Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTApache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large number of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We our newest servers into virtual clusters to make better use of all those core. We run with 8 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on Apache Spark 2.1.1.
Here are the results:
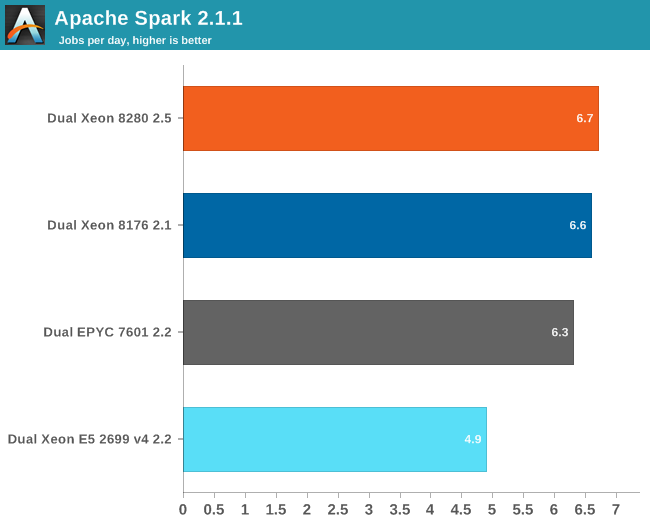
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but it is less than 4% of the total testing time.
For reasons unknown to us, we could get our 2.7 GHz 8280 to perform much better than the 2.1 GHz Xeon 8176. We suspect that the fact that we used the new Xeon chips with an older (Skylake-SP) server could be the reason, as trying different Spark configurations (executors, JVM settings) did not help. A BIOS update did not help us either.
Ok, this was big data processing combined with mostly "traditional" Machine learning: NER and ALS. How about some "deep learning"?








56 Comments
View All Comments
C-4 - Monday, July 29, 2019 - link
It's interesting that optimizations did so much for the Intel processors (but relatively less for the AMD ones). Who made these optimizations? How much time was devoted to doing this? How close are the algorithms to being "fully optimized" for the AMD and nVidia chips?quorm - Monday, July 29, 2019 - link
I believe these optimizations largely take advantage of AVX512, and are therefore intel specific, as amd processors do not incorporate this feature.RSAUser - Monday, July 29, 2019 - link
As quorm said, I'd assume it's due to AVX512 optimizations, the next generation of AMD Epyc CPU's should support it, and I am hoping closer to 3GHz clock speeds on the 64 core chips, since it seems the new ceiling is around the 4GHz mark for 16 all-core.It will be an interesting Q3/Q4 for Intel in the server market this year.
SarahKerrigan - Monday, July 29, 2019 - link
Next generation? You mean Rome? Zen2 doesn't have any AVX512.HStewart - Tuesday, July 30, 2019 - link
I believe AMD AVX 2 is dual-128 bit instead of 256bit - so AVX 512 would probably be quad 128bit .jospoortvliet - Tuesday, July 30, 2019 - link
That’s not really how it works, in the sense that you explicitly need to support the new instructions... and amd doesn’t (plan to, as far as we know).Qasar - Tuesday, July 30, 2019 - link
from wikipedia :" AVX2 is now fully supported, with an increase in execution unit width from 128-bit to 256-bit. "
" AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles."
which is from here : https://www.anandtech.com/show/14525/amd-zen-2-mic...
looks like AVX2 is single 256 bit :-)
name99 - Monday, July 29, 2019 - link
Regarding the limits of large batches: while this is true in principle, the maximum size of those batches can be very large, is hard to predict (at leas right now) and there is on-going work to increase the sizes, This link describes some of the issue and what’s known:http://ai.googleblog.com/2019/03/measuring-limits-...
I think Intel would be foolish to pin many hopes on the assumption that batch scaling will soon end the superior performance of GPUs and even more specialized hardware...
brunohassuna - Monday, July 29, 2019 - link
Some information about energy consumption would very useful in comparisons like thatozzuneoj86 - Monday, July 29, 2019 - link
My first thought when clicking this article was how much more visibly-complex CPUs have gotten in the past ~35 years.Compare the bottom of that Xeon to the bottom of a CLCC package 286:
https://en.wikipedia.org/wiki/Intel_80286#/media/F...
And that doesn't even touch the difference internally... 134,000 transistors to 8 million and from 16Mhz to 4,000Mhz. The mind boggles.