Intel's 10nm Cannon Lake and Core i3-8121U Deep Dive Review
by Ian Cutress on January 25, 2019 10:30 AM ESTStock CPU Performance: System Tests
Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3D model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.
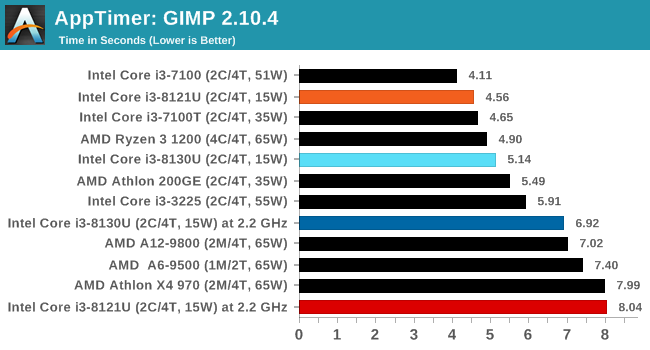
The CNL platform here does particularly well in loading software, which correlates with what I felt actually using the system - it felt faster than some Core i7 notebooks I've used. This might be down to the GPU acting on the display however. But it doesn't explain the extreme regression when we fix the clock speed.
FCAT: Image Processing
The FCAT software was developed to help detect microstuttering, dropped frames, and run frames in graphics benchmarks when two accelerators were paired together to render a scene. Due to game engines and graphics drivers, not all GPU combinations performed ideally, which led to this software fixing colors to each rendered frame and dynamic raw recording of the data using a video capture device.

The FCAT software takes that recorded video, which in our case is 90 seconds of a 1440p run of Rise of the Tomb Raider, and processes that color data into frame time data so the system can plot an ‘observed’ frame rate, and correlate that to the power consumption of the accelerators. This test, by virtue of how quickly it was put together, is single threaded. We run the process and report the time to completion.
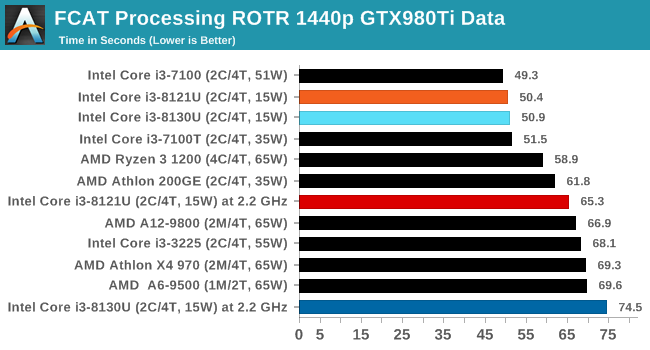
At stock speeds, both of our CNL and KBL chips score within half a second of each other. At fixed frequency, CNL comes out slightly ahead.
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
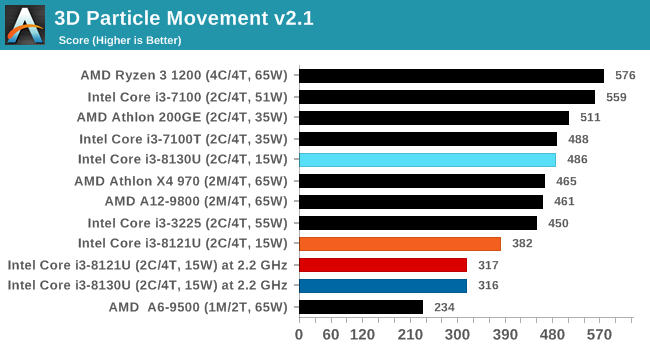
When AVX isn't on show, the KBL processor takes a lead, however it is worth nothing that at fixed frequency both CNL and KBL perform essentially the same.
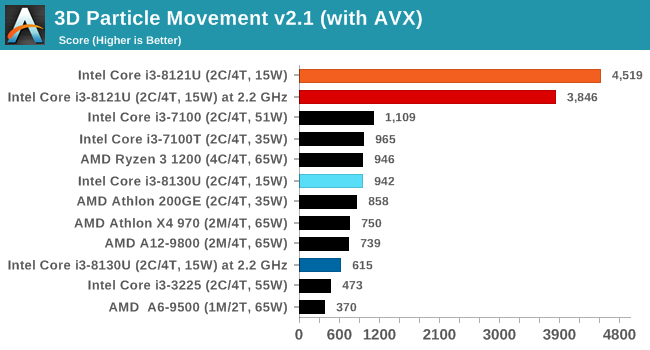
When we crank on the AVX2 and AVX512, there is no stopping the Cannon Lake chip here. At a score of 4519, it beats a full 18-core Core i9-7980XE processor running in non-AVX mode which scores 4185. That's insane. Truly a big plus in Cannon Lake's favor.
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/

Both CPUs perform roughly the same at fixed frequency, however KBL has a slight lead at stock frequencies, likely due to its extra 200 MHz and ability to keep that frequency regardless of what's running in the background.
DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.

Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
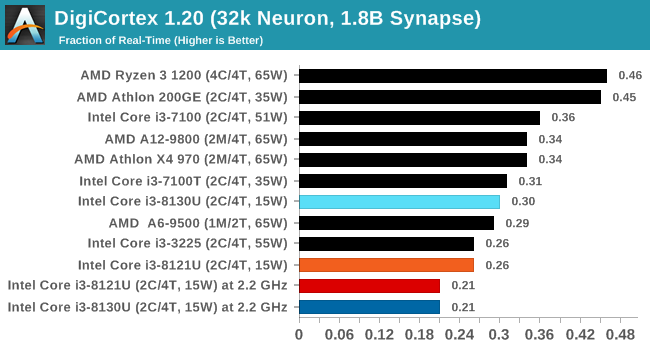
At a fixed frequency, both processors perform the same, but at stock frequencies the lower DRAM latency means that the Cannon Lake CPU only improves a little bit, whereas the Kaby Lake adds another 50% performance.
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
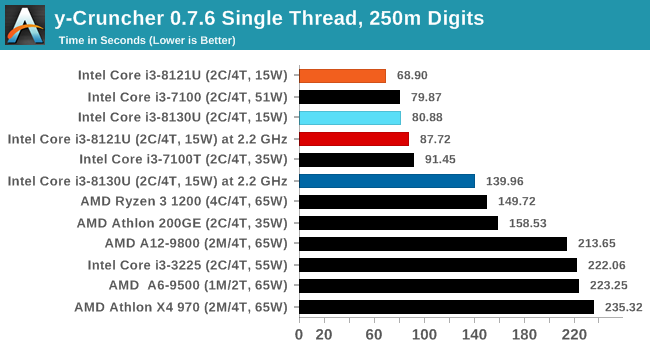
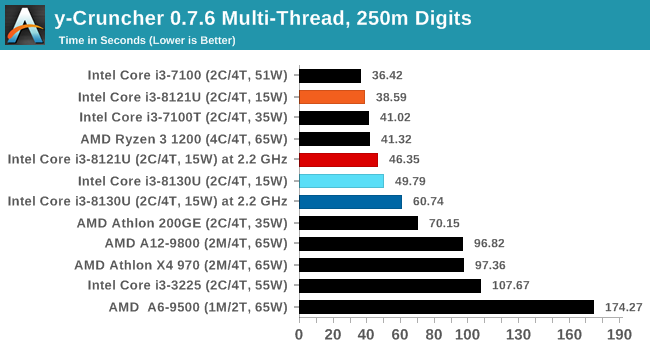
y-Cruncher is another AVX-512 test, and in both ST and MT modes, Cannon Lake wins. Interestingly in MT mode, CNL at 2.2 GHz scores better than KBL at stock frequencies.
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

KBL takes a big lead here at stock frequencies, while at fixed frequencies the results are similar. We might be coming up against the power difference here - the KBL system has a higher steady state power limit.








129 Comments
View All Comments
0ldman79 - Friday, January 25, 2019 - link
This whole situation begs the question, what could Intel have gotten out of 65nm, 32nm, 22nm, etc, had they run it for five generations.I wonder if they'll do similarly on the 10nm process, punt the first time or two then knock it out of the park. Skylake was a beautiful success. Maybe Sunny Cove will be the same for 10nm.
StrangerGuy - Friday, January 25, 2019 - link
The point is Intel now needs better uarch designers lot more than process designers. Yes 10nm improvements is hard work and an interesting read...but for users they ultimately only care about end performance and perf/$, not die sizes, transistors/mm2 or manufacturing margins. If Zen 2 blows the doors off CFL would anybody even care about about Intel's process advantage? Hell not.KOneJ - Sunday, January 27, 2019 - link
Doubt this is even an "if" at this point. Curious to see if *Cove cores can keep Zen 4 and later from running away too much. Only time will tell, but Intel bringing in guys like Keller can't possibly be a bad thing. And in spite of their disastrous former attempts at building a dGPU, I fully expect Intel to make it happen this go around.eva02langley - Sunday, January 27, 2019 - link
The problem is, do you believe 7nm would be any different? Unless they implement EUV directly, I don't see it. Intel will be force, like AMD, to go fab less because their node will not be better than the competition. To add to it, it is most likely be behind in time to.zodiacfml - Saturday, January 26, 2019 - link
Great job again though it doesn't warrant it for this Intel junk. Looks like they're paying Lenovo just to use Cannon lake, usable chips that came from tuning manufacturing.The performance is where I expected it to be.
I still stand to my theory that Intel is reluctant to spend, leaving their engineers stressing if they can produce 10nm products without new equipment.
Anyways, it is a dead horse. AMD will be all the rage for 2019.
KOneJ - Sunday, January 27, 2019 - link
"Intel is reluctant to spend"To the contrary: throwing money at the problem is exactly what they're doing. Have you tracked their CAPEX these past few years?
"AMD will be all the rage for 2019."
I think that's basically a given.
zodiacfml - Sunday, January 27, 2019 - link
The reports were pretty vague and I don't remember them spending substantial money except the news that they're spending for more capacity on 14nm.AMD is pretty lukewarm for me last year. I'm certain that this year will be a lot stronger for AMD until Intel and Nvidia starts taking their customers more seriously.
KOneJ - Sunday, January 27, 2019 - link
Even for a company Intel's size, spending north of $12B a year isn't penny-pinching. I know their revenue and margins are massive, but their failings haven't been a lack of spending since SB. They've been progressively spending more than ever.YoloPascual - Saturday, January 26, 2019 - link
bUt 10nm iNtEL iS bEtTeR tHaN 7nm TSMC riGhT?KOneJ - Sunday, January 27, 2019 - link
Shouldn't your alias be yOlOpAsCuAl, wannabe troll?