Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTNVIDIA’s Answer: RAPIDS Bring GPUs to More Than CNNs
NVIDIA’s has proven more than once that it can outmaneuver the competition with excellent vision and strategy. NVIDIA understands that getting all neural networks to scale as CNNs is not going to be easy, and that there are a lot of applications out there that are either running on other methods than neural networks, or which are memory intensive rather than compute intensive.
At GTC Europe, NVIDIA launched a new data science platform for enterprise use, built on NVIDIA’s new “RAPIDS” framework. The basic idea is that the GPU acceleration of the data pipeline should not be limited to deep learning.
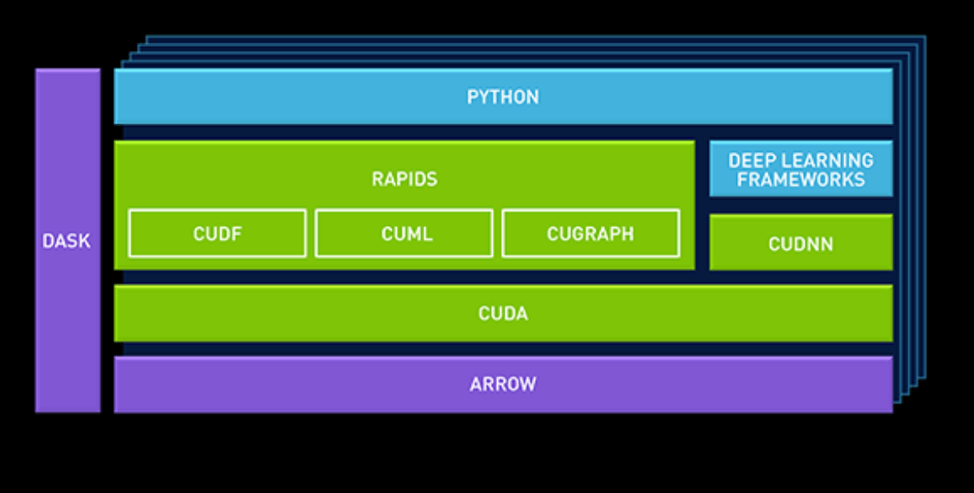
CuDF, for example, allows data scientists to load data into GPU memory and batch process it, similar to Pandas (the python library for manipulating data). cuML is a currently limited collection of GPU-accelerated machine learning libraries. Eventually most (all?) machine learning algorithms available in Scikit-Learn toolkit should be GPU accelerated and available in cuML.
NVIDIA also added Apache Arrow, a columnar in-memory database. This is because GPUs operate on vectors, and as a result favor a columnar layout in memory.
By leveraging Apache arrow as a “central database”, NVIDIA avoids a lot of overhead.
Making sure that there are GPU accelerated versions of the typical Python libraries such as Sci-Kit and Pandas is one step in right direction. But Pandas is only suited for the lighter “data science exploration” tasks. By working with Databricks to make sure that RAPIDS is also used in the heavy duty, distributed “data processing” framework Spark, NVIDIA is taking the next step, breaking out of the "Deep learning mostly" role and towards "NVIDIA in the rest of the data pipeline".
However, the devil is in the details. Adding GPUs to a framework that has been optimized for years to make optimal use of CPU cores and the massive amounts of RAM available in servers is not easy. Spark is built to run on a few tens of powerful server cores, not thousands of wimpy GPU cores. Spark has been optimized to run on clusters of server nodes, making it seem like one big lump of RAM memory and cores. Mixing two kinds of memory – RAM and GPU VRAM – and keeping the distributed compute nature of Spark intact will not be easy.
Secondly, cherry picking the most GPU-friendly machine learning algorithms is one thing, but making sure most of them run fine in GPU-based machine is another thing. Lastly, GPUs will still have less memory than CPUs for the foreseeable future; and even coherent platforms won’t solve the problem that system RAM is a fraction of the speed of local VRAM








56 Comments
View All Comments
C-4 - Monday, July 29, 2019 - link
It's interesting that optimizations did so much for the Intel processors (but relatively less for the AMD ones). Who made these optimizations? How much time was devoted to doing this? How close are the algorithms to being "fully optimized" for the AMD and nVidia chips?quorm - Monday, July 29, 2019 - link
I believe these optimizations largely take advantage of AVX512, and are therefore intel specific, as amd processors do not incorporate this feature.RSAUser - Monday, July 29, 2019 - link
As quorm said, I'd assume it's due to AVX512 optimizations, the next generation of AMD Epyc CPU's should support it, and I am hoping closer to 3GHz clock speeds on the 64 core chips, since it seems the new ceiling is around the 4GHz mark for 16 all-core.It will be an interesting Q3/Q4 for Intel in the server market this year.
SarahKerrigan - Monday, July 29, 2019 - link
Next generation? You mean Rome? Zen2 doesn't have any AVX512.HStewart - Tuesday, July 30, 2019 - link
I believe AMD AVX 2 is dual-128 bit instead of 256bit - so AVX 512 would probably be quad 128bit .jospoortvliet - Tuesday, July 30, 2019 - link
That’s not really how it works, in the sense that you explicitly need to support the new instructions... and amd doesn’t (plan to, as far as we know).Qasar - Tuesday, July 30, 2019 - link
from wikipedia :" AVX2 is now fully supported, with an increase in execution unit width from 128-bit to 256-bit. "
" AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles."
which is from here : https://www.anandtech.com/show/14525/amd-zen-2-mic...
looks like AVX2 is single 256 bit :-)
name99 - Monday, July 29, 2019 - link
Regarding the limits of large batches: while this is true in principle, the maximum size of those batches can be very large, is hard to predict (at leas right now) and there is on-going work to increase the sizes, This link describes some of the issue and what’s known:http://ai.googleblog.com/2019/03/measuring-limits-...
I think Intel would be foolish to pin many hopes on the assumption that batch scaling will soon end the superior performance of GPUs and even more specialized hardware...
brunohassuna - Monday, July 29, 2019 - link
Some information about energy consumption would very useful in comparisons like thatozzuneoj86 - Monday, July 29, 2019 - link
My first thought when clicking this article was how much more visibly-complex CPUs have gotten in the past ~35 years.Compare the bottom of that Xeon to the bottom of a CLCC package 286:
https://en.wikipedia.org/wiki/Intel_80286#/media/F...
And that doesn't even touch the difference internally... 134,000 transistors to 8 million and from 16Mhz to 4,000Mhz. The mind boggles.