Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTSAP S&D
One last stop before we start with our data analytics/ML benchmarks: SAP. Enterprise Resource Planning software is the perfect example of "traditional" enterprise software.
The SAP S&D 2-Tier benchmark is probably the most real-world benchmark of all the server benchmarks done by the vendors. It is a full-blown application living on top of a heavy relational database.
We analyzed the SAP Benchmark in-depth in one of our earlier articles:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
There are lots of benchmarks result available from different vendors. To get a (more or less) apples-to-apples comparison, we limited ourselves to the "SAPS results" running on top of SQL Server 2012 Enterprise.
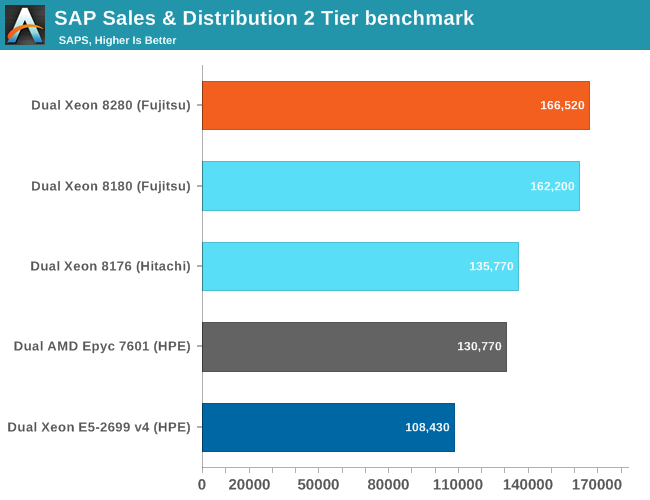
The Fujitsu benchmarks with the Xeon 8180 and 8280-based servers are as apples-to-apples as we can get: the same people who did the testing and tuning, the same OS and database. The slightly higher clocks (+200 Mhz, +8%) result in 3% higher performance. Both CPUs have 28 cores, but the 8280 has an 8% higher clockspeed, and in some senses it’s surprising that this bump in clockspeeds didn’t result in a larger performance increase. We get the impression that Cascade Lake might even be slightly slower clock per clock than Skylake, as both SPEC CPU benchmarks also increased by only three to five percent.
So in the typical enterprise stack, you’re looking at getting around 3% higher performance for the same price/energy consumption. However, AMD's much cheaper (ed: and soon to be updated) $4k EPYC 7601 is not that far behind. Considering that the EPYC is already within a margin of error of the twice as expensive 8176 (2.1 GHz, 28 cores), the 8276 with its slightly higher clockspeed (2.2 Ghz) does not significantly improve matters. Even the Xeon 8164 (26 cores at 2 GHz) offers about the same performance as the EPYC 7601, but still costs 50% more.
Considering how much progress AMD has made with the Zen 2 architecture, and the fact that the top SKUs will double the amount of cores (64 vs 32), it looks like AMD Rome will put even more pressure on Xeon sales.








56 Comments
View All Comments
Drumsticks - Monday, July 29, 2019 - link
It's an interesting, valuable take on the challenges of responding to many of the ML workloads of today with a general purpose CPU, thanks! A third party review of Intel's latest against Nvidia, and even throwing AMD in to the mix, is pretty helpful as the two companies have been going at it for a while now.Intel has a lot of stuff going that should make the next few years quite interesting. If they manage to follow through on the Nervana Coprocessor/NNP-I that Toms talked about, or on their discrete GPUs, they'll have a potent lineup. The execution definitely isn't guaranteed, especially given the software reliance these products will have, but if Intel really can manage to transform their product stack, and do it in the next few years, they'll be well on their way to competing in a much larger market, and defending their current one.
OTOH, if they fail with all of them, it'll definitely be bad news for their future. They obviously won't go bankrupt (they'll continue to be larger than AMD for the foreseeable future), but it'll be exponentially harder if not impossible to get back into those markets they missed.
JohanAnandtech - Monday, July 29, 2019 - link
Thanks! Indeed, Nervana coprocessors are indeed Intel's most promising technology in this area.p1esk - Monday, July 29, 2019 - link
No one in their right mind would think "gee, should I get CPU or GPU for my DL app?" More concerning for Intel should be the fact that I bought a Threadripper for my latest DL build.Smell This - Monday, July 29, 2019 - link
You gotta Radeon VII ?I'm thinking Intel, and to a lesser extent, nVidia, is waiting for the next shoe(s) to drop in **Big Compute** --- Cascade Lake has been left at the starting gate.
An AMD Radeon Instinct 'cluster' on a dense specialized 'chiplet' server with hundreds of CPU cores/threads is where this train is headed ...
JohanAnandtech - Monday, July 29, 2019 - link
Spinning up a GPU based instance on Amazon is much more expensive than a CPU one. So for development purposes, this question is asked.p1esk - Tuesday, July 30, 2019 - link
Then you should be answering precisely that question: which instance should I spin up? Your article does not help with that because the CPU you test is more expensive than the GPU.JohnnyClueless - Monday, July 29, 2019 - link
Really surprised Intel, and to a lesser extent AMD, are even trying to fight this battle with nVidia on these terms. It’s a lot like going to a gun fight and developing an extra sharp samurai sword rather than bringing the usual switchblade knife. The sword may be awesome, but it’s always going to be the wrong tool for the gun fight.IMO, a better approach to capture market share in DL/AI/HPC might be to develop a low core count (by 2019 standards) CPU that excelled at sequential single threaded performance. Something like 6-10 GHz. That would provide a huge and tangible boost to any workload that is at least partially single core frequency limited, and that is most DL/AI/HPC workloads. Leave the parallel computing to chips and devices designed to excel at such workloads!
Eris_Floralia - Monday, July 29, 2019 - link
Still living in early 2000s?FunBunny2 - Monday, July 29, 2019 - link
"Something like 6-10 GHz. "IIRC, all the chip tried to get near that, but couldn't. it's not nice to fool Mother Nature.
Santoval - Monday, July 29, 2019 - link
"Something like 6-10 GHz."Google "Dennard scaling" (which ended in ~2005) to find out why this is impossible, at least with silicon based MOSFET transistors (including the GAA-FET based ones of the next decade). Wikipedia has a very informative page with multiple links to various sources for even more. The gist of the end of Dennard scaling is that single core clocks higher than ~5 GHz (at a reasonable TDP of up to ~100W) are explicitly forbidden at *any* node.
When Dennard scaling ended -in combination with the slowing down of Moore's Law- there was another, related consequence : Koomey's law started to slow down. Koomey's law is all about power efficiency, i.e. how many computations you can extract from each Wh or kWh.
Before the early 2000s the number of computations per x unit of energy doubled on average every 1.57 years. In 2011 Koomey himself re-evaluated his law and got an average doubling of computations every 2.6 years for the previous decade, a substantial collapse of power efficiency. Since 2011 Koomey's law has obviously slowed down further.
To make a long story short Moore's law puts a limit to the number of transistors we can fit in each mm^2, and that limit is not too far away. Dennard scaling once allowed us to raise clocks with each new node at the same TDP, and this is ancient history in computing terms. Koomey's law, finally, puts a limit to the power efficiency of our CPUs/GPUs, and this continues to slow down due to the slowing down of Moore's Law (when Moore's Law ends Koomey's law will also end, thus all three fundamental computing laws will be "dead").
Unless we ditch silicon (and even CMOS transistors, if required) and adopt a new computing paradigm we will have neither 6 - 10 GHz clocked CPUs in a couple of decades nor will we able to speed up CPUs, GPUs and computers at all.