Intel's 10nm Cannon Lake and Core i3-8121U Deep Dive Review
by Ian Cutress on January 25, 2019 10:30 AM ESTStock CPU Performance: System Tests
Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3D model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.
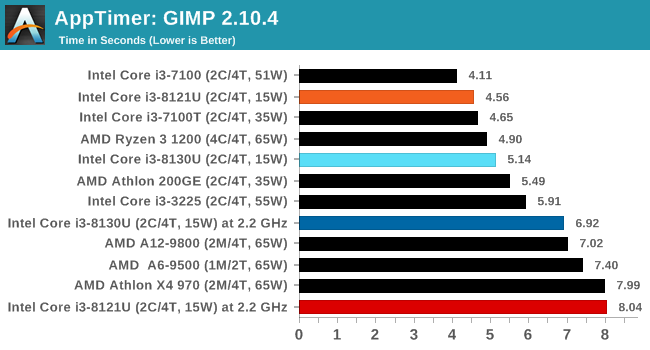
The CNL platform here does particularly well in loading software, which correlates with what I felt actually using the system - it felt faster than some Core i7 notebooks I've used. This might be down to the GPU acting on the display however. But it doesn't explain the extreme regression when we fix the clock speed.
FCAT: Image Processing
The FCAT software was developed to help detect microstuttering, dropped frames, and run frames in graphics benchmarks when two accelerators were paired together to render a scene. Due to game engines and graphics drivers, not all GPU combinations performed ideally, which led to this software fixing colors to each rendered frame and dynamic raw recording of the data using a video capture device.

The FCAT software takes that recorded video, which in our case is 90 seconds of a 1440p run of Rise of the Tomb Raider, and processes that color data into frame time data so the system can plot an ‘observed’ frame rate, and correlate that to the power consumption of the accelerators. This test, by virtue of how quickly it was put together, is single threaded. We run the process and report the time to completion.
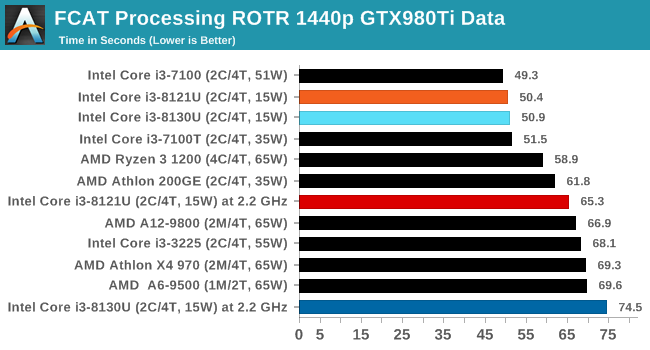
At stock speeds, both of our CNL and KBL chips score within half a second of each other. At fixed frequency, CNL comes out slightly ahead.
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
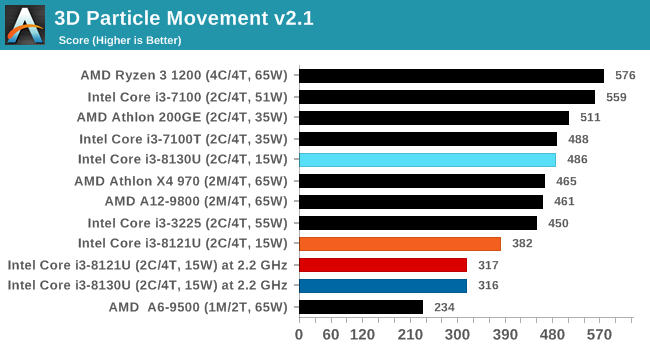
When AVX isn't on show, the KBL processor takes a lead, however it is worth nothing that at fixed frequency both CNL and KBL perform essentially the same.
