The micro-op queue, for rename/allocate/retire, has also increased. The design went from 182 micro-ops in Haswell to 224 in Skylake, but goes all the way up to 352 in Sunny Cove, a massive 57% increase. This will help managing which instructions are ready to be processed by the scheduler, although this often comes at the penalty of power. This is one of the advantages of using a smaller process node – there’s more power budget to go around, allowing a CPU team to design bigger queues.
| AnandTech | Haswell | Skylake | Sunny Cove |
| Reorder Buffer | 182 | 224 | 352 |
| In-Flight Stores | 72 | 72 | 128 |
| In-Flight Loads | 42 | 56 | 72 |
With the increased queue size, Intel also reports that support for in-flight loads and stores has increased: up from 72 loads in Skylake to 128 in Sunny Cove, and up from 56 stores in Skylake to 72 in Sunny Cove. This means that the in-flight load/store ratio is more weighted in favor of loads, which Intel states is part of the more user-focused design where loads end up being more important than stores.
Back End
This is where the fun happens. As with previous Intel designs over the years, we still have a unified scheduler for both integer and vector operations, however they are split between four different reservation stations depending on what operation is needed:
- One for four ALU ports, accepts 4 micro-ops/cycle
- One for two Store ports, accepts 2 micro-ops/cycle
- One for a pair of AGUs, one load, one store, accepts 2 micro-ops/cycle
- One for a pair of AGUs, one load, one store, accepts 2 micro-ops/cycle
In total, the number of execution ports has increased from 8 in Skylake to 10 in Sunny Cove. This allows for 10 micro-ops per cycle to be dispatched from the reorder buffer, a 25% increase. The two new ports lie in different areas: Skylake had 3 AGUs, supporting two loads and one store per cycle, but Sunny Cove now has 4 AGUs, for two loads and two stores per cycle. The other new port is a store data port. With these changes, the L1 data cache can now support two stores per cycle, effectively doubling the L1 store bandwidth.
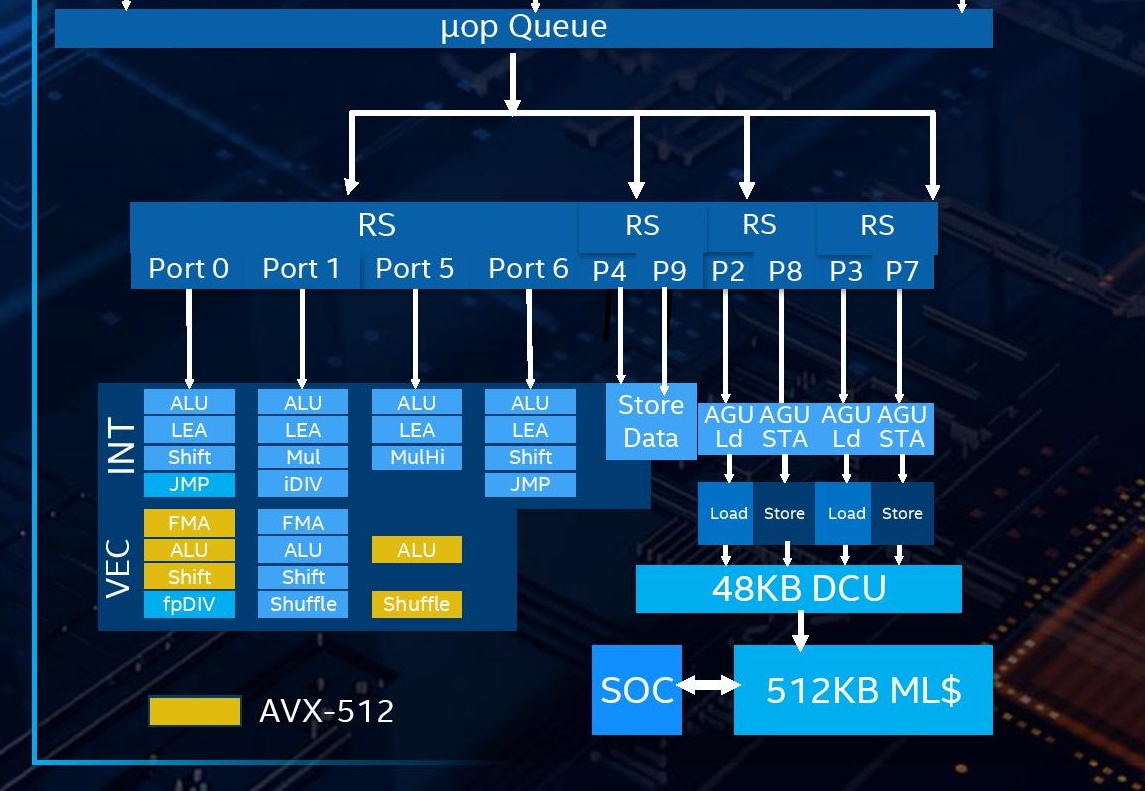
The L1 Data cache has increased, for the first time in over a decade. Intel has moved from a 32 KiB 8-way design up to a 48 KiB 12-way design, which should help reduce data cache misses significantly. This combined with the micro-op cache size increase is one of the easiest ways to reduce cache miss penalties. (For comparison, in Zen 2 AMD halved its L1-I size and doubled its micro-op cache, which it felt was a more efficient way of improving instruction throughput, but also the silicon area design had to be managed.)
