Intel's 10nm Cannon Lake and Core i3-8121U Deep Dive Review
by Ian Cutress on January 25, 2019 10:30 AM ESTStock CPU Performance: Legacy Tests
We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
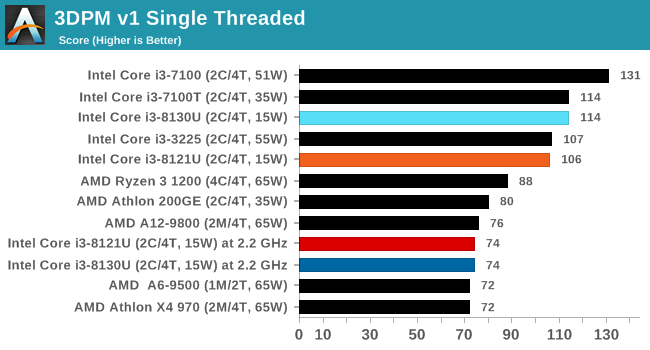
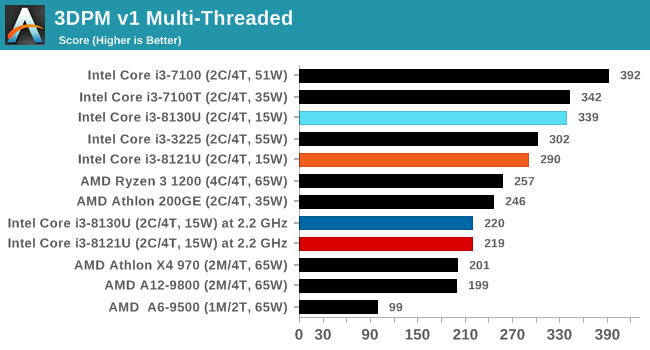
3DPM v1: Naïve Code Variant of 3DPM v2.1
The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes).
In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures.
3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
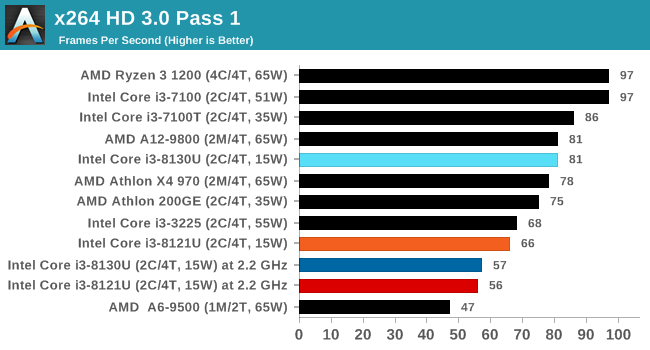
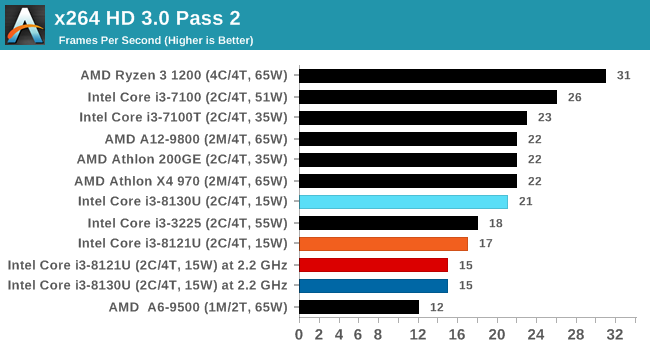
x264 HD 3.0: Older Transcode Test
This transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.








129 Comments
View All Comments
eva02langley - Sunday, January 27, 2019 - link
Even better...https://youtu.be/osSMJRyxG0k?t=1220
AntonErtl - Sunday, January 27, 2019 - link
Great Article! The title is a bit misleading given that it is much more than just a review. I found the historical perspective of the Intel processes most interesting: Other reporting often just reports on whatever comes out of the PR department of some company, and leaves the readers to compare for themselves with other reports; better reporting highlights some of the contradictions; but rarely do we se such a pervasive overview.The 8121U would be interesting to me to allow playing with AVX512, but the NUC is too expensive for me for that purpose, and I can wait until AMD or Intel provide it in a package with better value for money.
RamIt - Sunday, January 27, 2019 - link
Need gaming benches. This would make a great cs:s laptop for my daughter to game with me on.Byte - Monday, January 28, 2019 - link
Cannonlake, 2019's Broadwell.f4tali - Monday, January 28, 2019 - link
I can't believe I read this whole review from start to finish...And all the comments...
And let it sink in for over 24hrs...
But somehow my main takeaway is that 10nm is Intel's biggest graphics snafu yet.
(Well THAT and the fact you guys only have one Steam account!)
;)
NikosD - Monday, January 28, 2019 - link
@Ian CutressGreat article, it's going to become all-time classic and kudos for mentioning semiaccurate and Charlie for his work and inside information (and guts)
But really, how many days, weeks or even months did it take to finish it ?
bfonnes - Monday, January 28, 2019 - link
RIP IntelCharonPDX - Monday, January 28, 2019 - link
Insane to think that there have been as many 14nm "generations" as there were "Core architecture" generations before 14nm.ngazi - Tuesday, January 29, 2019 - link
Windows is snappy because there is no graphics switching. Any machine with the integrated graphics completely off is snappier.Catalina588 - Wednesday, January 30, 2019 - link
@Ian, This was a valuable article and it is clipped to Evernote. Thanks!Without becoming Seeking Alpha, you could add another dimension or two to the history and future of 10nm: cost per transistor and amortizing R&D costs. At Intel's November 2013 investor meeting, William Holt strongly argued that Intel would deliver the lowest cost per transistor (slide 13). Then-CFO Stacey Smith and other execs also touted this line for many quarters. But as your article points out, poor yields and added processing steps make 10nm a more expensive product than the 14nm++ we see today. How will that get sold and can Intel improve the margins over the life of 10nm?
Then there's amortizing the R&D costs. Intel has two independent design teams in Oregon and Israel. Each team in the good-old tick-tock days used to own a two-year process node and new microarchitecture. The costs for two teams over five-plus years without 10nm mainstream products yet is huge--likely hundreds of millions of dollars. My understanding is that Intel, under general accounting rules, has to write off the R&D expense over the useful life of the 10nm node, basically on a per chip basis. Did Intel start amortizing 10nm R&D with the "revenue" for Cannon Lake starting in 2017, or is all of the accrued R&D yet to hit the income statement? Wish I knew.
Anyway, it sure looks to me like we'll be looking back at 10nm in the mid-2020s as a ten-year lifecycle. A big comedown from a two-year TickTock cycle.