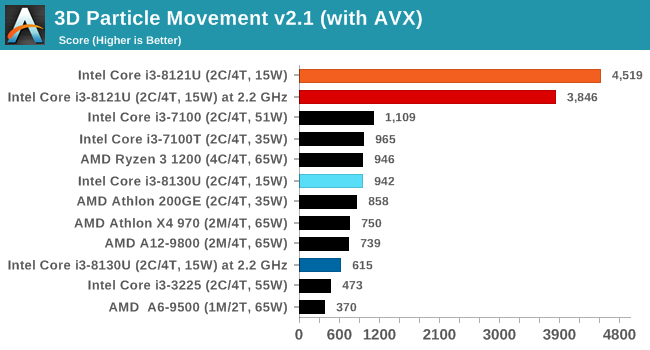
When we crank on the AVX2 and AVX512, there is no stopping the Cannon Lake chip here. At a score of 4519, it beats a full 18-core Core i9-7980XE processor running in non-AVX mode which scores 4185. That's insane. Truly a big plus in Cannon Lake's favor.
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/

Both CPUs perform roughly the same at fixed frequency, however KBL has a slight lead at stock frequencies, likely due to its extra 200 MHz and ability to keep that frequency regardless of what's running in the background.
DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.

Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
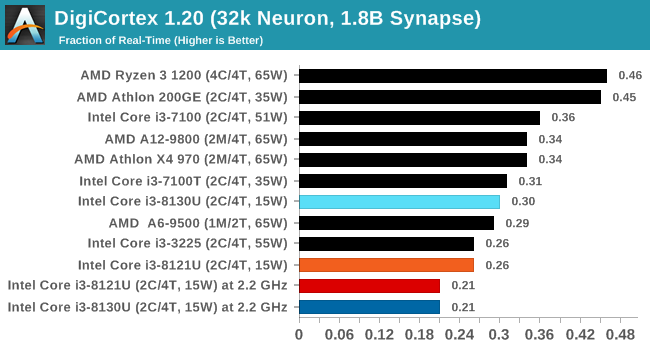
At a fixed frequency, both processors perform the same, but at stock frequencies the lower DRAM latency means that the Cannon Lake CPU only improves a little bit, whereas the Kaby Lake adds another 50% performance.
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
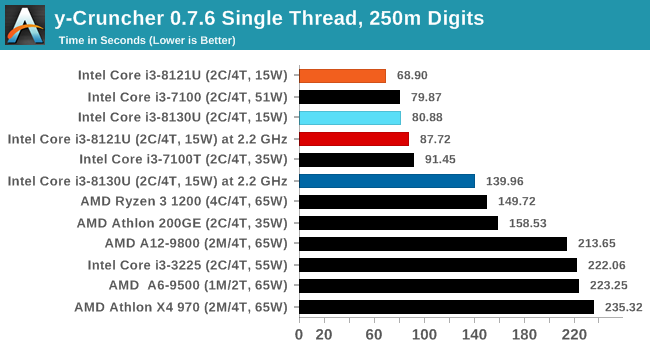
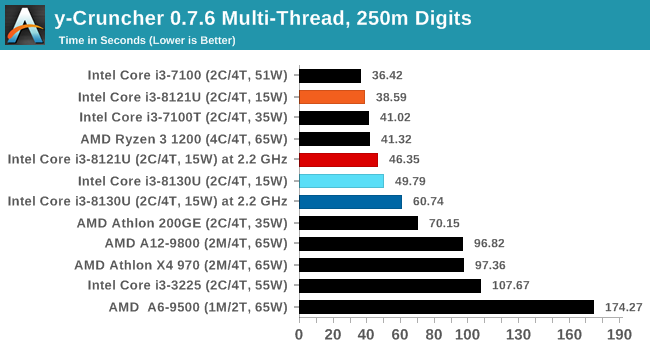
y-Cruncher is another AVX-512 test, and in both ST and MT modes, Cannon Lake wins. Interestingly in MT mode, CNL at 2.2 GHz scores better than KBL at stock frequencies.
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

KBL takes a big lead here at stock frequencies, while at fixed frequencies the results are similar. We might be coming up against the power difference here - the KBL system has a higher steady state power limit.