Intel has also increased the L2 cache, up from 256 KiB to 512 KiB, and it is still non-inclusive of the L1 with a write-back policy. In order to assist the L2, the L2 TLB page table arrangement has also been improved, with up to 2k entries at 4K, 1k entries for 2M/4M (new, used to be shared with 4K), and up from 16 entries to 1024 entries at 1G. The cache improvements on Sunny Cove are certainly expected to work in Intel’s favor, especially when it comes to the enhanced graphics part of the design.
On a core-to-core level, Intel's recent designs have the following configurations:
| Microarchitecture Comparison | ||||||
| Skylake | Cannon Lake | Sunny Cove* | Zen | Zen 2 | ||
| L1-D Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
48 KiB/core 12-way |
32 KiB/core 8-way |
32 KiB/core 8-way |
|
| L1-I Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
32 KiB/core 8-way |
64 KiB/core 4-way |
32 KiB/core 8-way |
|
| L2 Cache |
256 KiB/core 4-way |
256 KiB/core 4-way |
512 KiB/core 8-way |
512 KiB/core 8-way |
512 KiB/core 8-way |
|
| L3 Cache |
2 MiB/core 16-way |
2 MiB/core 16-way |
2 MiB/core 16-way |
2 MiB/core | 4 MiB/core | |
| L3 Cache Type | Inclusive | Inclusive | Inclusive | Non-Inclusive | Non-Inclusive | |
| Decode | 4 + 1 | 4 + 1 | 4 + 1 | 4 | 4 | |
| uOP Cache | 1.5k | 1.5k | 2.25k | 2k | 4k | |
| Reorder Buffer | 224 | 224 | 352 | 192 | 224 | |
| Execution Ports | 8 | 8 | 10 | 10 | 11 | |
| AGUs | 2 + 1 | 2 + 1 | 2 + 2 | 1 + 1 | 2 + 1 | |
| AVX-512 | - | 1 x FMA | 1 x FMA | - | ||
| * Sunny Cove numbers for Client. Server will have different L2/L3 cache and FMA, like Skylake | ||||||
For the execution ports, now that Intel has moved AVX-512 into the mainstream Core design, there are a few changes. AVX-512 is now supported on Port 0 (FMA, ALU, Shift) and Port 5 (ALU, Shuffle). There is only one AVX-512 port, but also a 256-bit FMA port, so either 1x512-bit or 2x256-bit throughput is possible.
Overall the design allows for:
| Back-End Execution Resources | ||||||||
| Skylake | Port | Sunny Cove | ||||||
| Integer | ||||||||
| JMP | Shift | ALU | 0 | ALU | LEA | Shift | JMP | |
| LEA | ALU | 1 | ALU | LEA | Mul | iDIV | ||
| Mul | LEA | ALU | 5 | ALU | LEA | MulHi | ||
| JMP | Shift | ALU | 6 | ALU | LEA | Shift | JMP | |
| Vector / FP | ||||||||
| fpDIV | Shift | ALU | FMA | 0 | FMA | ALU | Shift | fpDIV |
| Shift | ALU | FMA | 1 | FMA | ALU | Shift | Shuffle | |
| Shuffle | ALU | FMA | 5 | FMA | ALU | Shuffle | ||
The parts highlighted in bold are different in the Sunny Cove core.
The TL;DR
The core improvements can be summed up as follows:
- Better prefetchers and branch predictors
- +50% L1 Data Cache
- +100% L1 Store Bandwidth
- +100% L2 Cache w/improved L2 TLB
- +50% Micro-op Cache
- +25% uops/cycle into reorder buffer
- +57% reorder buffer size
- +25% execution ports
- AVX-512 with VNNI
Add in better memory support (Up to LPDDR4X-3733) and better graphics (64 EUs of Gen11), and it’s a really nice update.
