Intel's Architecture Day 2018: The Future of Core, Intel GPUs, 10nm, and Hybrid x86
by Dr. Ian Cutress on December 12, 2018 9:00 AM EST- Posted in
- CPUs
- Memory
- Intel
- GPUs
- DRAM
- Architecture
- Microarchitecture
- Xe
Changing How Chips are Made: 3D Packaging with FOVEROS
Anyone who has followed any amount of chip design in semiconductors should well-aware that most of the CPUs and SoCs in production today are based on monolithic dies – single pieces of silicon the have all what is needed inside, before being placed on a package and into a system. While rarer, there are multi-chip packages, were multiple chips go in one package with a shared connection. Beyond this we have seen interposers or embedded bridges designed to bring different chips together with high-speed interconnects. Now Intel is ready to bring 3D stacking into the mass market.
One of the biggest challenges in modern chip design is minimizing die area. A small die decreases costs – typically power too – and can make it easier to implement in a system. When it comes down to extracting performance however, we are at the limits of scale – one of the downsides of big monolithic dies, or even multi-chip packages, is that memory is too far away. Intel today is now ready to talk about its Foveros technology, which involves active interposers in small form factors to bring differentiated technologies together.
Foveros: It’s Greek for Awesome, Apparently
The way Raja introduced this technology started with discussing process technologies. Intel has for many years/decades been focused on high performance process nodes, trying to extract as much as possible from its high-performance cores. Alongside this, Intel also runs an IO optimized process node on a similar cadence but more suitable for PCH or SoC-type functions.
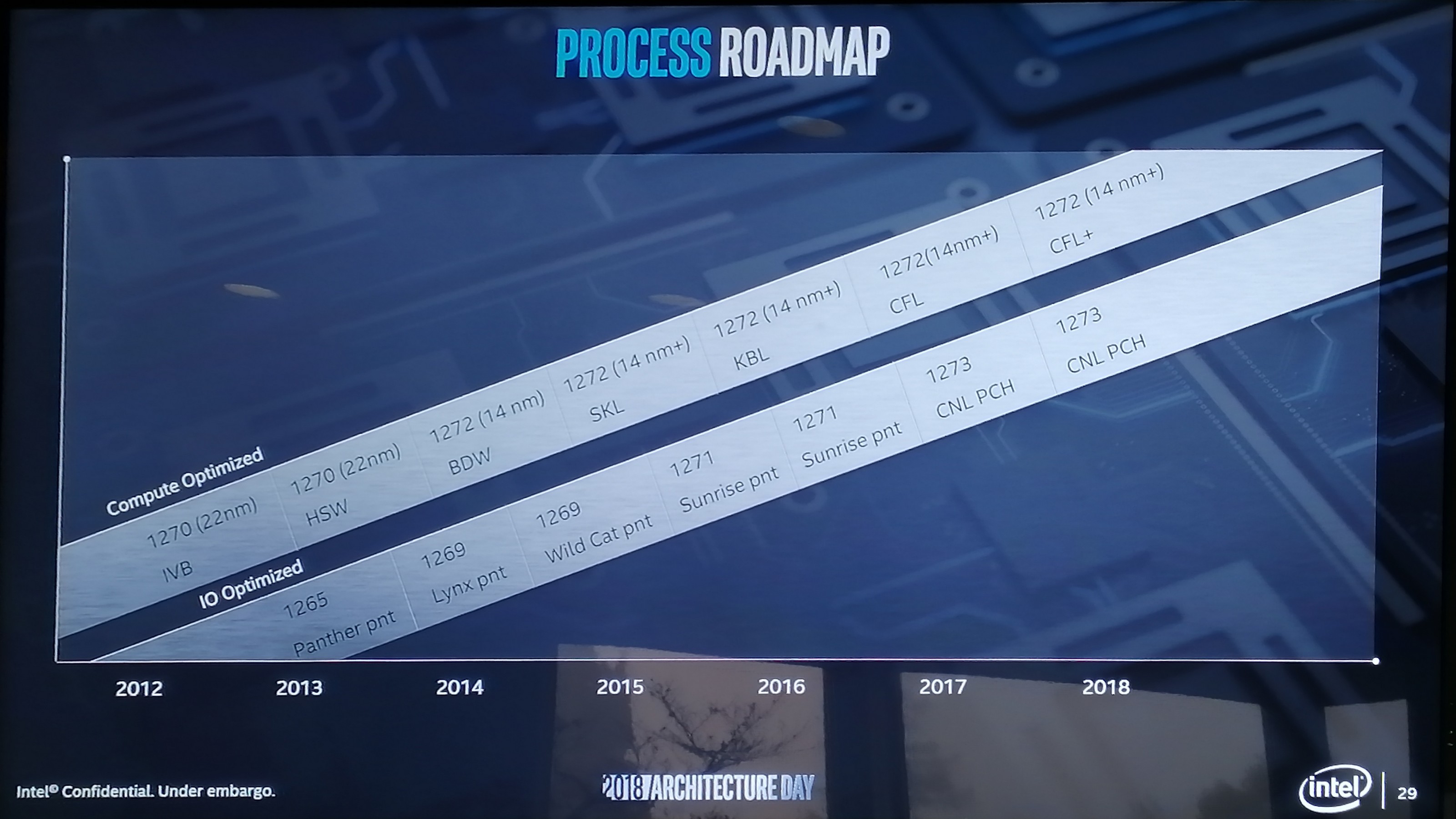
The 126x and 127x are the internal numbering systems for Intel’s process node technologies, although they don’t differentiate between BKM updates for the "+" node variants it turns out. But the point here is that Intel already knows that it needs certain process optimizations in place depending on the type of transistors, performance, and power needed. Going forward, Intel is going to be expanding its node base out so it can cover more power and performance points.