129 Comments
View All Comments
yeeeeman - Saturday, January 26, 2019 - link
As someone said it earlier in this thread, I think we miss opportunities when moving to a new process every two years. The mishap that Intel had just showed us how much better a process can become if you give the time to your engineers. 14nm started late, with some low clocked parts. We had some Broadwell chips that ran at 3.3 base. Then, Skylake came and the 6700k brought 4ghz at quite high power. Then, the 7700k came and another tweak to the process improved clocks, so we now got 4.7 GHz boost. After this, things moved up in core counts (which should've happen a long time ago, but with competition...) and we got 8700k and now 9900k with turbo to 5ghz. Until now, only 32nm with Sandy Bridge came close to 5ghz mark. Now, with a lot of time to tweak, they have become so confident in the 14nm process that they released a 5ghz stock cpu. Financials say the true story. Even if we cry about 10nm, truth is that things can move forward without a new process. It is cheaper actually to prolong the life of a certain process and if they can add enough improvements from generation to generation, they can afford to launch new process once every 4-5 years.Dodozoid - Saturday, January 26, 2019 - link
Indeed, we probably have to get used to a lot of +++ processes. During the architecture day, the new Intel people (old AMD people) mentioned they are decoupling the architecture from the process. That means they can make progress other than pushing clocks on the same core over and over, but IPC as well...KOneJ - Sunday, January 27, 2019 - link
Unfortunately, SB-derivatives seem to be needing a significant overhaul. "tocks" of late haven't exactly brought meaningful IPC gains. Hopefully deeper and wider *Cove designs are a step in the right direction. I just don't like that Intel seems to be taking an approach not dissimilar to the Pentium 4 the last time AMD reared its head. Only this time, a major departure in micro-architecture and steady process advantage isn't in the wings. Even with the *Coves, I think AMD may be able to build enough steam to solidly overtake them. There's no reason that Zen 4 and on couldn't go deeper and wider too, especially looking at power consumption on the front and back ends of the Zen core versus the uncore mesh. I think Zen derivatives currently will try the wider first. It actually might make the high core-count parts significantly more power efficient. Also could easily scale better than post-SB did if Agner Fog's analysis is anything to go by. Multiple CPU die masks and uncore topologies incoming? Wouldn't surprise me.dgingeri - Saturday, January 26, 2019 - link
Well, yeah, they can be improved upon over time, but that doesn't cut the production costs like a process reduction does. improving the process can increase yields and increase performance, but only by a limited percent. A process reduction increases the number of chips from a wafer by a much higher amount, even if there are more defects.Well, that was the way it worked up until the 14nm process.
With 10nm at Intel, they had far too many defects, and the process failed to give the returns they wanted for quite a while. That had as much to do with the quality of the wafers before production as it did the production process itself. They had to push the wafer producers to higher levels of purity in order to fix that. I'm fairly sure TSMC would have had the same issues with their 7nm, but Intel had already pushed the wafer production to higher levels of purity because of their problems, so TSMC was able to take a couple extra steps ahead because of that.
These days, we're going to see each step smaller take longer and longer to get right, because of these same hurdles. As things get smaller, impurities will have a higher and higher impact on production. We may not get as far as some are hoping, simply because we can't get silicon as pure as necessary.
name99 - Saturday, January 26, 2019 - link
"Another takeaway is that after not saying much about 10nm for a while, Intel was opening up. However, the company very quickly became quiet again."The history page is great. But I have to wonder if the ultimate conclusion is that the best thing, for both Intel and the world, is that they STICK to the STFU strategy? And that journalist stick to enforcing it.
One thing that's incredibly clear from all this is that Intel are utterly lousy at forecasting the future. Maybe it's deliberate lies, maybe it's just extreme optimism, maybe it's some sort of institutional pathology that prevents bad news flowing upward?
Regardless, an Intel prediction for beyond maybe two years seems to be utterly worthless. Which raises the question -- why bother asking for them, and why bother printing them?
Look at that collection of technologies from the 2010 slide that are supposed to be delivered over the next nine years. We got Computational Lithography, and that's about it. CErtainly no III-V or Germanium or Nanowires. Interconnects (Foveros and EMIB?) well, yeah, in about as real a form as 10nm. 3D refers to what? Die stacking? or 3D structures? Either way nothing beyond the already extant FinFETs. Dense Memory? Well yeah, there's Optane, but that's not what they had in mind at the time, and Optane DIMMs are still crazy specialized. Optical Interconnect? Well occasional mutterings about on-die photonics, but nothing serious yet.