For all of this, Intel is promoting a +18% IPC increase over Skylake, which ranges from 0.98x to 1.40x depending on the workload (SPEC2006, SPEC2017, SYSMark 2014SE, WebXPRT, CineBench), or a +47% increase in real world tasks against Broadwell.

When AVX512 is in play, with DLBoost, Intel is promoting a 2.0x-2.5x increase against the best Whiskey Lake has to offer.
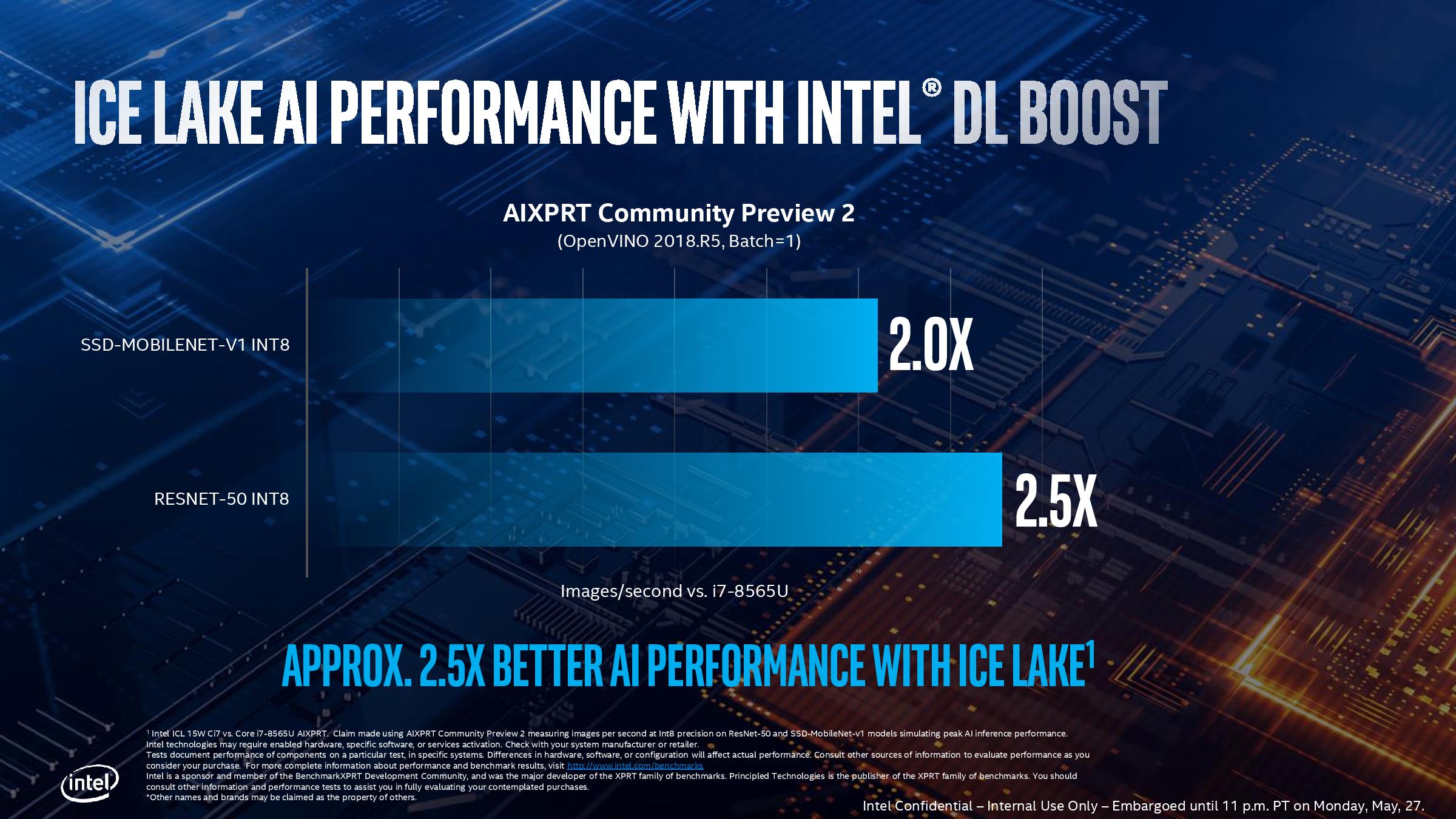
We’ll cover Intel’s claims later in the analysis.








107 Comments
View All Comments
vFunct - Tuesday, July 30, 2019 - link
Why did they not go with HDMI 2.1 and PCIe 4.0?bug77 - Tuesday, July 30, 2019 - link
AMD'd newly released 5700(XT) doesn't support HDMI 2.1, it's not surprising Intel doesn't support it either.And PCIe 4.0 would be power hog.