So for this example, Raja pulled out the current set of process technologies for 2019. For a manufacturing process, compute has the 1274 process on 10nm, IO has the 1273 process (14nm), while this new special Foveros technology is under P1222. Alongside the manufacturing, Intel will be working on optimizations focusing on the compute aspects of the manufacturing node. There will also be a set of developments for future node technologies, and the final column shows that Intel has path-finding research to look into future technologies and determine what capabilities will be possible on future designs. This sounds pretty much what a company like Intel should be doing, so no argument from me so far. The goal here is that each type of transistor use case can be different, and there isn’t a one-size fits all approach.

One way to assist with this is through chiplets and packaging. By picking the best transistor for the job in each case, whether it is CPU, GPU, IO, FPGA, RF, or anything else, with the correct packaging, it can be put together to get the best optimizations available.

So here’s where Foveros fits in. Foveros is Intel’s new active interposer technology designed as a step above its own EMIB designs for small form-factor implementations, or those with extreme memory bandwidth requirements. For these designs the power per bit of data transferred is super low, however the packaging technology has to deal with the decreased bump pitch, the increased bump density, and also the chip stacking technology. Intel says that Foveros is ready for prime time, and they can produce it at scale.

So this Foveros ‘3D’ packaging just sounds like a silicon interposer, such as what we’ve seen on AMD’s Fiji or NVIDIA’s high-end datacenter GPUs. However Intel is going above what those products are doing by actually making the interposer part of the design. The interposer contains the through-silicon vias and traces required to bring power and data to the chips on top, but the interposer also carries the PCH or IO of the platform. It is, in effect, a fully working PCH, but with vias to allow chips to be connected on top.

The first iteration of this technology is less complicated that the slide above, just using a set of CPU cores attached to the PCH below, but the idea is that a large interposer can have select functions on it and those can be removed from the chips above to save space. This also lets Intel use the different transistor types in different chips – the example we were given uses an interposer built on the 22FFL process node, with a 10nm set of CPUs on the top die. Above this, DRAM is provided in a POP package. Sounds cool, right?
In actual fact, Intel had a Foveros chip or two working in the demo area. These, Intel explained, were hybrid x86 designs that combined a single big Core with four smaller Atom cores on the same 10nm piece of silicon. I’m sure I’ve heard about big.Little before, but I was shocked that Intel is actually going to do it! We managed to take a photo of the block diagram, which Intel removed from its slide deck before sending it out to the press after the presentations. All details on the next page.








148 Comments
View All Comments
zodiacfml - Thursday, December 13, 2018 - link
YESRaqia - Thursday, December 13, 2018 - link
For ultra-mobile, not only are battery/power/heat issues but supply is one as well due to Intel being locked down to their own manufacturing division. On top of that, they have a lock on x86 by not licensing to any competitors but AMD, who despite competitive stretches inevitably stumbles (either due to themselves or Intel's non-engineering financial efforts) and leaves the industry with dry spells of performance improvements. Intel's gross margins on their chips remain >60% as a result whereas ARM SoCs even after licensing is closer to 20-30%.Raqia - Thursday, December 13, 2018 - link
Keller declared that the technology is in its infancy, and feature wise the 2019 version of the Atom simply won't be competitive with leading ARM SoCs like the 8cx. The slowness you refer to only occurs when running native 32 bit x86 code on the WOW emulation layer, but the value of this feature is mostly in the compatibility being there at all. If performance and compatibility of legacy code matters to you then certainly Windows on Arm isn't suitable. However, it will matter even less now with the new native compilation tools and ports of important sub platforms like Chromium.29a - Thursday, December 13, 2018 - link
"Windows on ARM is horribly slow and therefore shitty."Sounds a lot like Windows on Atom.
MonkeyPaw - Saturday, December 15, 2018 - link
I’m betting Apple wanted one for MacBook Air, or maybe MS for Surface Go. It would be the right amount of performance for both devices, an both companies would have the clout to get it done. I’d lean toward Apple because the GPU is pretty big.Kevin G - Wednesday, December 12, 2018 - link
Typo:"a physical address space up to 52 bits. This means, according to Intel, that the server processors could theoretically support 4 TB of memory per socket."
That should be petabytes instead of terabytes. The limit is for an entire system, not per socket as additional sockets will not grant any additional capacity.
gamerk2 - Thursday, December 13, 2018 - link
NUMA systems could potentially be per-socket rather then OS wide.HStewart - Wednesday, December 12, 2018 - link
It sounds like Intel has been working on increasing performance in two ways1. 7nm change for the future - because of limitations found with 10nm
2. 10nm enhance for corrections for performance of issues with Cannon Lake
But most importantly, architexture improvements like faster single thread execution and new instructions and multi-core improvements will in long term significantly improve performance
ishould - Wednesday, December 12, 2018 - link
Forgive me if I take 2 metric tons of salt with any roadmaps Intel provides these days. They haven't exactly had the most accurate timelines as of late (past four years)HStewart - Wednesday, December 12, 2018 - link
It appears they realize that and coming out with document to indicated they have made corrections - this is better than not knowing what they are planning - or as some AMD Fans would like to believe that they lost the battle.