Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTSAP S&D
One last stop before we start with our data analytics/ML benchmarks: SAP. Enterprise Resource Planning software is the perfect example of "traditional" enterprise software.
The SAP S&D 2-Tier benchmark is probably the most real-world benchmark of all the server benchmarks done by the vendors. It is a full-blown application living on top of a heavy relational database.
We analyzed the SAP Benchmark in-depth in one of our earlier articles:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
There are lots of benchmarks result available from different vendors. To get a (more or less) apples-to-apples comparison, we limited ourselves to the "SAPS results" running on top of SQL Server 2012 Enterprise.
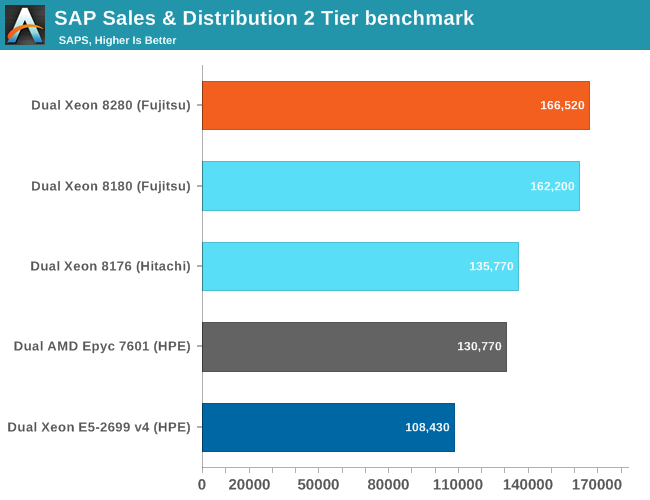
The Fujitsu benchmarks with the Xeon 8180 and 8280-based servers are as apples-to-apples as we can get: the same people who did the testing and tuning, the same OS and database. The slightly higher clocks (+200 Mhz, +8%) result in 3% higher performance. Both CPUs have 28 cores, but the 8280 has an 8% higher clockspeed, and in some senses it’s surprising that this bump in clockspeeds didn’t result in a larger performance increase. We get the impression that Cascade Lake might even be slightly slower clock per clock than Skylake, as both SPEC CPU benchmarks also increased by only three to five percent.
So in the typical enterprise stack, you’re looking at getting around 3% higher performance for the same price/energy consumption. However, AMD's much cheaper (ed: and soon to be updated) $4k EPYC 7601 is not that far behind. Considering that the EPYC is already within a margin of error of the twice as expensive 8176 (2.1 GHz, 28 cores), the 8276 with its slightly higher clockspeed (2.2 Ghz) does not significantly improve matters. Even the Xeon 8164 (26 cores at 2 GHz) offers about the same performance as the EPYC 7601, but still costs 50% more.
Considering how much progress AMD has made with the Zen 2 architecture, and the fact that the top SKUs will double the amount of cores (64 vs 32), it looks like AMD Rome will put even more pressure on Xeon sales.








56 Comments
View All Comments
Bp_968 - Tuesday, July 30, 2019 - link
Oh no, not 8 million, 8 *billion* (for the 8180 xeon), and 19.2 *billion* for the last gen AMD 32 core epyc! I don't think they have released much info on the new epyc yet buy its safe to assume its going to be 36-40 billion! (I dont know how many transistors are used in the I/O controller).And like you said, the connections are crazy! The xeon has a 5903 BGA connection so it doesn't even socket, its soldered to the board.
ozzuneoj86 - Sunday, August 4, 2019 - link
Doh! Thanks for correcting the typo!Yes, 8 BILLION... it's incredible! It's even more difficult to fathom that these things, with billions of "things" in such a small area are nowhere near as complex or versatile as a similarly sized living organism.
s.yu - Sunday, August 4, 2019 - link
Well the current magnetic storage is far from the storage density of DNA, in this sense.FunBunny2 - Monday, July 29, 2019 - link
"As a single SQL query is nowhere near as parallel as Neural Networks – in many cases they are 100% sequential "hogwash. SQL, or rather the RM which it purports to implement, is embarrassingly parallel; these are set operations which care not a fig for order. the folks who write SQL engines, OTOH, are still stuck in C land. with SSD seq processing so much faster than HDD, app developers are reverting to 60s tape processing methods. good for them.
bobhumplick - Tuesday, July 30, 2019 - link
so cpus will become more gpu like and gpus will become more cpu like. you got your avx in my cuda core. no, you got your cuda core in my avx......mmmmmmbobhumplick - Tuesday, July 30, 2019 - link
intel need to get those gpus out quickAmiba Gelos - Tuesday, July 30, 2019 - link
LSTM in 2019?At least try GRU or transformer instead.
LSTM is notorious for its non-parallelizablity, skewing the result toward cpu.
Rudde - Tuesday, July 30, 2019 - link
I believe that's why they benchmarked LSTM. They benchmarked gpu stronghold CNNs to show great gpu performance and benchmarked LSTM to show great cpu performance.Amiba Gelos - Tuesday, July 30, 2019 - link
Recommendation pipeline already demonstrates the necessity of good cpus for ML.Imho benching LSTM to showcase cpu perf is misleading. It is slow, performing equally or worse than alts, and got replaced by transformer and cnn in NMT and NLP.
Heck why not wavenet? That's real world app.
I bet cpu would perform even "better" lol.
facetimeforpcappp - Tuesday, July 30, 2019 - link
A welcome will show up on their screen which they have to acknowledge to make a call.So there you go; Mac to PC, PC to iPhone, iPad to PC or PC to iPod, the alternatives are various, you need to pick one that suits your needs. Facetime has magnificent video calling quality than other best video calling applications.
https://facetimeforpcapp.com/