ToTTenTranz - Wednesday, July 31, 2019 - link
The 5700 cards don't support VirtuaLink either, despite AMD belonging to the consortium since the beginning like nvidia and the RTX cards having it for about a year.First generation Navi cards are just very, very late.
tipoo - Tuesday, July 30, 2019 - link
PCI-E 4 currently needs chipset fans on desktop parts, the power needed isn't suitable for 15-28W mobile yet.DanNeely - Tuesday, July 30, 2019 - link
Because Intel product releases have been a mess since the 10nm trainwreck began. Icelake was originally supposed to be out a few years ago. I suspect PCIe4 is stuck on whatever upcoming design was supposed to be the 7nm launch part.HDMI 2.1 is probably even farther down the pipeline; NVidia and AMD don't have 2.1 support on their discrete GPUs yet. Intel has historically been a lagging supporter of new standards on their IGPs, so that's probably a few years out.
nathanddrews - Tuesday, July 30, 2019 - link
This whole argument that "real world" benchmarks equate to "most used" is rather dumb anyway. We don't need benchmarks to tell us how much faster Chrome opens Reddit, because the answer is always the same: fast enough to not matter. We need benchmarks at the fringes for those reasons brought up in the room: measuring extremes in single/multi threaded scenarios, power usage, memory speeds; finding weaknesses in hardware and finding flaws in software; and taking a large enough sample to be meaningful across the board.Intel wants to eat its cake and still have it - to be fair - who doesn't? But let's get real, AMD is kicking some major butt right now and Intel has to spin it any way they can. What's funny is that the BEST arguments that I've heard from reviewers to go AMD actually has nothing to do with performance, but rather the Zen platform as a whole in terms of features, upgradeability, and cost.
I say this as a total Intel shill, too. The only AMD systems running in my house right now are game consoles. All my PCs/laptops are Intel.
twotwotwo - Tuesday, July 30, 2019 - link
Interesting to read what Intel suggested some of their arguments in the server space would be: lower TCO like the old Microsoft argument against Linux, and having to revalidate all your stuff to use an AMD platform. Some quotes (from a story in their internal newsletter; the full thing is floating around out there, but couldn't immediately find):https://www.techspot.com/news/80683-intel-internal...
I mean, they'll be fine long term, but trying to change the topic from straightforward bang-for-buck, benchmark results, etc. is an approach you only take in a...certain sort of situation.
eek2121 - Wednesday, July 31, 2019 - link
Unfortunately, your average IT infrastructure guy no longer knows how fast a Xeon Platinum 8168 is vs an AMD EPYC 7601. They just ask OEMs like Dell or HP to sell them a solution. I've even seen cases where faster solutions were replaced with slower solutions because they were more expensive and the numbers looked bigger. It turns out that the numbers that looked bigger were not the numbers that they should have been paying attention to.One company I worked at almost bought a $100,000 (yeah I know, small change, but it was a small company) pre-built system. We, as software developers, talked them into letting us handle it instead. We knew a lot about hardware and as a result? We spent around $15,000 in hardware costs. Yes there were labor costs involved in setting everything up, but it only took about 2 weeks for 4 guys, 2 of which were juniors. Had we gone with the blade system, there would have been extensive training needed, which would have costed about the same in labor. Our solution was fully redundant, a hell of a lot faster (the blade system used hardware that was slower than our solution, and it was also a proprietary system that we would be locked into, so there was an additional service contract that costed $$$ and would have to be signed). During my entire time there, we had very few issues with the solution we built outside the occasional hard drive (2 drives in 4 years IIRC) dying and having to pop it out, pop in a new one, and let the RAID rebuild. Zero downtime. In addition, our wifi solution allowed roaming all over a giant building without dropping the signal. Speeds were lightning fast and QoS allowed us to keep someone from taking up too much bandwidth on the guest network. The entire setup worked like a dream.
We also wanted to use a different setup for the phone system, but they opted to work with a vendor instead. They paid a lot of money for that, and constantly had issues. The administration software was buggy, sometimes the entire system would go down, even adding a user would take down the entire system until things were updated. IIRC after I left they finally switched to the system we wanted to use and had no issues after that.
wrkingclass_hero - Tuesday, July 30, 2019 - link
Uh, I would not be putting cobalt anywhere near my mouthPeachNCream - Tuesday, July 30, 2019 - link
Real men aren't scared of a few toxic chemicals entering their digestive systems! Clearly you and I are not real men, but we now have a role model to emulate over the course of our soon-to-be-shortened-by-cancer lives.