Now on the one hand you could say that prediction is hard. How much better would IBM, or TSMC, or Samsung, have done? On the other hand (and this is the point) those companies DON'T DO THIS! They don't make fools of themselves by engaging in wild claims about what they will be delivering in five years. Even when they do discuss the future, it's in careful measured tones, not this sort of "ha ha, we have <crazy tech> already working and all our idiot competitors are four years behind" asinine behavior.
I suspect we'd all be better off if every tech outlet made a commitment that they won't publish or discuss any Intel claims regarding more than two years from now. If you're willing to do that, you might as well just call yourself "Home of Free Intel's advertising". Because it's clear that's ALL these claims are. They are not useful indications of the future. They're merely mini-Intel ads intended to make their competition look bad, and with ZERO grounding in reality beyond that goal.
KOneJ - Sunday, January 27, 2019 - link
While you're correct that the media is ignorantly doing just that for the most part, at least this article provides context in what Intel is trying to do in obfuscating the numbers versus TSMC and Samsung who haven't stumbled the same way. Some of the Foveros "magic" is certainly not being knocked-down enough when people don't understand what it's intended to do. 2.5D, 3D, MCMs, and TSVs all overlap but cover different issues. I blame the uneducated reader more than anything. Good material is out there, and critical analysis between the lines is under-present. "Silicon photonics" was a big catch-phrase in calls a few years ago, but quiet now. Hype, engineering, and execution are all muddied by PR crap. Ian is however due credit for at least showing meaningful numbers. It's more in the readers hands now. Your last remarks really aren't fair to this article, even if they bear a certain degree of merit in general. Sometimes lies are needed to help others understand the truth though...HStewart - Saturday, January 26, 2019 - link
I believe that this Cannon is get AVX 512 out to developers. What would be interesting if possible is for Intel to release Covey Lake on both 14nm and new 10nm. One thing I would expect that Covey Lake will significant speed increase compare to current 14nm chips even if on 14nm and the 10nm will be also increase but combine Covey Lake and new 10nm+. should be quite amazing.One test that I am not sure is benchmark that runs in both AVX2 and AVX 512 and see the difference. There must be reason why Intel is doing the change.
KOneJ - Sunday, January 27, 2019 - link
Cheap Cannon Lake is not designed to get AVX512 into dev hands. That's the dumbest thing ever. And "Covey Lake"? Please read the article before commenting. There are a few good blog posts and whitepapers out there analyzing and detailing SIMD across AVX varieties. For most things, AVX512 isn't as big a deal as earlier SIMDs were. It has some specialized uses as it is novel, but vectoring code and optimizing compilers to maturity is slow and difficult. There are fewer quality code slingers and devs out there than you would expect. Comp sci has become littered with an unfortunate abundance of cheap low-quality talent.HStewart - Sunday, January 27, 2019 - link
Ok for the misunderstood people about AVX 512 - which appear to be 2x fast AVX2https://www.prowesscorp.com/what-is-intel-avx-512-...
yes it going to take a while people user AVX 512 - but just think about it twice the bits - I was like you not believe 512 but instead 64 bit would make in days of early 64 bit - thinking primary that is will make program largers and not necessary. As developer for 3 decades one thing I have send that 64 bit has done is make developer lazy - more memory less to worry about in algorithms for going to large arrays.
As for Sunny Cove, it logical with more units in the chip - it is going to make a difference - of course Cannon Lake does not have Sunny Cove - so it does not count. Big difference will be seen when Covey Lake cpus come out what the difference it be like with Cannon Lake - and even Kaby Lake and assoicated commetitors chips
HStewart - Sunday, January 27, 2019 - link
One thing on Covey Lake and upcoming 7nm from Intel, it is no doubt that it designers made a mistake with Cannon Lake's 10nm - Intel realizes that and has created new fabs and also new design architexture - there is no real reason for Intel to release a Cannon Lake - but it good to see that next generation is just more that Node change - it includes the Covey Lake architexture change.